Zabbixの監視設定について説明します。初心者の方は、ホスト、アイテム、テンプレートの概念を理解しましょう。慣れてくれば、次はトリガー、アクションについて覚えましょう。
このページを最後までお読み頂くと、既存のテンプレートを利用するのではなく、業務要件に合わせて自作テンプレートを作成する事ができるようになると思います。
Ping監視、ポート監視、リソース監視、ログ監視など監視項目別に具体的な実装方法を説明します。
Ping監視
アイテム設定
Ping監視を行うには、初期設定時点で組み込まれているテンプレート「Templates/Modules/Template Module ICMP Ping」を適用する事でicmpによる監視ができます。以下、Zabbixの監視の仕組みを理解するため、敢えて「Templates/Modules/Template Module ICMP Ping」を使用しない方法を説明します。
アイテム作成の画面で、タイプは「シンプルチェック」を選びます。「シンプルチェック」はZabbix Serverからの疎通を確認する監視のタイプです。ファイアウォールなどのネットワーク機器含めて正常性を確認したい時は「シンプルチェック」を使用します。
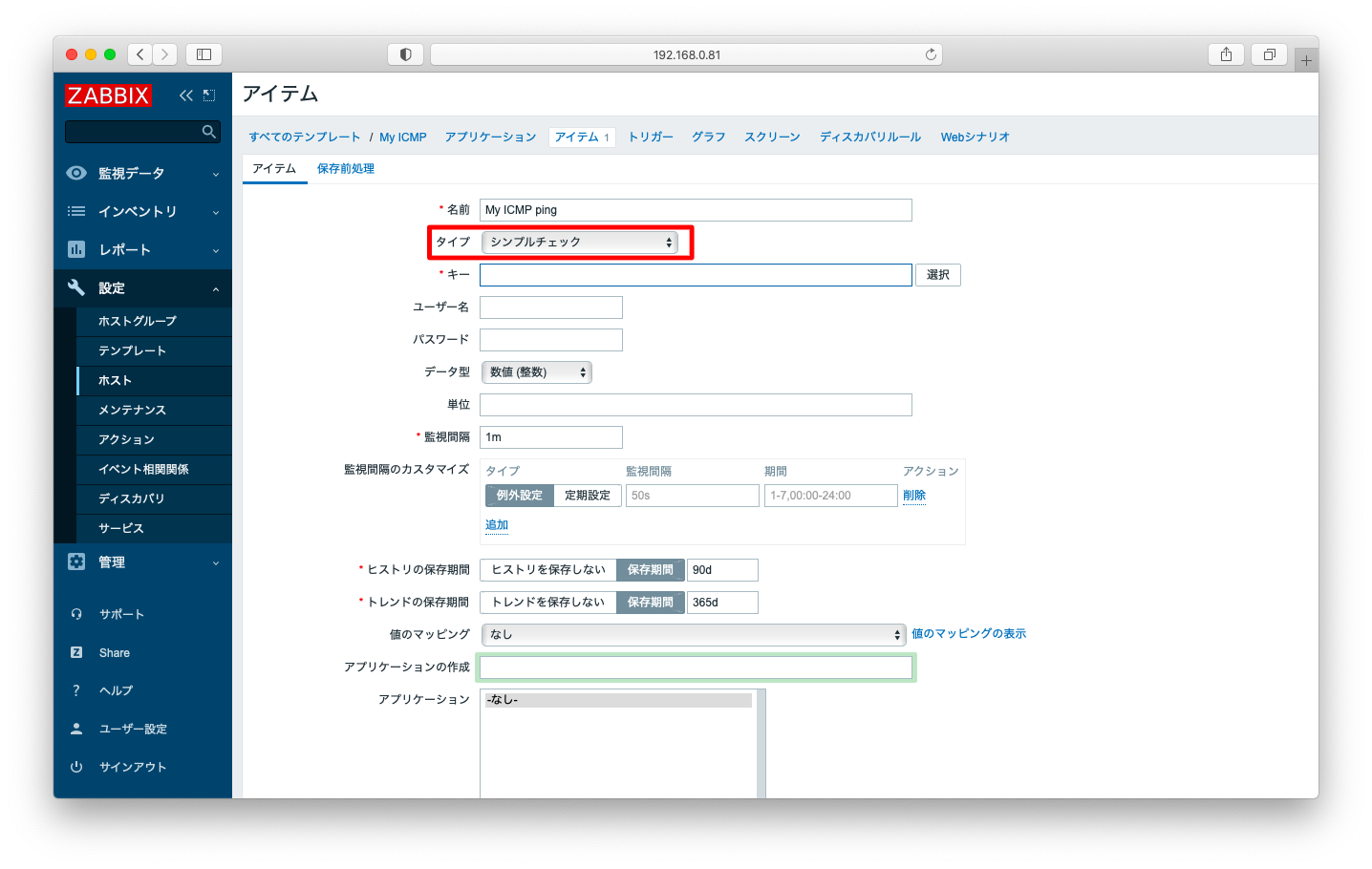
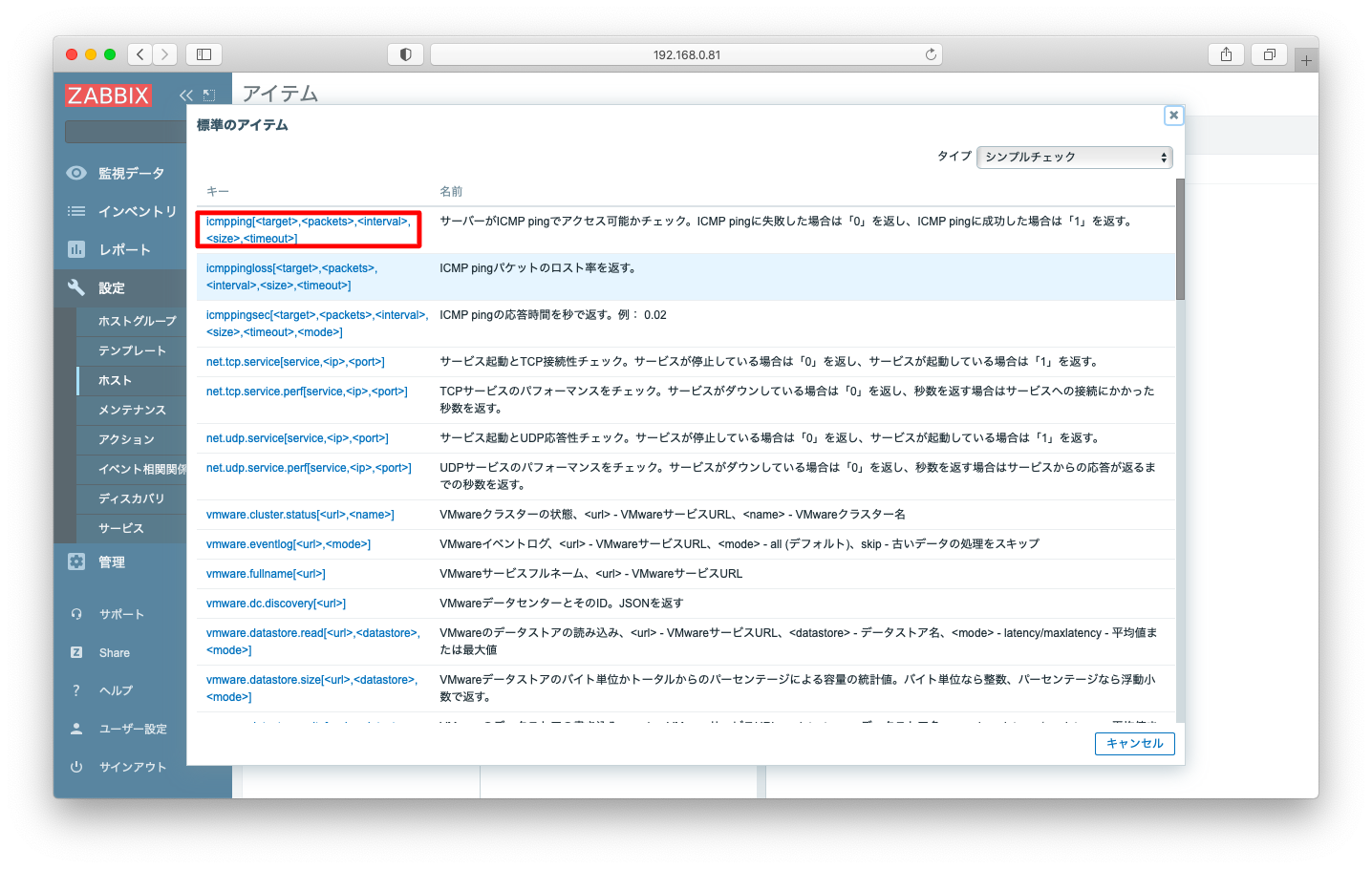
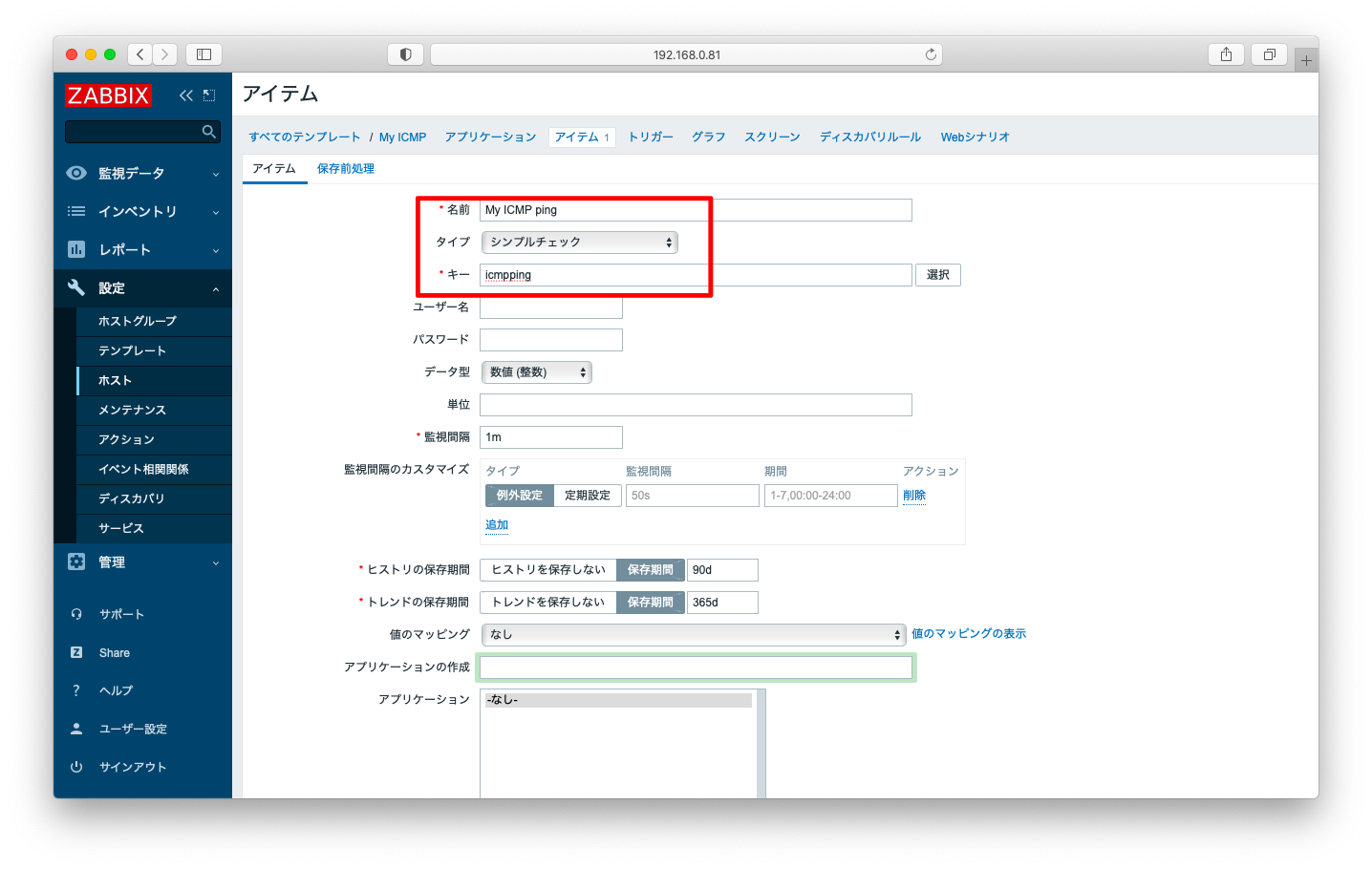
キーは「icmpping」を選びます。icmpに与えるパラメタtarget, packets, interval, size, timeoutは全て省略しても差し支えございません。各パラメタの意味は公式マニュアルのシンプルチェック(英語版 日本語版)を参照ください。
日本語マニュアルはZabbix 2.2で更新が止まっており、最新情報の入手をするには英語版マニュアルの参照が必要です。
下記スクリーンショットのような入力が完了したら、画面下の方へスクロールさせ「更新」を押下します。
トリガー設定
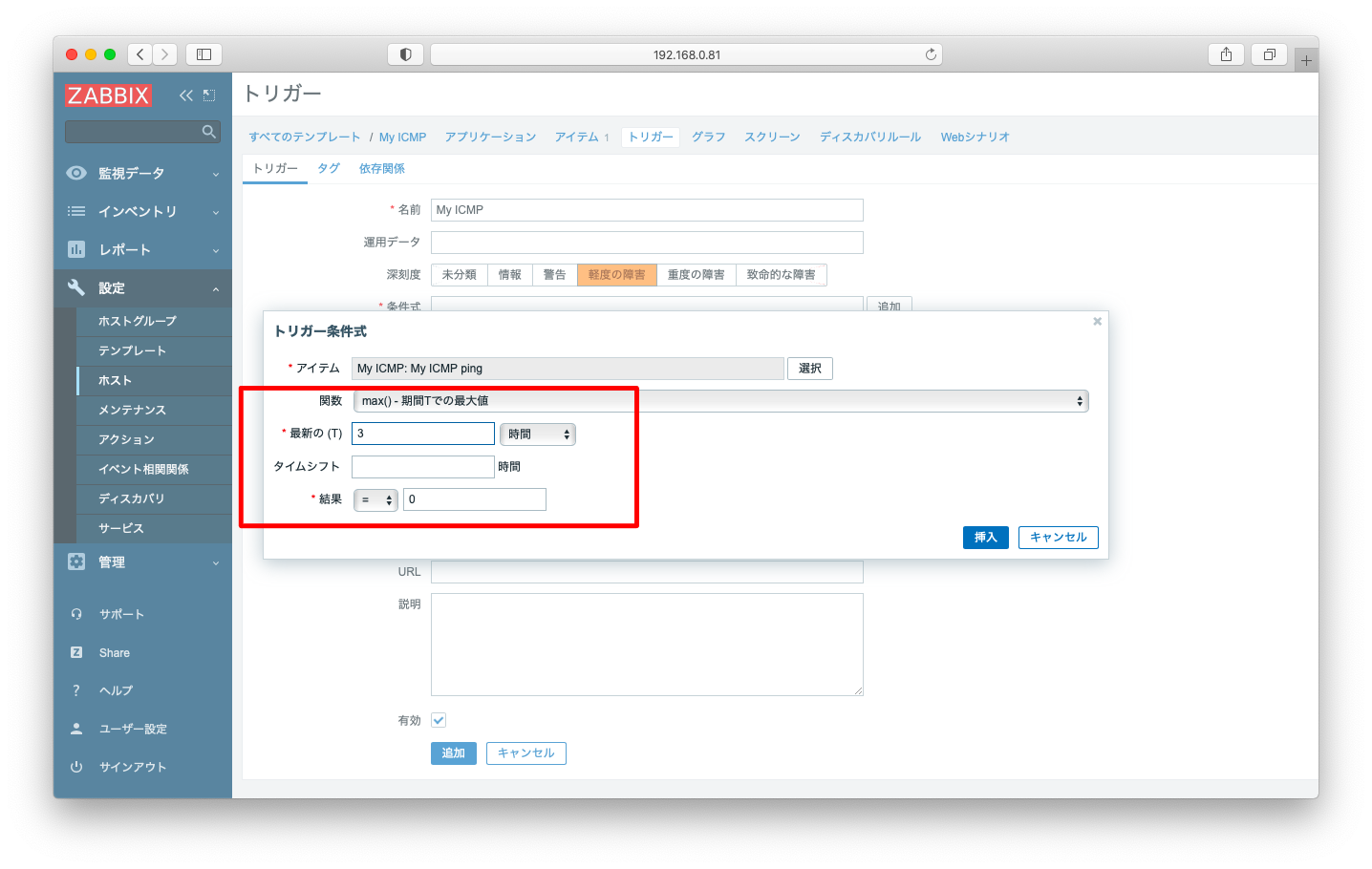
3回連続でpingに失敗したらアラートを挙げるような設定例を考えてみましょう。
このような設定を実現するにはトリガーの設定画面で関数「max 期間Tでの最大値」を選びます。この関数に対して「T=3」「結果=0」とすると3連続失敗の場合のみ発報されます。
icmppingは成功kが1を、失敗が0を返します。そのため、3連続で失敗した場合のみ最大値が0となり条件式に合致するようになります。
ポート監視 / Layer 7 疎通確認
アイテム設定
