
mysql レプリケーション 概要
MySQLの最大の特徴はreplication ( レプリケーション )です。読取専用のレプリカを多数作成し、ディスクアクセスが発生しないように大量の読取処理を実現するのが、MySQLの基本的な考え方です。このページでは、replication ( レプリケーション) に関する設定練習ができるよう、一台のOS上でmysqld_multiを用いてreplication ( レプリケーション) 環境を構築する方法を説明します。
mysqld_multiは1つのOS上で複数のmysqld (MySQLサーバ) プロセスを起動させる手法です。具体的な構築方法は、”mysqld_multiの設定方法“を参照下さい。
mysql レプリケーション 環境準備
mysql レプリケーション 環境準備 – 構成説明
mysqld_multiを用いて4つのmysqld ( MySQL サーバ ) プロセスを起動します。4つのmysqld ( MySQL サーバ ) は、以下のようなreplication ( レプリケーション ) 構成を取るように構築します。
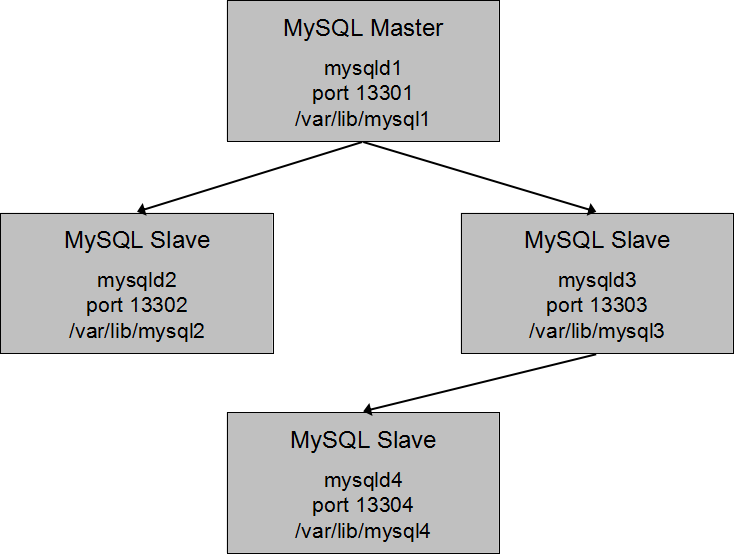
このマルチプロセス環境を実現する/etc/my.cnfの設定は以下のようになります。
[mysqld_multi] mysqld=/usr/bin/mysqld_safe mysqladmin=/usr/bin/mysqladmin [mysqld1] datadir=/var/lib/mysql1 socket=/tmp/mysql1.sock tmpdir=/var/tmp/mysql1 port=13301 [mysqld2] datadir=/var/lib/mysql2 socket=/tmp/mysql2.sock tmpdir=/var/tmp/mysql2 port=13302 [mysqld3] datadir=/var/lib/mysql3 socket=/tmp/mysql3.sock tmpdir=/var/tmp/mysql3 port=13303 [mysqld4] datadir=/var/lib/mysql4 socket=/tmp/mysql4.sock tmpdir=/var/tmp/mysql4 port=13304
mysql レプリケーション 環境準備 – ディレクトリ作成
データディレクトリを作成し、初期状態のinnodbを作成します。innodbを作成するには、以下のようにmysql_install_dbというperlスクリプトを利用します。
# mysql_install_db --datadir=/var/lib/mysql1
# mysql_install_db --datadir=/var/lib/mysql2
# mysql_install_db --datadir=/var/lib/mysql3
# mysql_install_db --datadir=/var/lib/mysql4
# chown mysql:mysql -R /var/lib/mysql{1,2,3,4}
MySQL用の一時ディレクトリを作成します。
# mkdir /var/tmp/mysql{1,2,3,4}
# chown mysql:mysql /var/tmp/mysql{1,2,3,4}
mysql レプリケーション 基本設定
mysql レプリケーション 基本設定 – binary log, relay logの事前説明
MySQLのreplication (レプリケーション)を設定するには、以下4つのキーワードを抑える事が重要です。
- Binary log ( バイナリログ)
- Relay log ( リレーログ )
- I/O thread
- SQL thread
これら4つのキーワードについて、簡単なMySQL replication (レプリケーション)の動作を図示すると以下のようになります。

MySQL replication ( レプリケーション ) の処理の概要を説明すると次のようになります。
- Masterサーバに書き込まれた変更処理をBinary logに書き出します。
- SlaveサーバのI/O threadはBinary logを読み取り、Relay logに変更内容を書き出します。
- SlaveサーバのSQL threadはRelay logを読み取り、読み取った内容をデータベースに反映させます。
mysql レプリケーション 基本設定 – binary log 設定
MySQLはデフォルトでbinary log (バイナリログ)の出力は無効になっています。従って、replication (レプリケーション)を行なうには、binary log (バイナリログ)の出力を有効にしなければなりません。[mysqld]セクションにlog-binを加筆します。/etc/my.cnfの設定例は以下の通りです。
[mysqld] log-bin [mysqld_multi] mysqld=/usr/bin/mysqld_safe mysqladmin=/usr/bin/mysqladmin [mysqld1] datadir=/var/lib/mysql1 socket=/tmp/mysql1.sock tmpdir=/var/tmp/mysql1 port=13301 <omitted>
binary log (バイナリログ) , relay log (リレーログ) のデフォルトのファイル名は、<hostname>-bin, <hostname>-relay-binです。サーバによってファイル名が異なるのは、手順書を書いたり処理を自動化したりする時に不都合です。
replication ( レプリケーション ) を行なう最小限の設定は”log-bin”の一行ですが、ログファイルを固定の名前にし運用しやすいようにしておくと良いでしょう。/etc/my.cnfの設定例は以下の通りです。
[mysqld] log-bin=mysql-bin relay-log=mysql-relay [mysqld_multi] mysqld=/usr/bin/mysqld_safe mysqladmin=/usr/bin/mysqladmin [mysqld1] datadir=/var/lib/mysql1 socket=/tmp/mysql1.sock tmpdir=/var/tmp/mysql1 port=13301 <omitted>
動作確認のために、適当なデータベース書き込み処理を発生させます。
[root@localhost ~]# mysqld_multi start 1 [root@localhost ~]# mysql -uroot --socket=/tmp/mysql1.sock test << EOF > create table example ( id INT ) ; > drop table example ; > EOF [root@localhost ~]#
binary log ( バイナリログ )が発生した事を確認します。mysql-bin.000001がbinary log (バイナリログ)です。
[root@localhost ~]# ll /var/lib/mysql1 total 110636 -rw-rw---- 1 mysql mysql 56 Aug 19 08:27 auto.cnf -rw-rw---- 1 mysql mysql 50331648 Aug 19 09:00 ib_logfile0 -rw-rw---- 1 mysql mysql 50331648 Aug 18 22:53 ib_logfile1 -rw-rw---- 1 mysql mysql 12582912 Aug 19 09:00 ibdata1 drwx------ 2 mysql mysql 4096 Aug 18 22:53 mysql -rw-rw---- 1 mysql mysql 345 Aug 19 09:00 mysql-bin.000001 -rw-rw---- 1 mysql mysql 19 Aug 19 08:59 mysql-bin.index drwx------ 2 mysql mysql 4096 Aug 18 22:53 performance_schema -rw-r----- 1 mysql root 13374 Aug 19 08:59 skr145.changineer.info.err -rw-rw---- 1 mysql mysql 5 Aug 19 08:59 skr145.changineer.info.pid drwx------ 2 mysql mysql 4096 Aug 19 09:00 test [root@localhost ~]#
mysql レプリケーション 基本設定 – server id 設定
MySQL でreplication ( レプリケーション ) を行なうにはサーバ間で異なるserver-idを付与する必要があります。/etc/my.cnfの各[mysqlN]セクションに、server-idの設定を加筆します。
[mysqld] log-bin=mysql-bin relay-log=mysql-relay [mysqld_multi] mysqld=/usr/bin/mysqld_safe mysqladmin=/usr/bin/mysqladmin [mysqld1] datadir=/var/lib/mysql1 socket=/tmp/mysql1.sock tmpdir=/var/tmp/mysql1 port=13301 server-id=1 [mysqld2] datadir=/var/lib/mysql2 socket=/tmp/mysql2.sock tmpdir=/var/tmp/mysql2 port=13302 server-id=2 <omitted>
mysqld ( MySQL サーバ ) プロセス毎に異なるserver-idが付与された事を確認します。
[root@localhost ~]# mysqld_multi stop [root@localhost ~]# mysqld_multi start [root@localhost ~]# [root@localhost ~]# [root@localhost ~]# mysql -uroot --socket=/tmp/mysql1.sock -e 'show variables like "server_id"' +---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 1 | +---------------+-------+ [root@localhost ~]# mysql -uroot --socket=/tmp/mysql2.sock -e 'show variables like "server_id"' +---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 2 | +---------------+-------+ [root@localhost ~]#
mysql レプリケーション 基本設定 – replication ユーザの作成 (Masterサーバの操作)
MySQL Masterとなるサーバにreplication専用のユーザを作成します。rootユーザでも理論上は動作しますが、セキュリティの観点から最小限の権限 REPLICATION, SLAVEのみを与えたユーザを作成するのが一般的です。
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
mysql レプリケーション 基本設定 – データコピー (Masterサーバの操作)
replication ( レプリケーション ) を開始する時点で、Master / Slave間で同一のデータを保持する必要があります。エキスパートのためのMySQLトラブルシューティングガイドによると、データをコピーする方法は大きく分けて以下の3通りがあります。
- mysqldumpによるデータコピー
- /var/lib/mysqlをそのままコピー
- LVM snapshotを利用したコピー
最も簡単な”mysqldumpによるデータコピー”の方法を紹介します。まずは、どの時点のコピーを取ったかを明確にするため、全てのテーブルに対してREAD LOCKをかけます。
mysql> FLUSH TABLES WITH READ LOCK;
READ LOCKをかけた状態で、MASTER POSTIONをメモに残します。このMASTER POSITIONの値は、binary log (バイナリログ)のどの位置からreplication (レプリケーション )を行なうべきかを指定する際に使用します。MASTER POSITIONを確認するには、”SHOW MASTER STATUS”コマンドを使用します。
mysql> SHOW MASTER STATUS \G;
*************************** 1. row ***************************
File: mysql-bin.000002
Position: 344
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
ERROR:
No query specified
mysql>
MASTER POSITIONの確認が済みましたら、mysqldumpによるコピーを取得します。
[root@localhost ~]# mysqldump -uroot --socket=/tmp/mysql1.sock --all-databases > dump.sql
READ LOCKを解除します。
mysql> UNLOCK TABLE ;
mysql レプリケーション 基本設定 – replication 開始 (Slaveサーバの操作)
mysqld2, mysql3に対して、先ほど取得したmysqldumpをSlaveサーバにインポートします。
[root@localhost ~]# mysql -uroot --socket=/tmp/mysql{2,3}.sock < dump.sql
binary log ( バイナリログ ) のどの位置からreplication (レプリケーション)を行なうべきか指定には、”CHANGE MASTER TO”文を使用します。MASTER_LOG_FILE, MASTER_LOG_POSは先ほどの”SHOW MASTER STATUS”で確認した値を入れて下さい。
mysql> CHANGE MASTER TO
-> MASTER_HOST = '127.0.0.1',
-> MASTER_USER = 'repl',
-> MASTER_PORT = 13301,
-> MASTER_LOG_FILE = 'mysql-bin.000002',
-> MASTER_LOG_POS = 344;
replication (レプリケーション)を開始するには、”START SLAVE”コマンドを使用します。
mysql> START SLAVE ;
“SHOW SLAVE STATUS”コマンドにより、replication (レプリケーション)が正常に行なわれているかを確認します。Slave_IO_Running, Slave_SQL_RunningがともにYesと表示されている事を確認します。
mysql> SHOW SLAVE STATUS \G ;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: repl
Master_Port: 13301
Connect_Retry: 60
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 344
Relay_Log_File: mysql-relay.000002
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 344
Relay_Log_Space: 452
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 46967d84-272f-11e4-87b5-525409007131
Master_Info_File: /var/lib/mysql2/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
1 row in set (0.00 sec)
ERROR:
No query specified
mysql>
MySQL Masterにデータを書き込み、その値がMySQL Slaveに反映されている事を確認します。