ポート監視は「Templates/Applications/Template App Apache by HTTP」などのアプリケーション監視を行うテンプレートに含まれている事もあります。これらテンプレートを適用する事で十分な監視を行う事もあります。しかし、ここでは、Zabbixの監視の仕組みを理解するため、敢えてデフォルトインストール済のテンプレートを使用しない方法を説明します。
ポート監視を行うにはnet.tcp.serviceというアイテムを利用します。net.tcp.serviceの引数は以下の通りです。
net.tcp.service[service,<ip>,<port>]
第一引数serviceは、通信の種別を表す必須パラメータです。serviceに指定可能な値は、ssh, ldap, smtp, ftp, http, pop, nntp, imap, tcp, https, telnetのいずれかです。各パラメタの詳細は公式マニュアルのシンプルチェック(英語版 日本語版)を参照ください。
日本語マニュアルはZabbix 2.2で更新が止まっており、最新情報の入手をするには英語版マニュアルの参照が必要です。
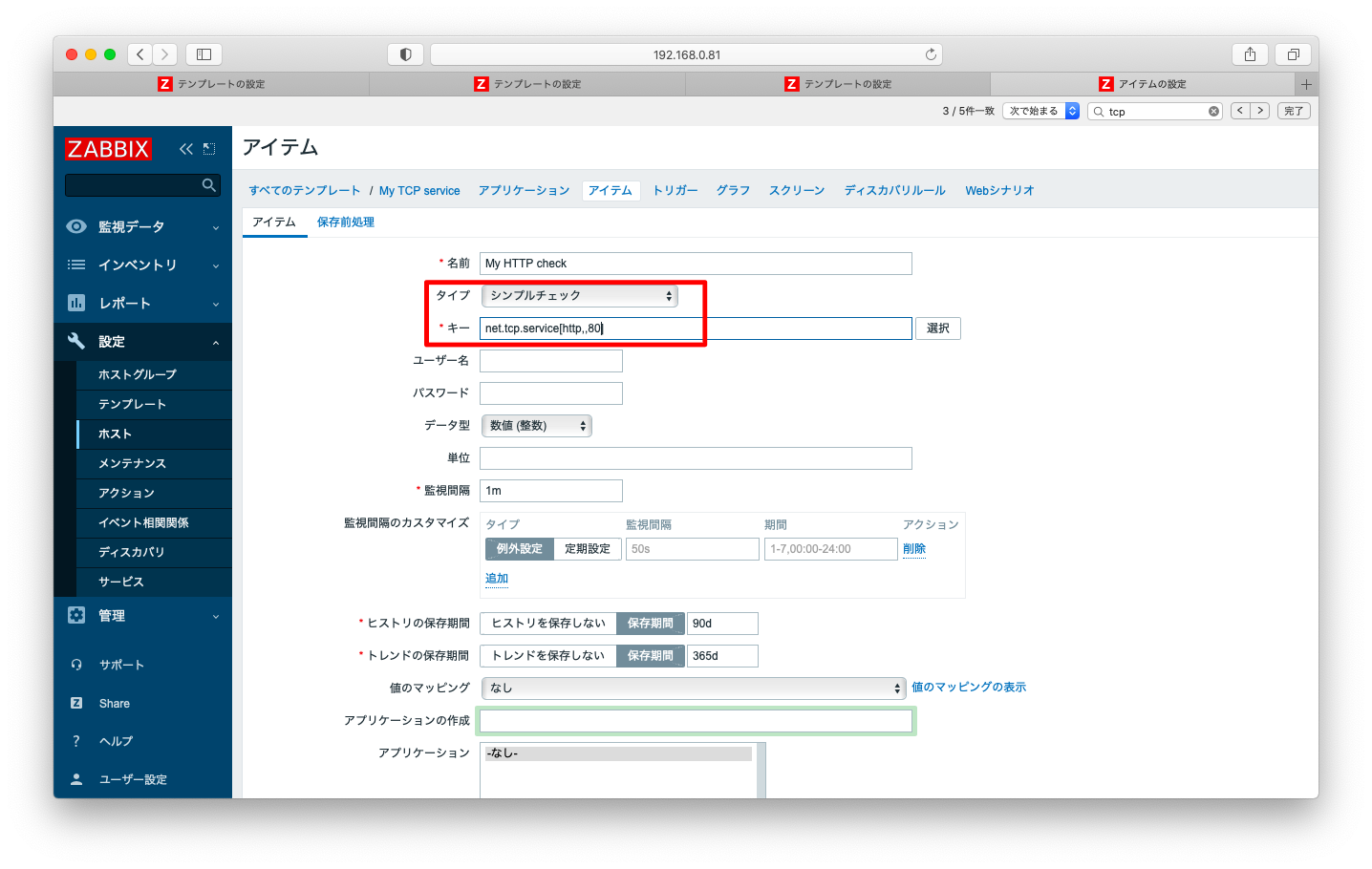
httpのように第一引数serviceに指定できるような通信ならば、アイテムを「net.tcp.service[http,,80]」となります。
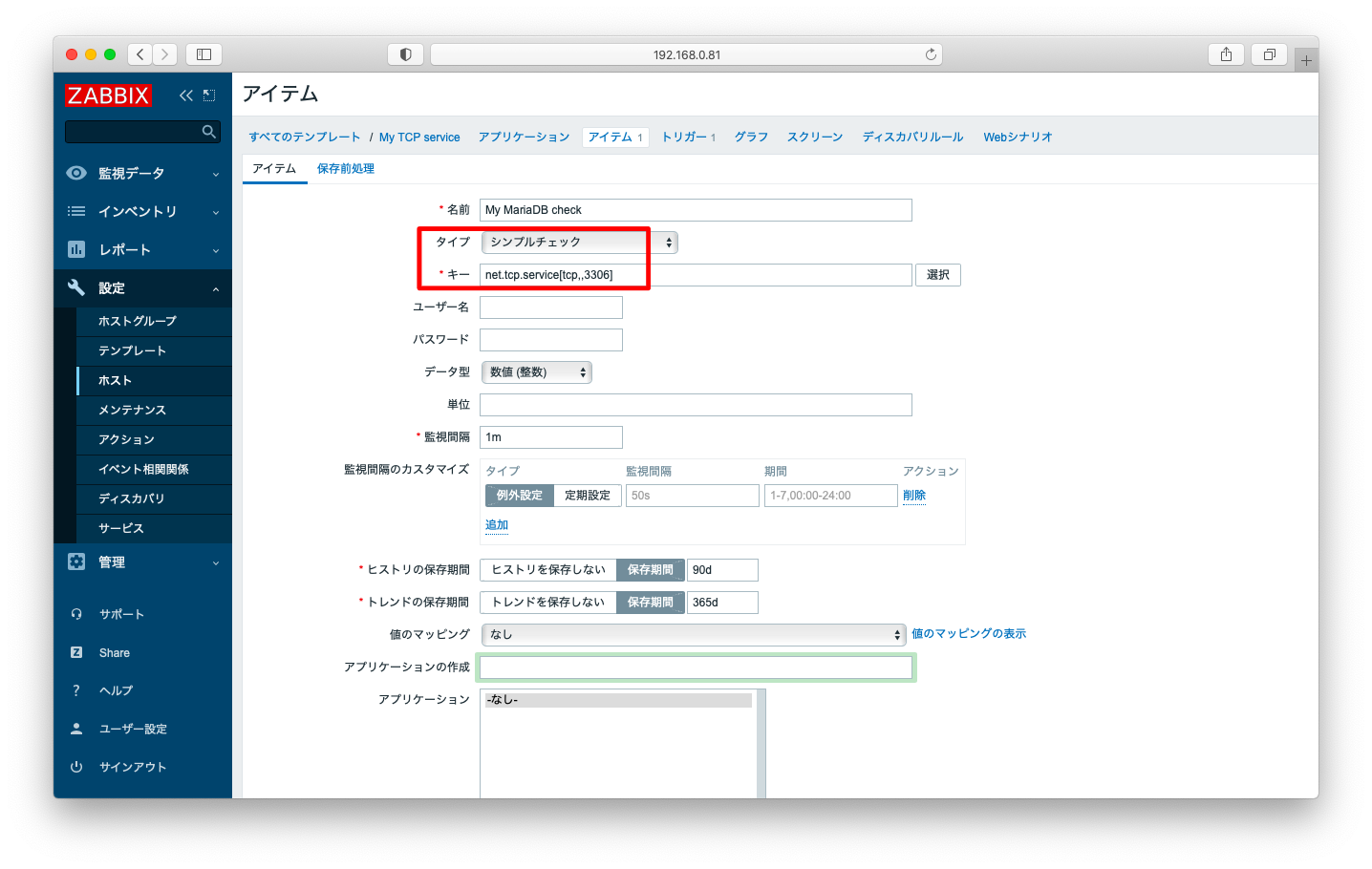
一方、MySQL(MariaDB)のように第一引数serviceに特段のプロトコルを指定できないような場合は、第一引数serviceにtcpを指定します。例えば、MySQL(MariaDB)を監視したいならば、アイテムを「net.tcp.service[tcp,,3306]」と指定します。
トリガー設定
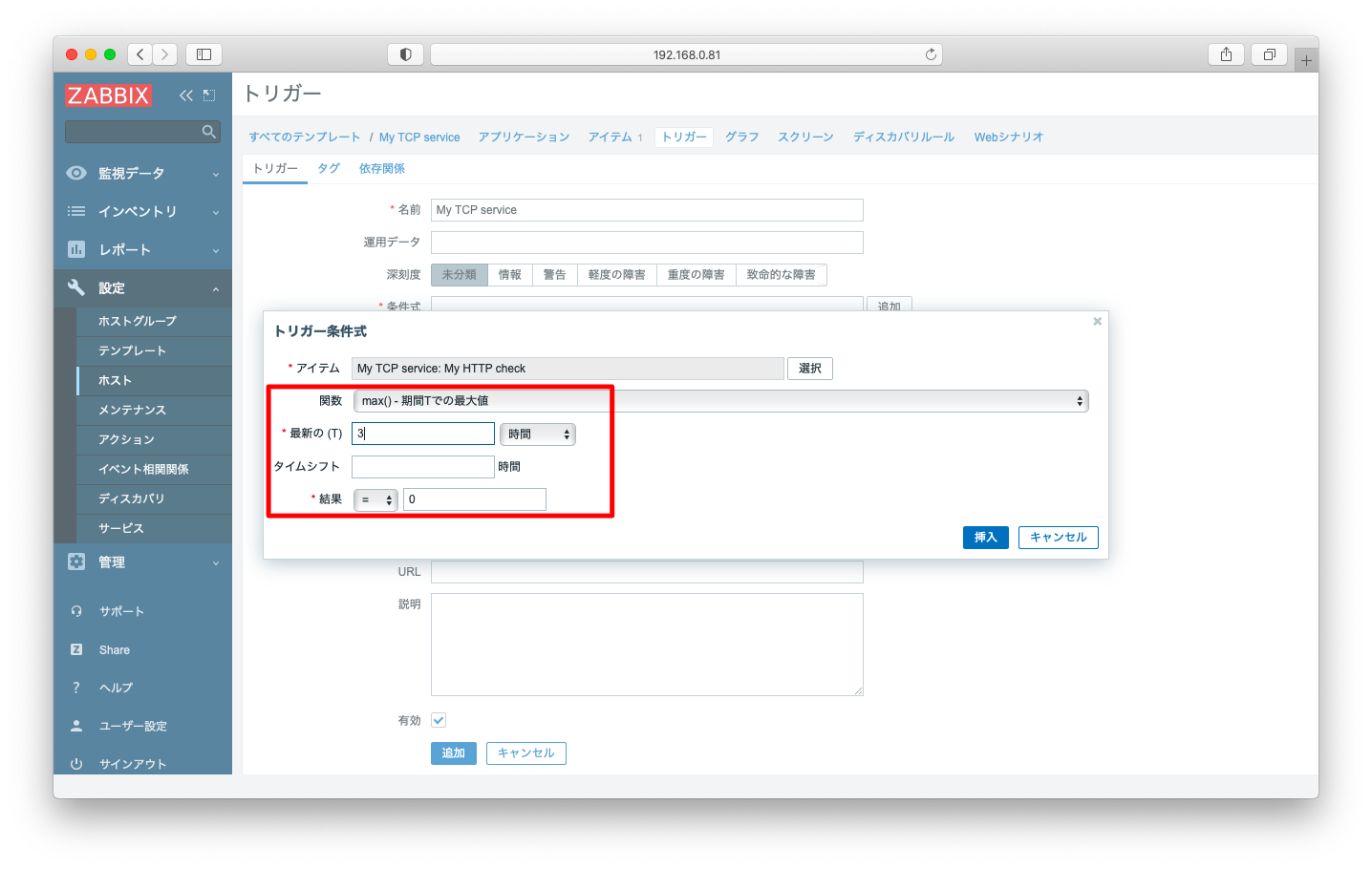
3回連続でTCP監視に失敗したらアラートを挙げるような設定例を考えてみましょう。
このような設定を実現するにはトリガーの設定画面で関数「max 期間Tでの最大値」を選びます。この関数に対して「T=3」「結果=0」とすると3連続失敗の場合のみ発報されます。
net.tcp.serviceは成功kが1を、失敗が0を返します。そのため、3連続で失敗した場合のみ最大値が0となり条件式に合致するようになります。
リソース監視
ディスクリソース監視
ディスクリソースの監視は、Zabbixデフォルト設定のテンプレート「Templates/Operating systems/Template OS Linux by Zabbix agent」「Templates/Operating systems/Template OS Windows by Zabbix agent」を利用すると良いでしょう。このテンプレートは、ローレベルディスカバリ(low level discovery)という仕組みを用いて、ディスクの種類を動的に取得してくれます。
ローレベルディスカバリはやや学習コストが高いので、まずはデフォルト設定を観察してローレベルディスカバリの仕組みを理解して下さい。慣れてきたら、ローレベルディスカバリの自力実装に挑戦しましょう。
テンプレート「emplate OS Linux by Zabbix agent」「Template OS Windows by Zabbix agent」の画面を開き、「ディスカバリルール」タブを押下します。この画面の「mounted filesystem discovery」がディスクの情報を動的に取得する仕組みになります。
監視項目を追加したい場合は「アイテムのプロトタイプ」を、監視閾値を変更したい場合は「トリガーのプロトタイプ」を変更します。
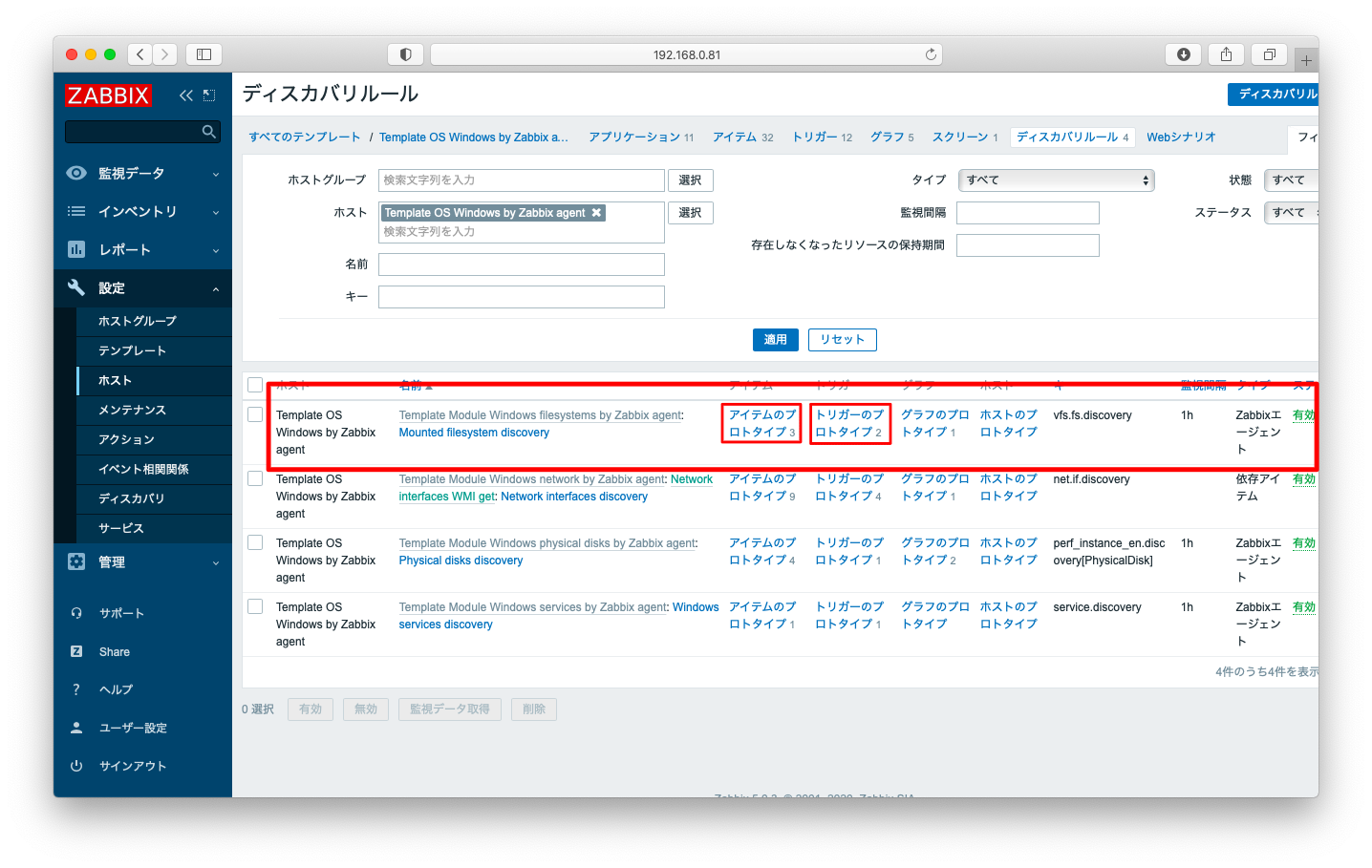
おそらく、ディスクリソースの閾値は運用の現場によって異なると思いますので、ディスク閾値を変更してみましょう。「トリガーのプロトタイプ」を押下します。
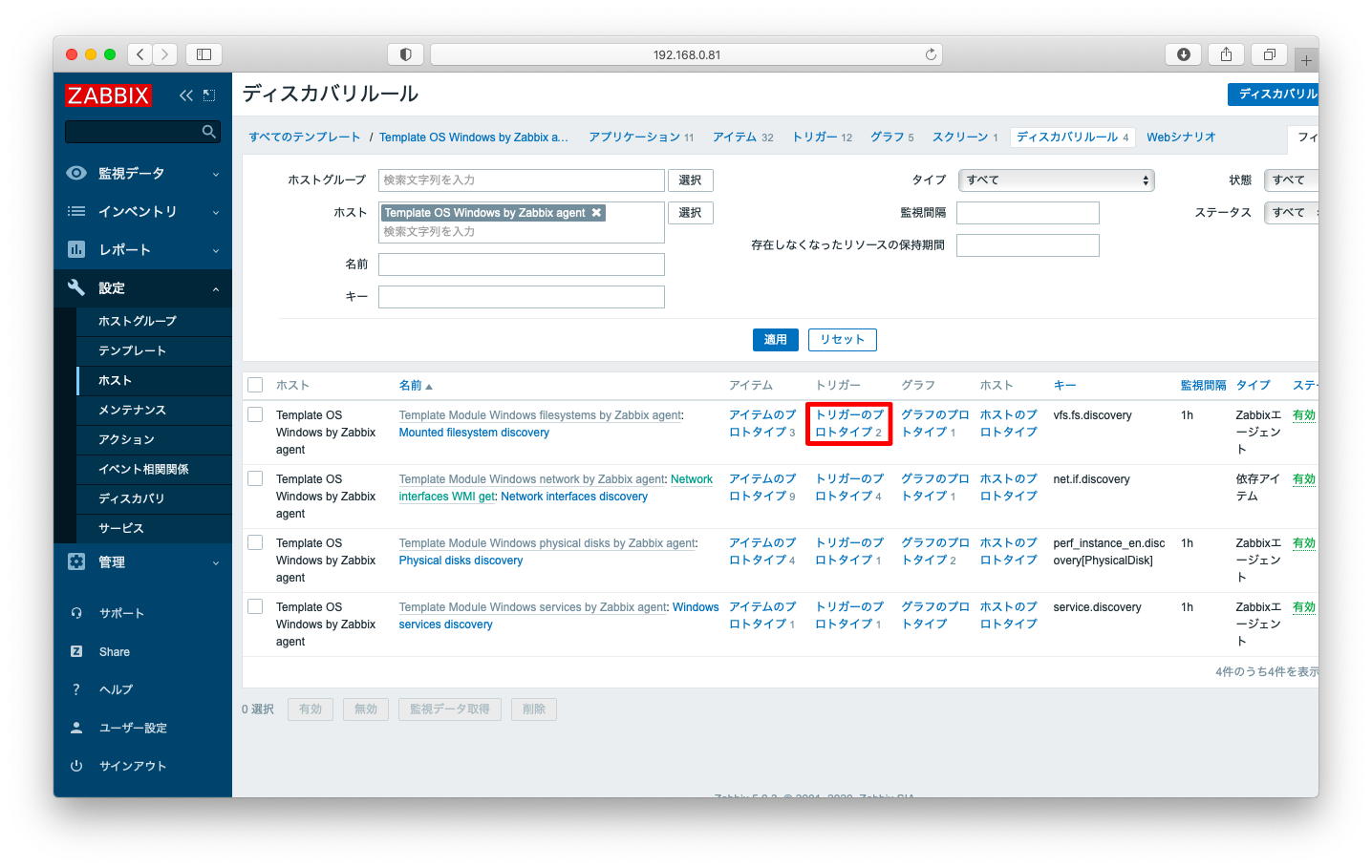
「トリガー名」の順に押下する事で、閾値変更画面に遷移する事ができます。
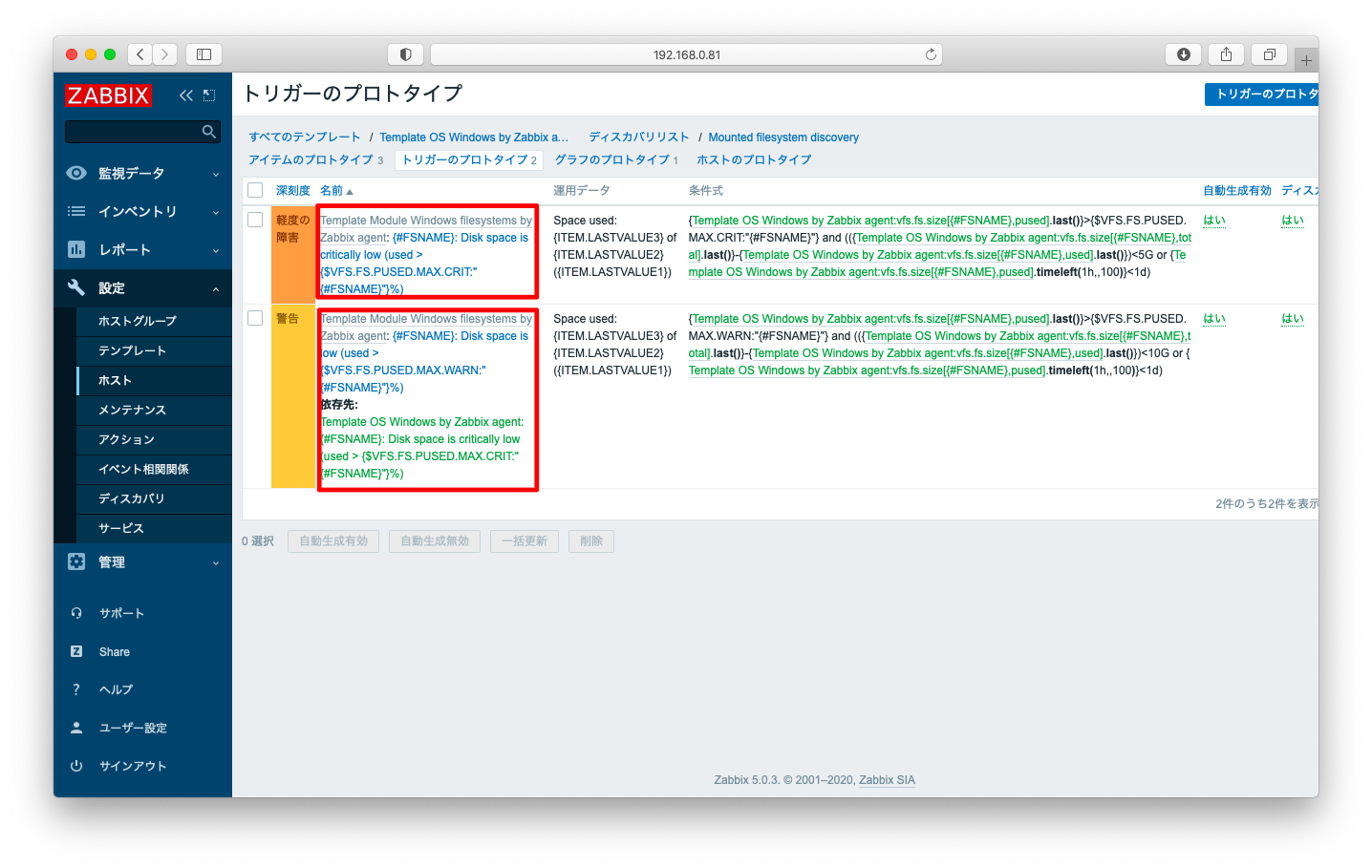
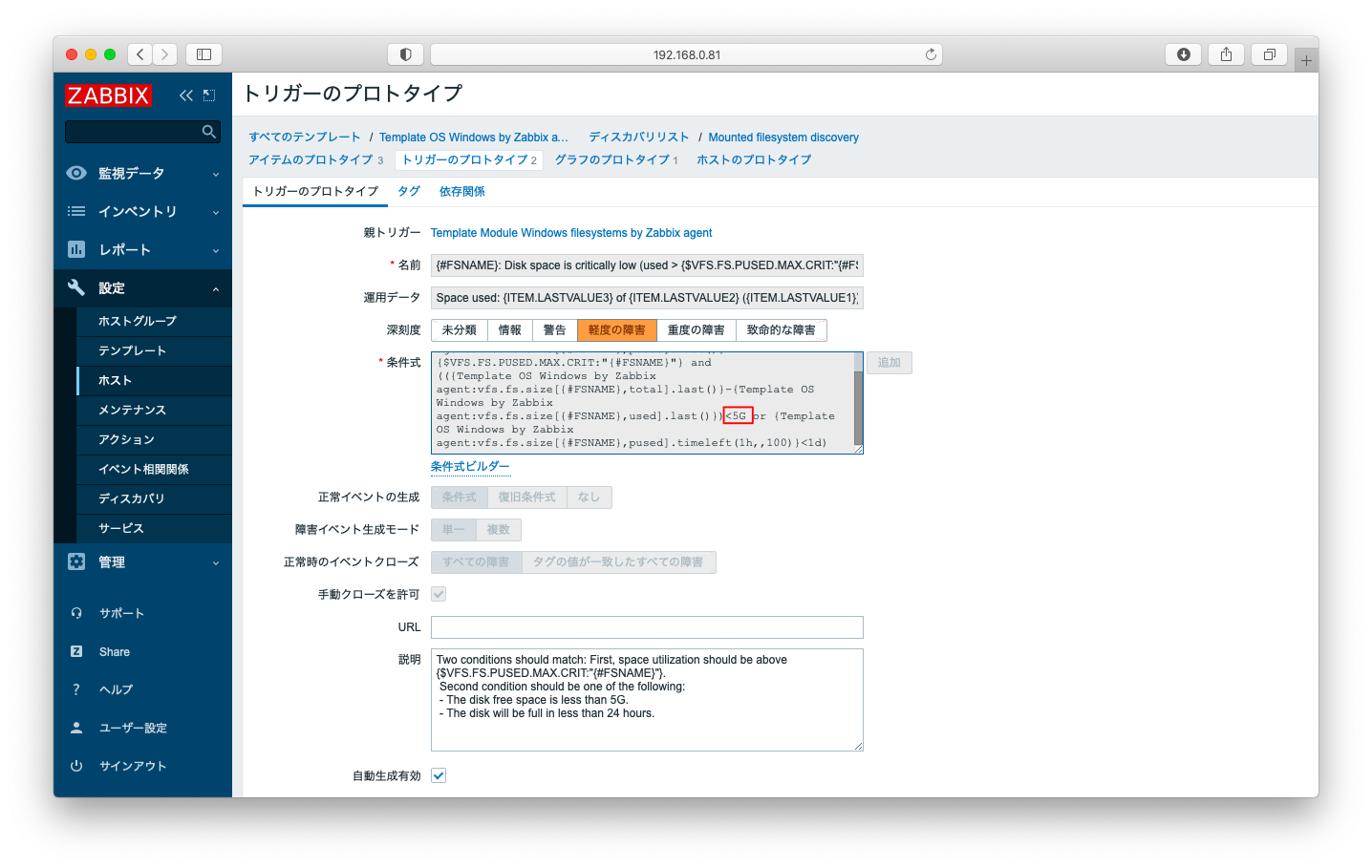
条件式の数値の部分を適宜変更する事で、ディスクリソース監視の閾値を変更できます。
メモリリソース監視 Linuxの場合
Zabbixはアイテム「vm.memory.size」を使用して、メモリの監視を行う事ができます。
詳細は公式ドキュメントのAppendix/Items配下(英語版 日本語版)を参照ください。
日本語マニュアルはZabbix 2.2で更新が止まっており、最新情報の入手をするには英語版マニュアルの参照が必要です。
| パラメタ | 説明 |
|---|---|
| active | 現在使用されている、または最近使用されたメモリで、RAMにあるもの |
| anon | ファイルと関係ないメモリ(ファイルから再読み込みできないメモリ) |
| available | inactive + cached + free のメモリ |
| buffers | ファイルシステムのメタデータのようなもののキャッシュ |
| cached | さまざまなもののキャッシュ |
| exec | 実行コード。通常、(プログラム)ファイルから実行されます |