[root@localhost ~]# mysql -uroot --socket=/tmp/mysql1.sock test << EOF > CREATE TABLE example ( id INT ) ; > INSERT INTO example values (1), (2), (3) ; > EOF [root@localhost ~]# [root@localhost ~]# mysql -uroot --socket=/tmp/mysql2.sock test -e "select * from example" +------+ | id | +------+ | 1 | | 2 | | 3 | +------+ [root@localhost ~]# mysql -uroot --socket=/tmp/mysql3.sock test -e "select * from e xample" +------+ | id | +------+ | 1 | | 2 | | 3 | +------+ [root@localhost ~]#
mysql レプリケーション 孫Slave ( replicatoin chain )
mysql レプリケーション 孫Slave ( replicatoin chain ) – 設定
孫Slave (孫スレーブ) のレプリケーション構成を構築するためには1点だけ注意が必要です。孫Slaveにデータを転送するサーバに対してlog-slave-updatesの1行を加えなければならない事に注意して下さい。
デフォルトの状態ではSQL threadによって書き込まれたレプリケーションによるデータはbinary log (バイナリログ)に書き込まれません。log-slave-updatesを加える事によって、レプリケーションによるデータがbinlog (バイナリログ)に書き込まれるようになります。
/etc/my.cnfの設定例は以下の通りです。
<omitted> [mysqld3] datadir=/var/lib/mysql3 socket=/tmp/mysql3.sock tmpdir=/var/tmp/mysql3 port=13303 server-id=3 log-slave-updates <omitted>
設定反映のため、mysqld ( MySQL サーバ ) の再起動を行ないます。
[root@localhost ~]# mysqld_multi stop 3 [root@localhost ~]# mysqld_multi start 3
mysql レプリケーション 孫Slave ( replicatoin chain ) – データコピー (Masterサーバの操作)
データコピーの方法は先ほどの説明の通り、通常のreplication (レプリケーション)の手順と変わりません。説明は省略し、操作コマンドのみ紹介します。
mysql> FLUSH TABLES WITH READ LOCK ;
Query OK, 0 rows affected (0.01 sec)
mysql> SHOW MASTER STATUS \G;
*************************** 1. row ***************************
File: mysql-bin.000003
Position: 120
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
ERROR:
No query specified
mysql>
[root@localhost ~]# mysqldump -uroot --socket=/tmp/mysql3.sock --all-databases > mysql3.dump
mysql> UNLOCK TABLES ;
mysql レプリケーション 孫Slave ( replicatoin chain ) – replication 開始 (Slaveサーバの操作)
replication (レプリケーション)の開始方法は先ほどの説明の通り、通常のreplication (レプリケーション)の手順と変わりません。説明は省略し、操作コマンドのみ紹介します。
[root@localhost ~]# mysql -uroot --socket=/tmp/mysql4.sock < mysql3.dump
mysql> CHANGE MASTER TO
-> MASTER_HOST = '127.0.0.1',
-> MASTER_USER = 'repl',
-> MASTER_PORT = 13303,
-> MASTER_LOG_FILE = 'mysql-bin.000003',
-> MASTER_LOG_POS = 120;
Query OK, 0 rows affected, 2 warnings (0.05 sec)
mysql> START SLAVE ;
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> SHOW SLAVE STATUS \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: repl
Master_Port: 13303
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 120
Relay_Log_File: mysql-relay.000002
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 120
Relay_Log_Space: 452
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_UUID: ba8f3584-2791-11e4-8a37-525409007131
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
1 row in set (0.00 sec)
ERROR:
No query specified
mysql>
mysql Semi-Synchronous replication
mysql Semi-Synchronous replication – 概要
mysql Semi-Synchronous replication とは、準同期のレプリケーションです。漢のコンピュータ道の図が一番分かりやすいと思いますので、図をそのまま引用します。
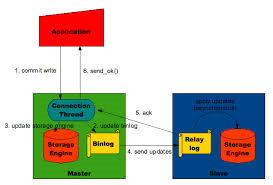
通常、MySQL Masterサーバに障害が発生した際、アプリケーションサーバに正常応答が返ったとしても、binary log (バイナリログ)がSlaveサーバへ転送されている保証はありません。つまり、データロスの可能性があるという事です。
しかし、Semi-Synchronous replicationを使用すると、binary logが転送されるのを待ってから正常応答を返すため、正常応答が返った処理に関してはデータロスがない事を意味します。
mysql Semi-Synchronous replication – プラグインの追加
Semi-Synchronous replicationはMySQL 5.6の標準機能として備わってはいません。使用するためには、追加のプラグインが必要となります。
MySQL Masterとなるサーバに”rpl_semi_sync_master”を追加します。
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
MySQL Slaveとなるサーバに”rpl_semi_sync_slave ”を追加します。
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql Semi-Synchronous replication – 設定
mysql1をsemi sync masterとして設定し、mysql2をsemi sync slaveとして設定する例は以下のようになります。追加する設定は以下3行のみで非常にシンプルです。
rpl_semi_sync_master_timeoutはsemi sync modeを解除する閾値で、指定した時間(ミリ秒)以内にbinary log (バイナリログ)を転送できなかった場合は、通常のreplicationに切り替わります。長すぎるとSlaveサーバ高負荷時の応答遅延につながりますし、短すぎるとsemi syncの解除が頻発してしまいます。