| file | 最近アクセスされたファイルのコンテンツのキャッシュ |
| free | メモリを必要とするどんな項目に対しても使用できるメモリ |
| inactive | 使用されていないメモリ |
| pavailable | 「total」に対するinactive + cached + free のメモリ |
| pinned | 「wired」と同じです |
| pused | 「total」に対するactive + wired のメモリ |
| shared | 複数のプロセスによって同時にアクセスできるメモリ |
| slab | total amount of memory used by the kernel to cache data structures for its own use |
| total | 使用可能な物理メモリの合計 |
| used | active + wired のメモリ |
| wired | 常にRAMにあると示されているメモリ。このメモリはディスクには移動されません |
初期設定の「Template OS Linux by Zabbix agent」ではavailableとpavailableが監視対象になっています。
多くの場合は、この情報量で十分かと思われますが、shared, cachedなどの詳細な情報含めて情報を残したい方は、適宜、テンプレートを改造して下さい。
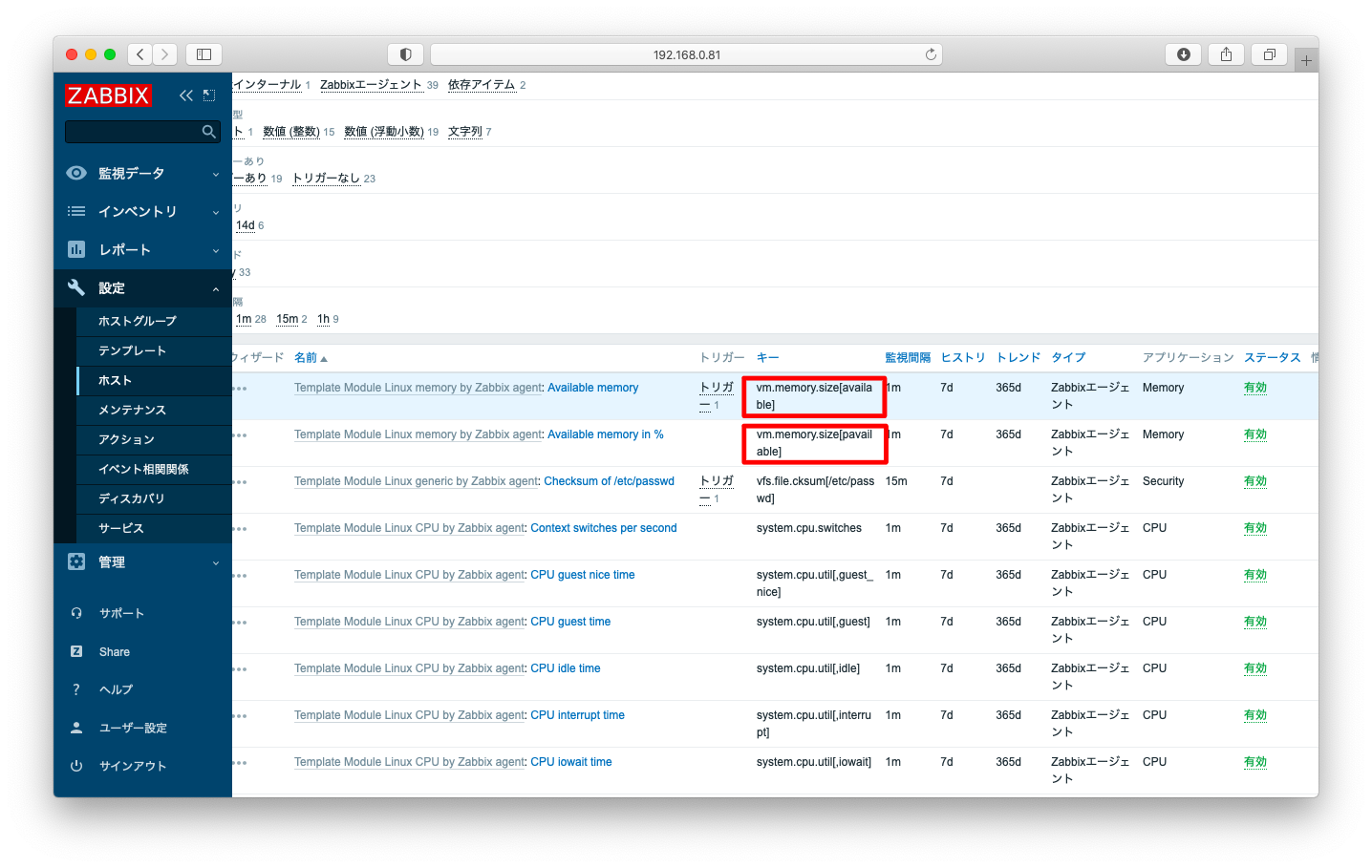
トリガーを発生させる条件を見てみましょう。availableが{$MEMORY.AVAILABLE.MIN}を下回った場合にアラートが発報されます。
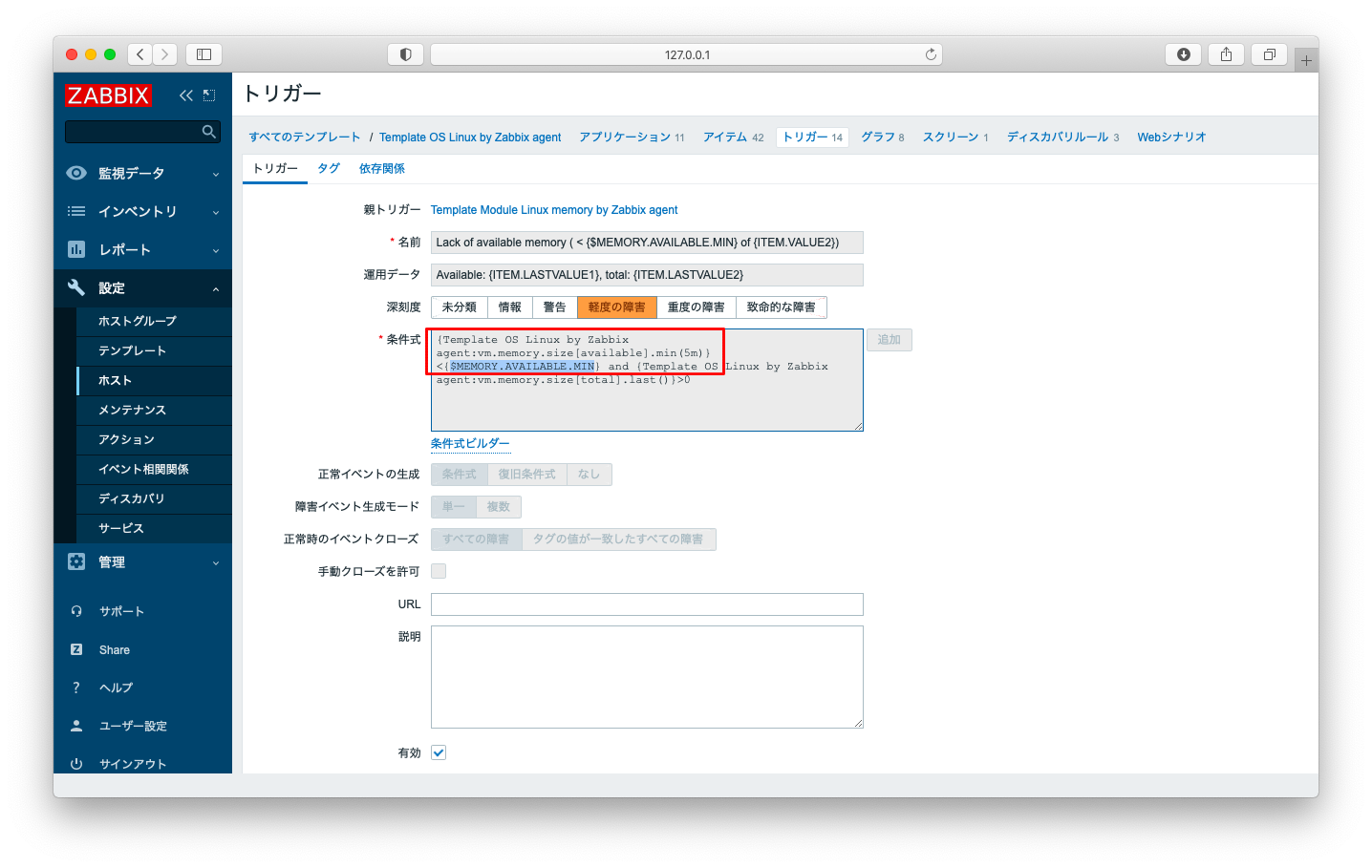
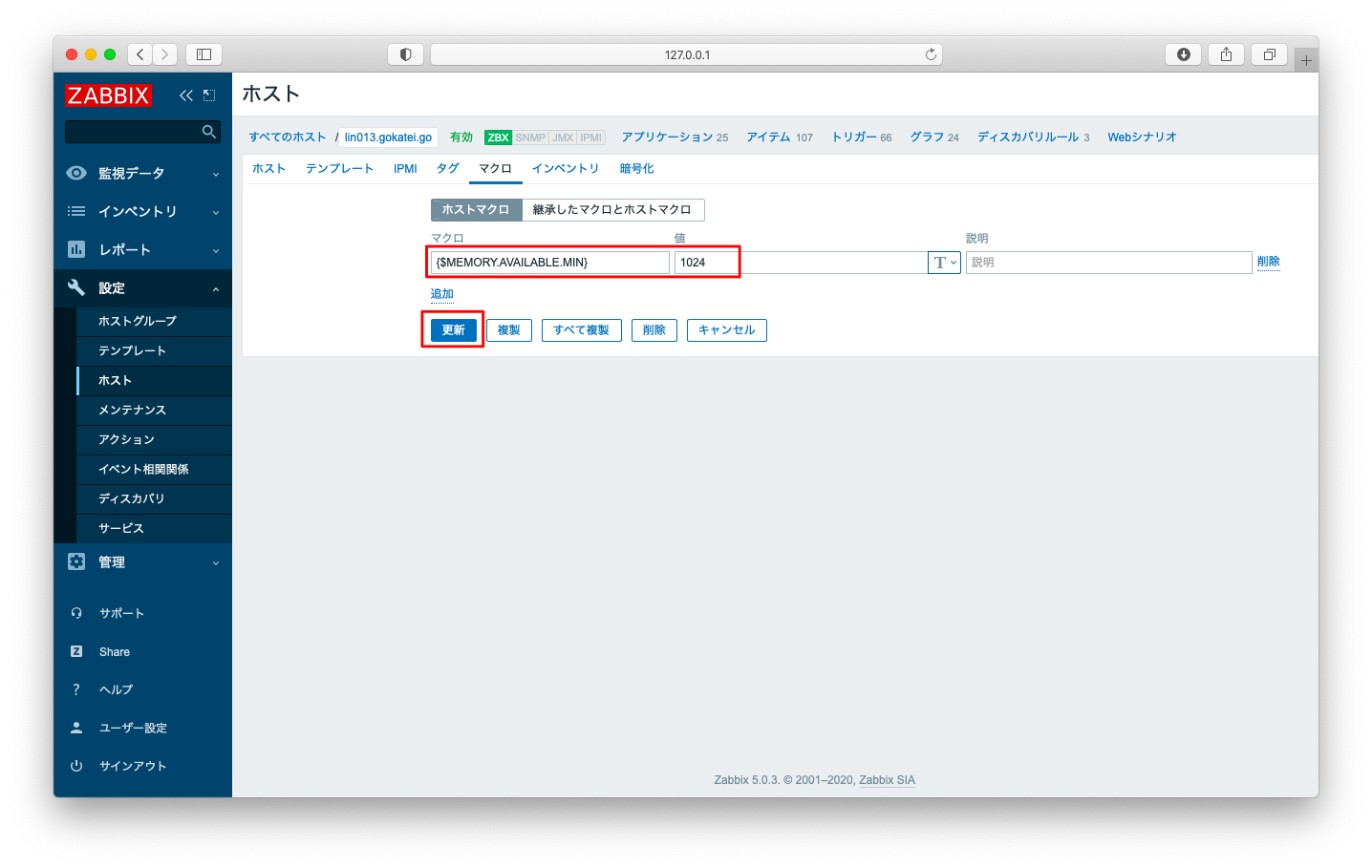
前述の{$MEMORY.AVAILABLE.MIN}のような「{$」で始まる変数のような記述は、Zabbixでは「マクロ」と呼びます。マクロはホスト単位やテンプレート単位で設定が可能です。
ホストの設定画面の「マクロ」タブで、以下のような値を入力し「更新」を押下すると、マクロを設定できます。
メモリリソース監視 Windowsの場合
Windowsの監視設定もLinux同様に、pavailableの監視がお勧めです。
しかし、Windows版のzabbix agentはLinuxに比べてサポートされる監視項目が少なめです。メモリ監視でどのような値が取得できるかはOSによって異なり、詳細は公式ドキュメントのAppendix/Items配下(英語版 日本語版)にもまとめられています。