<omitted> [mysqld1] datadir=/var/lib/mysql1 socket=/tmp/mysql1.sock tmpdir=/var/tmp/mysql1 port=13301 server-id=1 rpl_semi_sync_master_enabled=1 rpl_semi_sync_master_timeout=1000 [mysqld2] datadir=/var/lib/mysql2 socket=/tmp/mysql2.sock tmpdir=/var/tmp/mysql2 port=13302 server-id=2 rpl_semi_sync_slave_enabled=1
設定反映にmysqld (MySQL サーバ) の再起動は必要ございません。以下のようにGLOBAL変数を書き換え、STOP SLAVE / START SLAVEで設定が反映されます。
[root@localhost ~]# mysql -uroot --socket=/tmp/mysql1.sock << EOF > SET GLOBAL rpl_semi_sync_master_enabled = 1 ; > SET GLOBAL rpl_semi_sync_master_timeout = 1000 ; > EOF [root@localhost ~]# mysql -uroot --socket=/tmp/mysql2.sock << EOF > SET GLOBAL rpl_semi_sync_slave_enabled = 1 ; > STOP SLAVE ; > START SLAVE ; > EOF [root@localhost ~]#
mysql Semi-Synchronous replication – 動作確認
semi syncを設定すると、semi sync masterとなるサーバ側の”SHOW STATUS”コマンドで、Rpl_semi_syncという変数を確認する事ができます。Rpl_semi_sync_master_clientsが1以上であり、Rpl_semi_sync_master_statusがONになっている事を確認します。
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%'; +--------------------------------------------+-------+ | Variable_name | Value | +--------------------------------------------+-------+ | Rpl_semi_sync_master_clients | 1 | | Rpl_semi_sync_master_net_avg_wait_time | 0 | | Rpl_semi_sync_master_net_wait_time | 0 | | Rpl_semi_sync_master_net_waits | 0 | | Rpl_semi_sync_master_no_times | 0 | | Rpl_semi_sync_master_no_tx | 0 | | Rpl_semi_sync_master_status | ON | | Rpl_semi_sync_master_timefunc_failures | 0 | | Rpl_semi_sync_master_tx_avg_wait_time | 0 | | Rpl_semi_sync_master_tx_wait_time | 0 | | Rpl_semi_sync_master_tx_waits | 0 | | Rpl_semi_sync_master_wait_pos_backtraverse | 0 | | Rpl_semi_sync_master_wait_sessions | 0 | | Rpl_semi_sync_master_yes_tx | 0 | +--------------------------------------------+-------+ 14 rows in set (0.04 sec) mysql>
semi sync slaveが障害または高負荷時は、Rpl_semi_sync_master_statusがOFFと表示されます。
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%'; +--------------------------------------------+-------+ | Variable_name | Value | +--------------------------------------------+-------+ | Rpl_semi_sync_master_clients | 0 | | Rpl_semi_sync_master_net_avg_wait_time | 211 | | Rpl_semi_sync_master_net_wait_time | 1056 | | Rpl_semi_sync_master_net_waits | 5 | | Rpl_semi_sync_master_no_times | 2 | | Rpl_semi_sync_master_no_tx | 6 | | Rpl_semi_sync_master_status | OFF | | Rpl_semi_sync_master_timefunc_failures | 0 | | Rpl_semi_sync_master_tx_avg_wait_time | 634 | | Rpl_semi_sync_master_tx_wait_time | 1902 | | Rpl_semi_sync_master_tx_waits | 3 | | Rpl_semi_sync_master_wait_pos_backtraverse | 0 | | Rpl_semi_sync_master_wait_sessions | 0 | | Rpl_semi_sync_master_yes_tx | 3 | +--------------------------------------------+-------+ 14 rows in set (0.00 sec) mysql>
mysql replication Multi-Threaded Mode
mysql replication Multi-Threaded Mode 概要
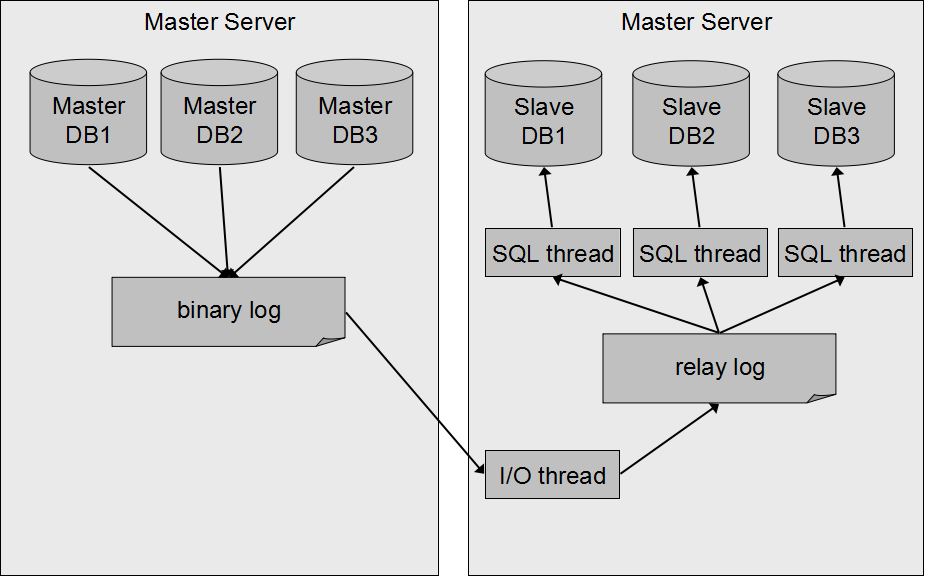
MySQL 5.6の新機能で、マルチスレッド レプリケーションがあります。これはデータベース単位で複数のSQL Thread Threadが起動するモードです。なお、ひとつのデータベースに対してはシングルスレッドで動作しますので、データベースがひとつしか存在しない環境においては、マルチスレッド化の恩恵を受ける事はできません。
マルチスレッドの構成を図で表すと以下の通りです。
mysql replication Multi-Threaded Mode 設定
マルチスレッド レプリケーションの設定は非常に簡単です。最小限の設定は、slave_parallel_workersの1行のみです。
[mysqld] log-bin=mysql-bin relay-log=mysql-relay binlog-format=MIXED relay-log-info-repository=TABLE master-info-repository=TABLE slave_parallel_workers=3 [mysqld_multi] mysqld=/usr/bin/mysqld_safe mysqladmin=/usr/bin/mysqladmin <omitted>
マルチスレッド化の設定は、mysqld (MySQL サーバ) の再起動は必要ございません。以下のようにGLOBAL変数を書き換え、STOP SLAVE / START SLAVEで設定が反映されます。
mysql> SET GLOBAL slave_parallel_workers=3 ; Query OK, 0 rows affected (0.00 sec) mysql> STOP SLAVE ; Query OK, 0 rows affected (0.03 sec) mysql> START SLAVE ; Query OK, 0 rows affected, 1 warning (0.04 sec) mysql>