もし、マニュアルを読むのが手間ならば、zabbix_getコマンドを利用して実際に値が取得できるかどうかを確かめる方法もあります。サポートされない監視項目の場合、以下のようにZBX_NOTSUPPORTEDと表示されます。
[root@localhost ~]# zabbix_get -s 52.7.67.17 -k vm.memory.size[pavailable] 59.772405 [root@localhost ~]# zabbix_get -s 52.7.67.17 -k vm.memory.size[pfree] ZBX_NOTSUPPORTED [root@localhost ~]# zabbix_get -s 52.7.67.17 -k vm.memory.size[free] 641413120 [root@localhost ~]# zabbix_get -s 52.7.67.17 -k vm.memory.size[used] 431902720 [root@localhost ~]# zabbix_get -s 52.7.67.17 -k vm.memory.size[available] 641425408 [root@localhost ~]#
全体的なCPUリソース監視 Linuxの場合
アイテム「system.cpu.util」を利用する事で、CPUの監視が可能です。system.cpu.utilは、cpu, type, modeの3つの引数を取ります。
system.cpu.util[<cpu>,<type>,<mode>]
それぞれの引数の意味は以下の通りです。
| 引数 | 設定可能な値 | 説明 |
|---|---|---|
| cpu | all, 0, 1, 2, 3… | 監視対象となるCPU番号を指定します。省略時は、全CPUの平均を意味するallとなります。 |
| type | idle, nice, user, system, iowait, interrupt, softirq, steal | CPUがどんな用途に使用されていたのかを指定します。 |
| mode | avg1, avg5, avg15 | 1分間、5分間, 15分間の平均値を返します。 |
最も重要な監視項目はidleです。idleは遊んでいる時間を表し「100 – idle」をCPU使用率と考えても良いでしょう。idleを監視するには、アイテム作成の画面で、キーに「system.cpu.util[,idle,]」を指定します。
なお、この監視項目は「Template OS Linux by Zabbix agent」の初期設定の中に含まれていますので、明示的な設定をしなくても、テンプレートを適用するだけで監視が可能です。