mysql replication Multi-Threaded Mode 動作確認
マルチスレッド レプリケーションはデータベース単位でSQL threadが動作します。従って、動作確認を行うには複数データベースに対して書き込みを行なう必要があります。
[root@localhost ~]# mysql -uroot --socket=/tmp/mysql1.sock << EOF USE test ; DROP TABLE example ; CREATE TABLE example ( id INT ) ; INSERT INTO example values (1), (2), (3) ; CREATE DATABAE test2 ; USE test2; CREATE TABLE example ( id INT ) ; INSERT INTO example values (1), (2), (3) ; EOF
複数スレッドのSQL threadを管理するファイルが作成されている事が確認できます。
[root@localhost ~]# ls -l /var/lib/mysql3/ | grep worker -rw-rw---- 1 mysql mysql 83 Aug 19 21:45 worker-relay-log.info.1 -rw-rw---- 1 mysql mysql 176 Aug 19 21:50 worker-relay-log.info.2 -rw-rw---- 1 mysql mysql 176 Aug 19 21:50 worker-relay-log.info.3 [root@localhost ~]# cat /var/lib/mysql3/worker-relay-log.info.3 3 ./mysql-relay.000006 906732 mysql-bin.000003 906569 ./mysql-relay.000006 904591 mysql-bin.000003 904428 13 64 8[root@localhost ~]#
“relay-log-info-repository=TABLE”としている場合は、SQL threadに関する情報はテーブルに書き出されます。確認方法は以下の通りです。
[root@localhost ~]# mysql -uroot --socket=/tmp/mysql2.sock mysql
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 7
Server version: 5.6.20-log MySQL Community Server (GPL)
Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select * from slave_worker_info \G;
*************************** 1. row ***************************
Id: 1
Relay_log_name:
Relay_log_pos: 0
Master_log_name:
Master_log_pos: 0
Checkpoint_relay_log_name:
Checkpoint_relay_log_pos: 0
Checkpoint_master_log_name:
Checkpoint_master_log_pos: 0
Checkpoint_seqno: 0
Checkpoint_group_size: 64
Checkpoint_group_bitmap:
*************************** 2. row ***************************
Id: 2
Relay_log_name: ./mysql-relay.000005
Relay_log_pos: 907189
Master_log_name: mysql-bin.000003
Master_log_pos: 907026
Checkpoint_relay_log_name: ./mysql-relay.000005
Checkpoint_relay_log_pos: 904591
Checkpoint_master_log_name: mysql-bin.000003
Checkpoint_master_log_pos: 904428
Checkpoint_seqno: 16
Checkpoint_group_size: 64
Checkpoint_group_bitmap: ヌ
*************************** 3. row ***************************
Id: 3
Relay_log_name: ./mysql-relay.000005
Relay_log_pos: 906732
Master_log_name: mysql-bin.000003
Master_log_pos: 906569
Checkpoint_relay_log_name: ./mysql-relay.000005
Checkpoint_relay_log_pos: 904591
Checkpoint_master_log_name: mysql-bin.000003
Checkpoint_master_log_pos: 904428
Checkpoint_seqno: 13
Checkpoint_group_size: 64
Checkpoint_group_bitmap: ・
3 rows in set (0.00 sec)
ERROR:
No query specified
mysql>
Tips
–master-data
MySQL Masterサーバのコピーを作成するにあたり、ロック操作、MASTER POSITIONの記録など非常に煩雑な作業が多数存在します。このような手間は、mysqldumpに–master-dataオプションを渡す事によって解消する事ができます。
使用例は以下の通りです。master-dataに1を渡すとCHANGE MATERがmysqldump内に生成されますので、手作業でCHANGE MASTER文を投入する必要はございません。master-dataに2を渡すとCHANGE MASTER文がコメントアウトされた状態でmysqldumpが生成されます。replication ( レプリケーション ) を開始前に目視確認を行いたい場合は、master-dataに2を渡すと良いでしょう。
[root@localhost ~]# mysqldump -uroot --socket=/tmp/mysql1.sock --all-databases --master-data=1 > dump.sql [root@localhost ~]# head -n 30 dump.sql -- MySQL dump 10.13 Distrib 5.6.20, for Linux (x86_64) -- -- Host: localhost Database: -- ------------------------------------------------------ -- Server version 5.6.20-log /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+00:00' */; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; -- -- Position to start replication or point-in-time recovery from -- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000004', MASTER_LOG_POS=1467; -- -- Current Database: `mysql` -- CREATE DATABASE /*!32312 IF NOT EXISTS*/ `mysql` /*!40100 DEFAULT CHARACTER SET latin1 */; USE `mysql`;
AWS RDSにおけるレプリケーション
AWS (Amazon Web Services) は、RDSと呼ばれるRDBMSの仕組みが存在します。現時点(2014/08/17)でRDSでMySQLレプリケーションを実装する場合の方法について説明します。
AWSは頻繁に使用が変わるので、この手順が有効であるのは1年も持たないかもしれません。手順を眺めて、AWSの便利さと制約の多さを感じ取って頂けると幸いです。
AWS RDS レプリケーション設定
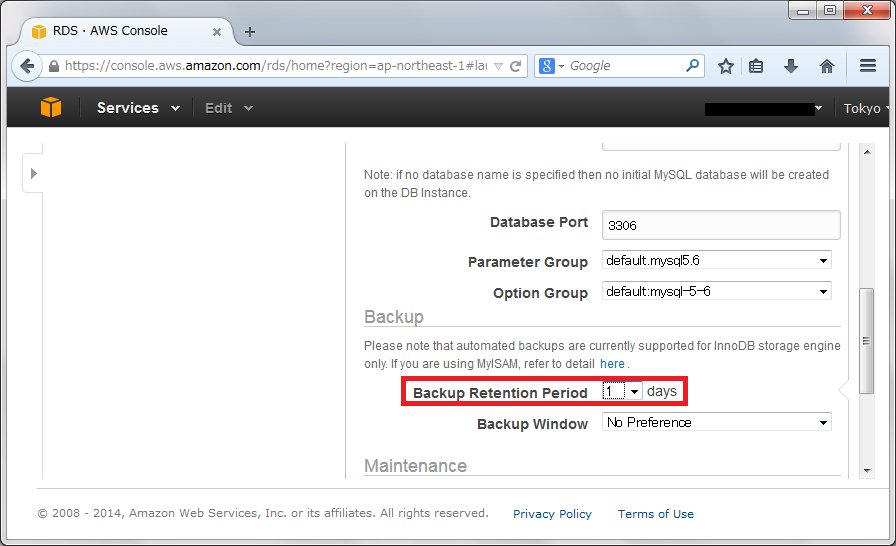
オンプレミス環境では、MySQLレプリケーションを行なうにあたり、bin log, server-idなどMySQLパラメタに注意を払わなければなりません。AWS RDSでは自動的にbin logとserver-idが設定されます。
唯一の注意点と言えば、Backupを有効にする事です。Backup Retention Periodを”0 day”と設定すると、binlog自体の出力が無効化されてしまうので、レプリケーションが行なえなくなります。
RDS to RDS レプリケーション
RDS間でレプリケーションを行なうのは非常に簡単です。”Create Read Replica”を押下するだけで、レプリケーション用ユーザの作成, データベースコピー, CHANGE MASTER文発行などの操作を自動的に行なってくれます。
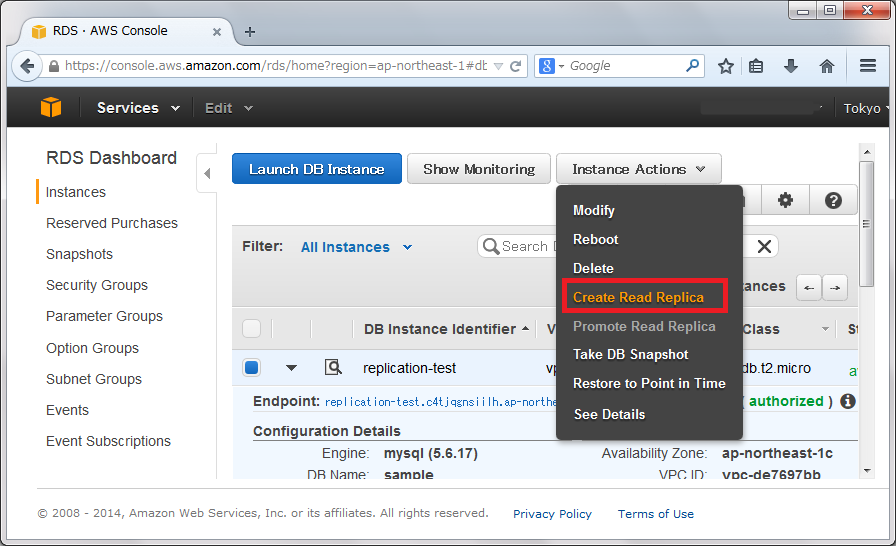
MySQLマスター側のプロセスを観察すると、”rdsrepladmin”というユーザが作成されレプリケーションが行なわれている事が観察できます。
mysql> show processlist \G;
*************************** 1. row ***************************
Id: 10
User: rdsadmin
Host: localhost:61587
db: mysql
Command: Sleep
Time: 14
State:
Info: NULL
*************************** 2. row ***************************
Id: 13
User: rdsrepladmin
Host: 10.7.1.232:56257
db: NULL
Command: Binlog Dump
Time: 299
State: Master has sent all binlog to slave; waiting for binlog to be updated
Info: NULL
*************************** 3. row ***************************
Id: 19
User: root
Host: 172.31.1.86:54288
db: NULL
Command: Query
Time: 0
State: init
Info: show processlist
3 rows in set (0.00 sec)
ERROR:
No query specified
mysql>
MySQL Slave側では、オンプレミス環境と同様に、”show slave status”による確認が可能です。
mysql> SHOW SLAVE STATUS \G ;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.7.1.93
Master_User: rdsrepladmin
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin-changelog.000008
Read_Master_Log_Pos: 120
Relay_Log_File: relaylog.000010
Relay_Log_Pos: 293
Relay_Master_Log_File: mysql-bin-changelog.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table: mysql.plugin,innodb_memcache.cache_policies,mysql.rds_sysinfo,mysql.rds_replication_status,mysql.rds_history,innodb_memcache.config_options
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 120
Relay_Log_Space: 516
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1910155471
Master_UUID: cabceab3-2861-11e4-8f84-0a805bc25f5b
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
1 row in set (0.00 sec)
ERROR:
No query specified
mysql>
RDS to EC2 レプリケーション
RDSからEC2へ、またはRDSからオンプレミスへのレプリケーションを行なう手順を説明します。現時点(2014/08/17)の仕様では、軽く20, 30分触っただけで以下のような運用上の困難が多数見つかってしまいました。
- “FLUSH TABLES”権限がないため、mysqldump取得時のMASTER POSITIONの位置が不明確。
- RDSが自動生成するCNAMEが64bitを超える可能性があり、レプリケーションの宛先ホストとして設定できない可能性がある。
- RDSのMySQLデータベースにはRDS固有情報が格納されており、取り扱いに注意が必要である。
RDS to EC2 レプリケーション – マスター側の操作
レプリケーション用ユーザの作成操作は、オンプレミス環境と全く変わらない手順です。
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%'; Query OK, 0 rows affected (0.01 sec) mysql> FLUSH PRIVILEGES ; Query OK, 0 rows affected (0.01 sec) mysql>
データコピーに関しては一癖あります。AWS RDSではroot権限を持ったユーザが与えられないため操作が限られています。“FLUSH TABLES WITH READ LOCK”を実行する権限がないため、mysqldumpを取得した時点のMASTER POSITIONを把握する事ができません。
mysqldumpを取得する際に一切のアクセスを禁じるようなセキュリティグループを作成する、目視でバイナリログファイルを読み取りMASTER POSITIONを推測する等の何らかの工夫が必要となります。
また、mysqldumpでインポート/エクスポートする対象のデータベースには注意を払ってください。mysqlデータベースはRDS固有の管理情報が格納されていますので、コピー対象に含めない方が良いでしょう。
[ec2-user@localhost ~]$ mysqldump -uroot -ppassword --host=replication-test.c4tjqgnsiilh.ap-northeast-1.rds.amazonaws.com sample > sample.dump Warning: Using a password on the command line interface can be insecure. [ec2-user@localhost ~]$
RDS to EC2 レプリケーション – スレーブ側の操作
mysqldumpはインポートは、通常の手順と全く変わりません。
[root@localhost ~]# mysql -uroot sample < sample.dump
mysqlなど一部データベースはレプリケーション対象に含めると不都合が生じてしまいますので、レプリケーション対象から除外します。replicate-ignore-dbを/etc/my.cnfに設定します。
[mysqld] datadir=/var/lib/mysql socket=/tmp/mysql.sock tmpdir=/var/tmp/mysql port=3306 replicate-ignore-db=mysql
CHANGE MASTER文を発行する際は、MASTER_HOSTにCNAMEを指定できない事があります。なぜなら、ホスト名指定が64bitまでと決められているので、CNAMEを使用する場合は64bitの上限に抵触する可能性があります。