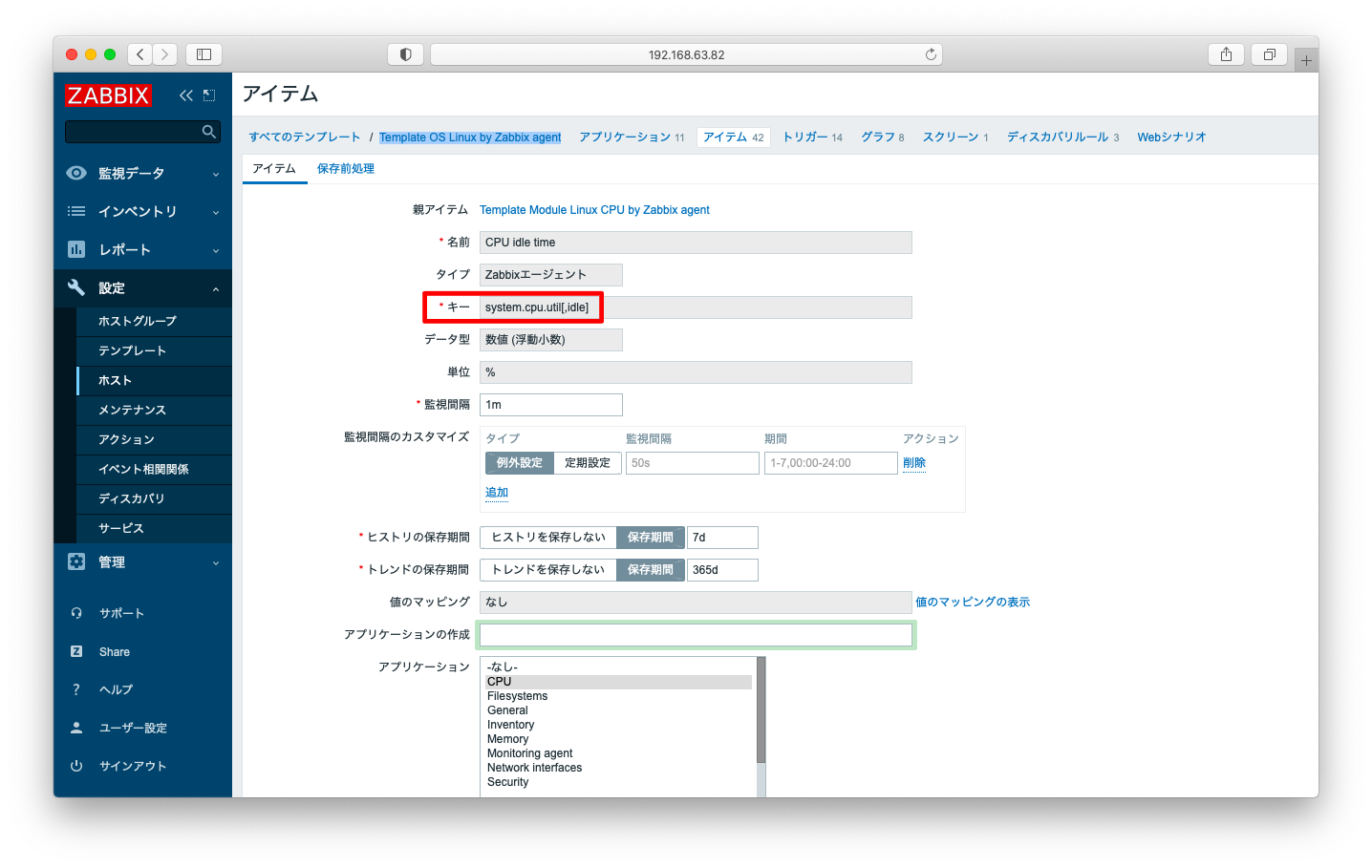
「Template OS Linux by Zabbix agent」には、idle, nice, user, system等を重ね合わせたグラフも存在します。
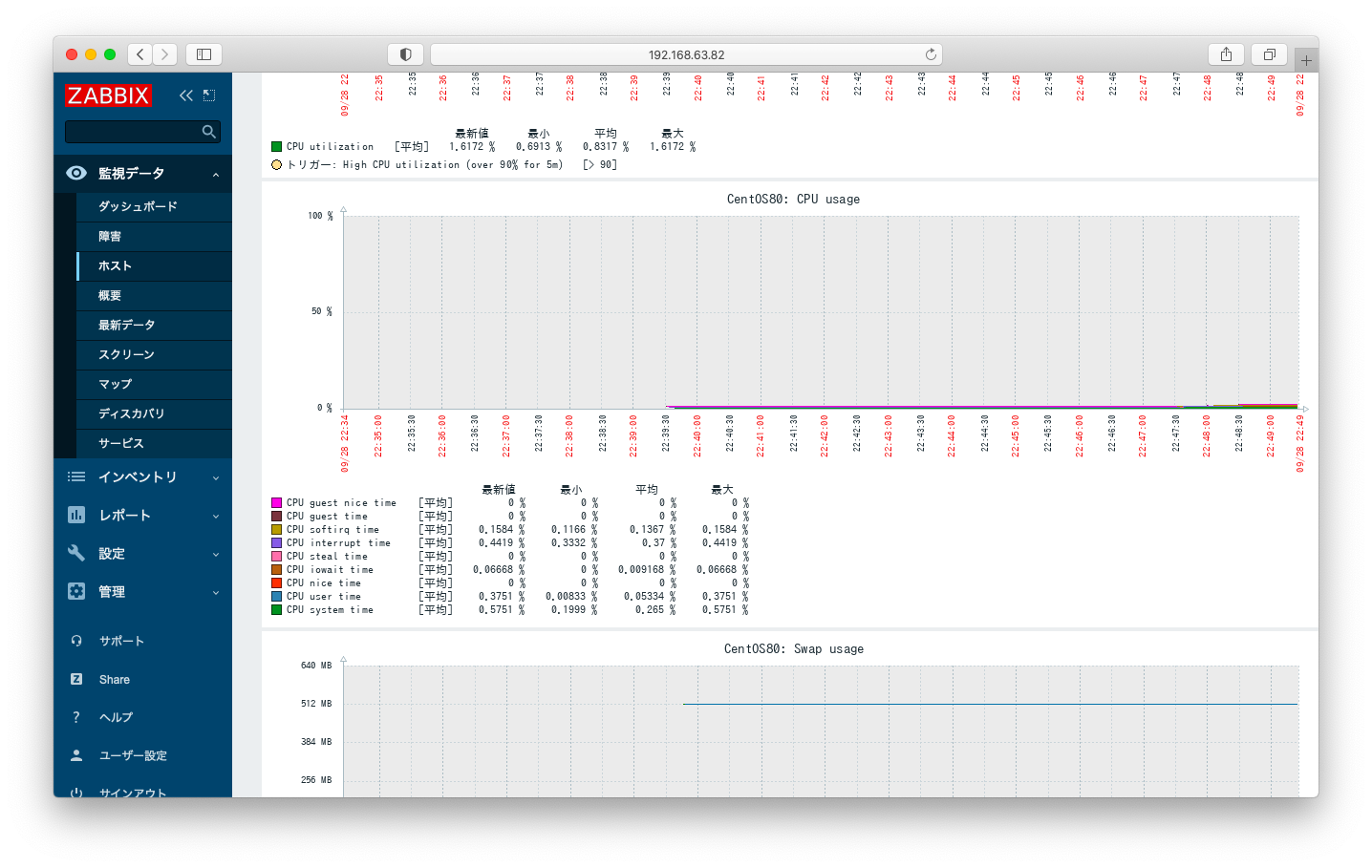
もしCPU使用率を監視するならば、「Template OS Linux by Zabbix agent」のデフォルト設定を上手に利用しましょう。マクロ「{$CPU.UTIL.CRIT}」を定義するだけでCPU監視が可能になります。なお、system.cpu.utilを引数なしで実行した場合は、CPUのuserの値が返されます。もし、デフォルト設定のuserの値を監視する挙動が運用に合わないならば、この部分を適宜変更しましょう。
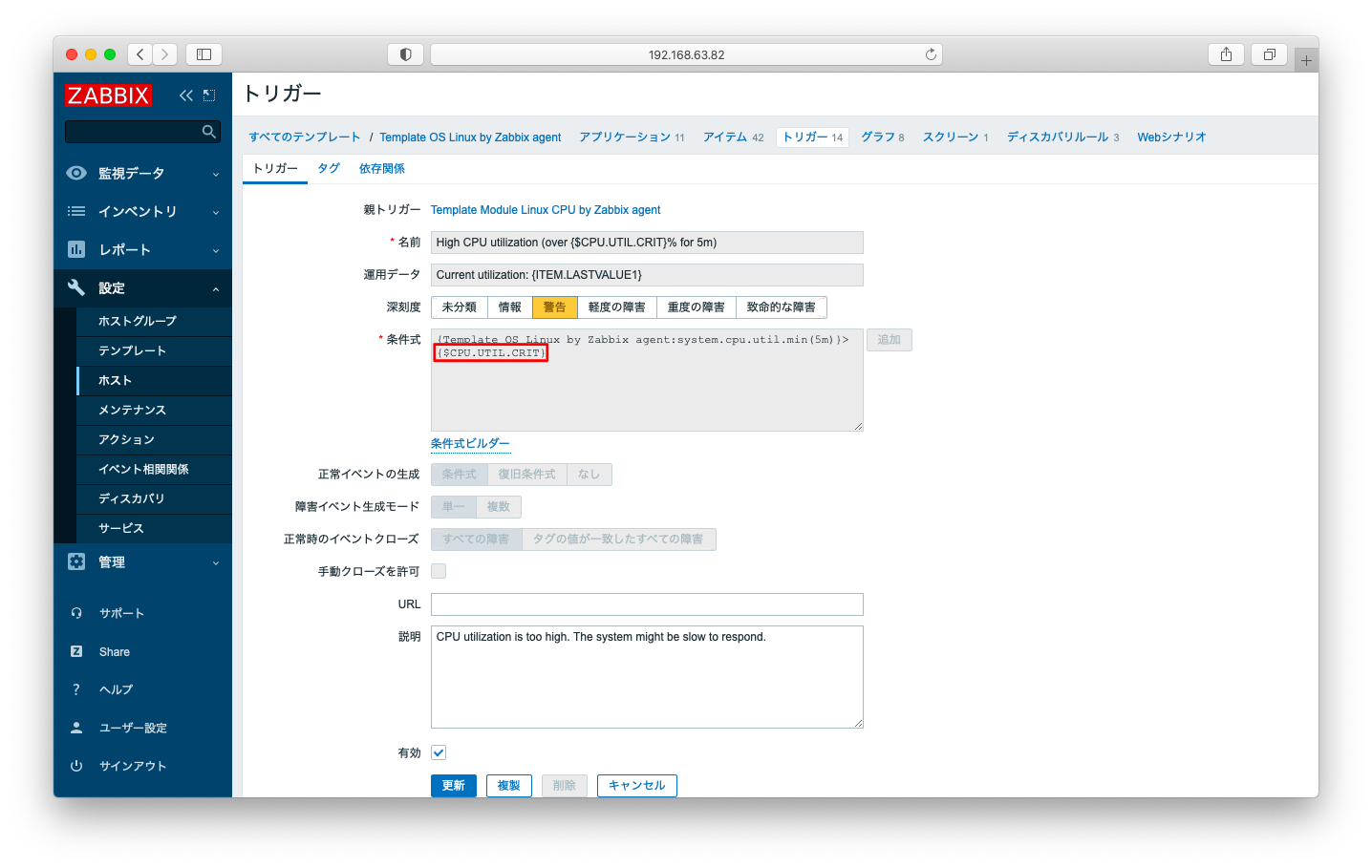
CPU監視はバッチ処理(ジョブ)実行時にアラートが発報されやすい性質がありますので、監視としての実運用を回すのが難しい項目です。監視を行ったとしても、不要なアラートが多く「運用担当者を疲弊させる」状態に繋がりうる可能性があります。
サーバの負荷上昇はロードアベレージで検知し、CPUはボトルネックを分析するための「情報」として利用するのも一案です。
全体的なCPUリソース監視 Windowsの場合
WindowsのCPU(タスク管理)には、idle, nice, user, system, iowait, interrupt, softirq, stealという概念が存在しません。Windows版zabbix_agentはsystemを指定する事でCPU使用率を返します。Windows版zabbix_agentにidle, nice, user, iowait, interrupt, softirq, stealをサポートしていません。
WindowsのCPU使用率を監視するには、アイテム作成の画面でキーに「system.cpu.util[,system,]」を指定します。
この監視項目は「Template Module Windows CPU by Zabbix agent」の初期設定の中に含まれていますので、明示的な設定をしなくても、テンプレートを適用するだけで監視が可能です。
Windows機に対してsystem.cpu.utilを引数なしで監視すると、CPUのsystemの値が返されます。
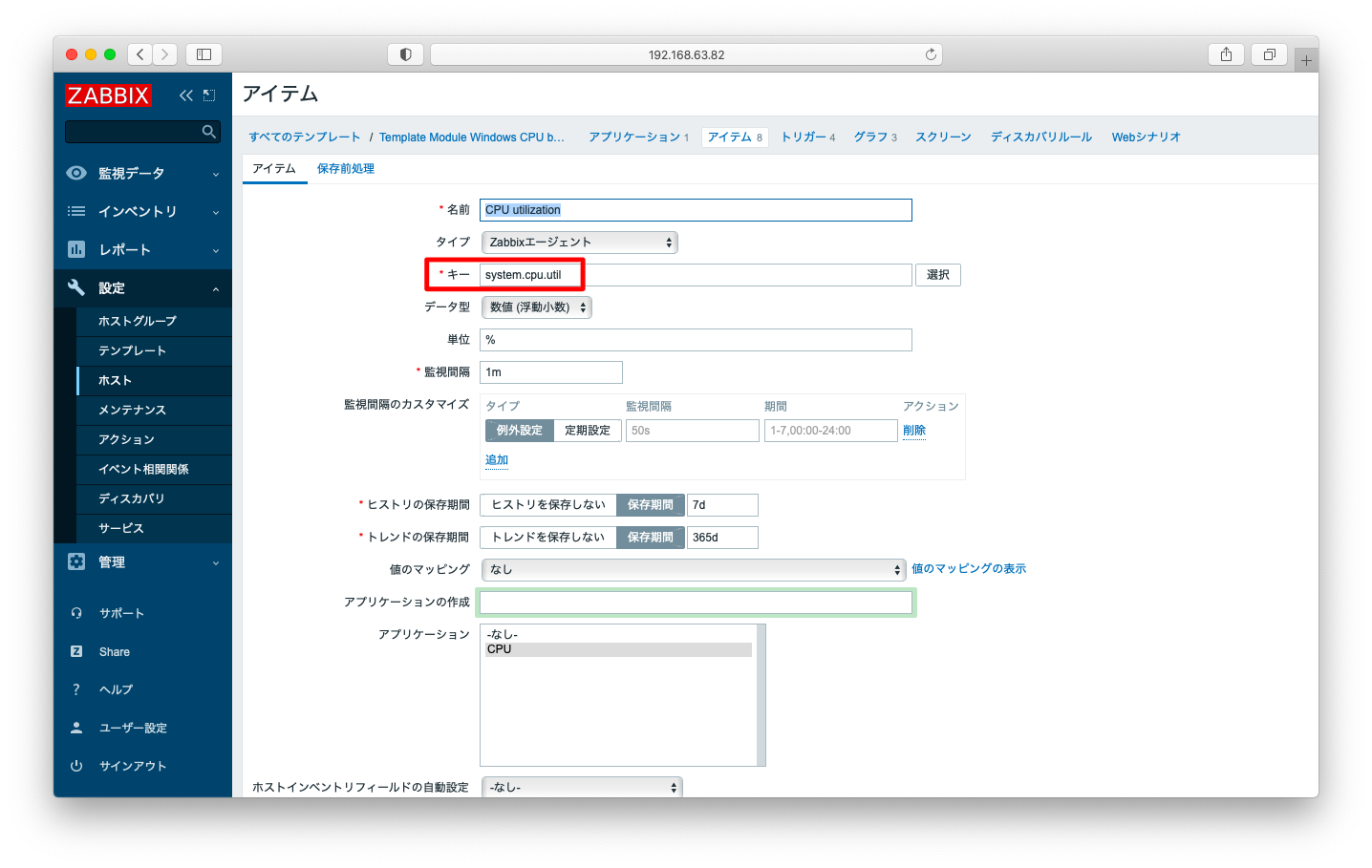
個別CPUリソース監視
アプリケーションの作りによっては個々のCPUに処理が偏る事がよくあります。CPU全体の負荷は高くありませんが、1つのCPUの使用率が100%になっているため、処理性能が向上しない事がよくあります。