ですので、64bit未満のホスト名かIPアドレスで指定せざるを得ません。CHANGE MASTER 文の実行例は以下の通りです。
mysql> CHANGE MASTER TO
-> MASTER_HOST = 'ec2-54-64-3-123.ap-northeast-1.compute.amazonaws.com',
-> MASTER_USER = 'repl',
-> MASTER_PASSWORD = 'password',
-> MASTER_PORT = 3306,
-> MASTER_LOG_FILE = 'mysql-bin-changelog.000022',
-> MASTER_LOG_POS = 120;
Query OK, 0 rows affected, 2 warnings (0.06 sec)
mysql>
レプリケーションが正常に行なわれている事を確認します。Slave_IO_Running, Slave_SQL_Runningが共にYESと表示されている事を確認します。
mysql> show slave status \G ;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: ec2-54-64-3-123.ap-northeast-1.compute.amazonaws.com
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin-changelog.000022
Read_Master_Log_Pos: 120
Relay_Log_File: mysql-relay.000002
Relay_Log_Pos: 293
Relay_Master_Log_File: mysql-bin-changelog.000022
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB: mysql
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
EC2 to RDS レプリケーション
EC2からRDSへ、またはオンプレミスからRDSへのレプリケーションを行なう手順を説明します。
EC2 to RDS レプリケーション – マスター側の操作
MySQL マスターとなるEC2またはオンプレミス環境の操作は、通常のオンプレミスの手順と変わりありません。具体的な操作手順は省略します。
EC2 to RDS レプリケーション – スレーブ側の操作
RDSは”CHANGE MASTER TO”等のレプリケーションに関する操作権限は与えられていませんが、その代わりにAmazonが予め用意したストアドプロシジャーを利用してreplication(レプリケーション)を設定します。
まずはどのようなストアドプロシジャーが存在するのかを観察してみましょう。
mysql> SHOW PROCEDURE STATUS LIKE "%repl%" ; +-------+-----------------------+-----------+--------------------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+ | Db | Name | Type | Definer | Modified | Created | Security_type | Comment | character_set_client | collation_connection | Database Collation | +-------+-----------------------+-----------+--------------------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+ | mysql | rds_skip_repl_error | PROCEDURE | rdsadmin@localhost | 2014-04-16 06:26:57 | 2014-04-16 06:26:57 | DEFINER | | utf8 | utf8_general_ci | latin1_swedish_ci | | mysql | rds_start_replication | PROCEDURE | rdsadmin@localhost | 2014-04-16 06:27:00 | 2014-04-16 06:27:00 | DEFINER | | utf8 | utf8_general_ci | latin1_swedish_ci | | mysql | rds_stop_replication | PROCEDURE | rdsadmin@localhost | 2014-04-16 06:27:00 | 2014-04-16 06:27:00 | DEFINER | | utf8 | utf8_general_ci | latin1_swedish_ci | +-------+-----------------------+-----------+--------------------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+ 3 rows in set (0.01 sec) mysql> SHOW PROCEDURE STATUS LIKE "%master%" ; +-------+---------------------------+-----------+--------------------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+ | Db | Name | Type | Definer | Modified | Created | Security_type | Comment | character_set_client | collation_connection | Database Collation | +-------+---------------------------+-----------+--------------------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+ | mysql | rds_external_master | PROCEDURE | rdsadmin@localhost | 2014-04-16 06:27:00 | 2014-04-16 06:27:00 | DEFINER | | utf8 | utf8_general_ci | latin1_swedish_ci | | mysql | rds_next_master_log | PROCEDURE | rdsadmin@localhost | 2014-04-16 06:27:00 | 2014-04-16 06:27:00 | DEFINER | | utf8 | utf8_general_ci | latin1_swedish_ci | | mysql | rds_reset_external_master | PROCEDURE | rdsadmin@localhost | 2014-04-16 06:27:00 | 2014-04-16 06:27:00 | DEFINER | | utf8 | utf8_general_ci | latin1_swedish_ci | | mysql | rds_set_external_master | PROCEDURE | rdsadmin@localhost | 2014-04-16 06:27:00 | 2014-04-16 06:27:00 | DEFINER | | utf8 | utf8_general_ci | latin1_swedish_ci | +-------+---------------------------+-----------+--------------------+---------------------+---------------------+---------------+---------+----------------------+----------------------+--------------------+ 4 rows in set (0.01 sec) mysql>
ストアドプロシジャーの具体的な実装は、”SHOW CREATE PROCEDURE”により確認する事ができます。