このようなボトルネックを分析するには、CPUを個別に監視する必要があります。人海戦術をとる事ができる会社ならば、CPUコア数毎にZabbixテンプレートを作成して監視設定を割り当てても良いでしょう。一方、小数精鋭戦略を取る会社ならば、ローレベルディスカバリを利用して自動的に監視設定を行うと良いでしょう。
プロセス監視
アイテム「proc.num」を利用する事で、CPUの監視が可能です。proc.numは、name, user, state, cmdlineの4つの引数を取ります。
proc.num[<name>,<user>,<state>,<cmdline>]
それぞれの引数の意味は以下の通りです。
| 引数 | 説明 |
|---|---|
| name | プロセス名を指定します。例えばtd-agentのプロセス名は”ruby”になりますが、このような重複の恐れがあるようなプロセス名は、第四引数のcmdlineを使用した方が無難です。 |
| user | プロセスを実行するユーザ名を指定します。 |
| state | all, run, sleep, zombのいずれかを指定します。 |
| cmdline | プロセスを実行する際のコマンドを指定します。正規表現を利用する事も可能です。 |
実運用として、基本的に第一引数name, 第四引数cmdlineのいずれかか両方を使用すると良いでしょう。
第一引数nameを使用する時はプロセス名を指定します。プロセス名は/proc/<プロセスID>/statに格納されています。例えば、td-agentのプロセス名を調べるコマンド例は以下のようになります。
[root@localhost ~]# ps aux | grep td- root 30234 0.0 0.9 201268 17352 ? Sl 22:28 0:00 /opt/td-agent/embedded/bin/ruby /usr/sbin/td-agent --group root --log /var/log/td-agent/td-agent.log --daemon /var/run/td-agent/td-agent.pid root 30237 3.2 1.1 223360 22380 ? Sl 22:28 0:00 /opt/td-agent/embedded/bin/ruby /usr/sbin/td-agent --group root --log /var/log/td-agent/td-agent.log --daemon /var/run/td-agent/td-agent.pid root 30246 0.0 0.0 103252 844 