mysql> SHOW CREATE PROCEDURE mysql.rds_set_external_master ;
+-------------------------+------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------+----------------------+--------------------+
| Procedure | sql_mode | Create Procedure | character_set_client | collation_connection | Database Collation |
+-------------------------+------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------+----------------------+--------------------+
| rds_set_external_master | NO_ENGINE_SUBSTITUTION | CREATE DEFINER=`rdsadmin`@`localhost` PROCEDURE `rds_set_external_master`(host VARCHAR(255),
port INT,
user VARCHAR(16),
passwd VARCHAR(256),
name VARCHAR(50),
pos LONG ,
enable_ssl_encryption BOOLEAN
)
BEGIN
DECLARE v_rdsrepl INT;
DECLARE v_mysql_version VARCHAR(20);
DECLARE v_called_by_user VARCHAR(50);
DECLARE v_sleep int;
DECLARE sql_logging BOOLEAN;
select @@sql_log_bin into sql_logging;
Select count(1) into v_rdsrepl from mysql.rds_history where action = 'disable set master' and master_user = 'rdsrepladmin';
Select user() into v_called_by_user;
select version() into v_mysql_version;
IF v_rdsrepl > 0 and v_called_by_user != 'rdsadmin@localhost'
THEN
set @@sql_log_bin=off;
Select 'RDS_SET_EXTERNAL_MASTER is disabled on this host.' as Message;
ELSE
SET @cmd = CONCAT('CHANGE MASTER TO ',
CONCAT_WS(', ',
CONCAT('MASTER_HOST = "', trim(both from host), '"'),
CONCAT('MASTER_PORT = ', port),
CONCAT('MASTER_USER = "', trim(both from user), '"'),
CONCAT('MASTER_PASSWORD = "', trim(both from passwd), '"'),
CONCAT('MASTER_LOG_FILE = "', trim(both from name), '"'),
CONCAT('MASTER_LOG_POS = ', pos),
CONCAT('MASTER_SSL = ', enable_ssl_encryption)));
PREPARE rds_set_master FROM @cmd;
update mysql.rds_replication_status set called_by_user=v_called_by_user, action='set master', mysql_version=v_mysql_version , master_host=trim(both from host), master_port=port where action is not null;
commit;
EXECUTE rds_set_master;
DEALLOCATE PREPARE rds_set_master;
INSERT into mysql.rds_history(called_by_user, action, mysql_version, master_host, master_port, master_user, master_log_file, master_log_pos, master_ssl)
values (v_called_by_user,'set master', v_mysql_version, trim(both from host), port, trim(both from user), trim(both from name), pos, enable_ssl_encryption);
commit;
END IF;
set @@sql_log_bin=sql_logging;
END | utf8 | utf8_general_ci | latin1_swedish_ci |
+-------------------------+------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------+----------------------+--------------------+
1 row in set (0.00 sec)
mysql>
さて、具体的な操作手順に話を戻しましょう。RDSでは、”CHANGE MASTER TO”文の変わりに、”rds_set_external_master”というストアドプロシジャーを使います。使用方法は、CHANGE MASTER TOと殆ど同じです。
mysql> call mysql.rds_set_external_master(
-> '133.242.XXX.XXX',
-> 13301,
-> 'repl',
-> '',
-> 'mysql-bin.000004',
-> 1467,
-> 0);
Query OK, 0 rows affected (0.06 sec)
mysql>
“START SLAVE”に相当するのは、”rds_start_replication”です。
mysql> call mysql.rds_start_replication ; +-------------------------+ | Message | +-------------------------+ | Slave running normally. | +-------------------------+ 1 row in set (1.01 sec) Query OK, 0 rows affected (1.01 sec) mysql>
確認コマンドは通常通りの”SHOW SLAVE STATUS”を使用する事ができます。Slave_IO_Running, Slave_SQL_Runningが共にYESになっている事を確認します。
mysql> show slave status \G ;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 133.242.XXX.XXX
Master_User: repl
Master_Port: 13301
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 1467
Relay_Log_File: relaylog.000002
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table: mysql.plugin,innodb_memcache.cache_policies,mysql.rds_sysinfo,mysql.rds_replication_status,mysql.rds_history,innodb_memcache.config_options
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