pts/0 S+ 22:28 0:00 grep td- [root@localhost ~]# [root@localhost ~]# [root@localhost ~]# cat /proc/30234/stat 30234 (ruby) S 1 30231 30231 0 -1 4202560 402 0 0 0 0 0 0 0 20 0 2 0 1055894979 206098432 4338 18446744073709551615 4194304 4196980 140737480751328 140737480743776 217239843501 0 0 4096 33713735 18446744073709551615 0 0 17 2 0 0 0 0 0 [root@localhost ~]#
td-agentの監視を行うには、以下のように、proc.numの第一引数<name>にrubyを指定します。
[root@localhost ~]# zabbix_get -s 54.XX.XX.XX -k proc.num 2 [root@localhost ~]#
但し、rubyのようなプロセス名は重複の恐れがあります。例えば、rubyで作成したバッチ処理(ジョブ)もproc.numでカウントされてしまいます。重複の恐れがある場合は、第四引数cmdlineと併用すると良いでしょう。実行例は以下の通りです。
[root@localhost ~]# zabbix_get -s 54.XX.XX.XX -k proc.num 2 [root@localhost ~]#
私個人の個人的な経験ですが、第一引数
サービス監視 (Windows限定)
アイテム「service_state」を利用する事で、Windowsのサービス監視が可能です。service_stateの構文は以下の通りで、引数は<service>のみです。
service_state[<name>]
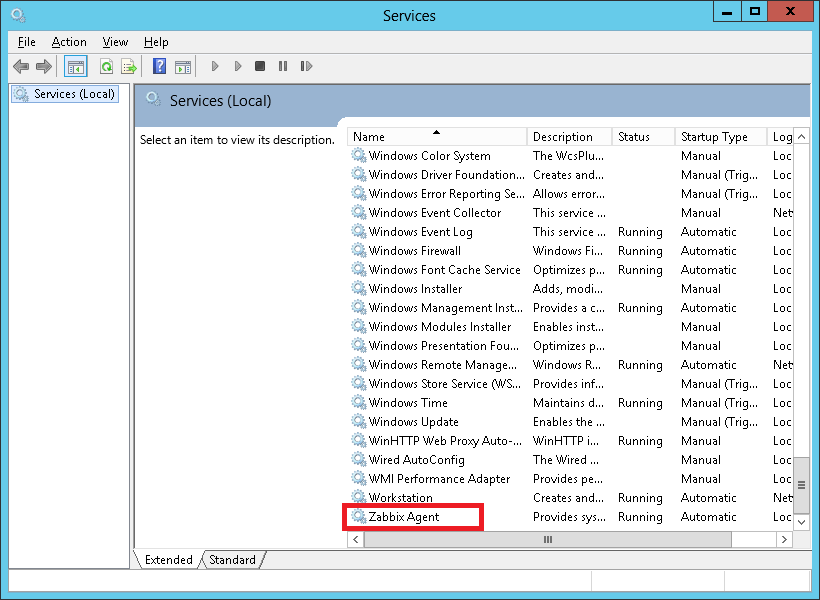
引数<service>にはサービス名を入力します。サービスはWindowsのサービスコンソールの画面から確認する事ができます。例えば、以下のような画面ならば「Zabbix Agent」がサービス名になります。
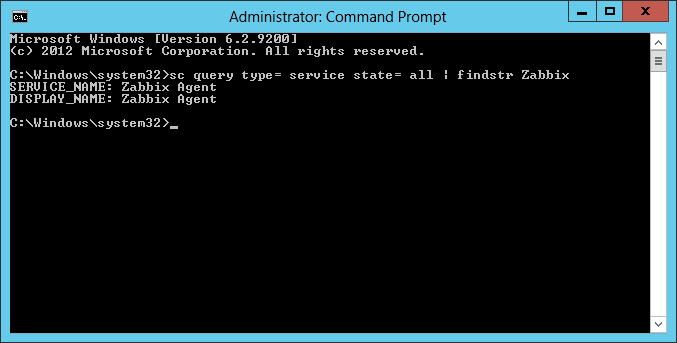
GUIを使用するのに抵抗がある方は、コマンドプロンプトでscコマンドをご利用ください。実効例は以下の通りです。findstrはLinuxにおけるgrepに相当するコマンドです。
C:\Windows\system32>sc query type= service state= all | findstr Zabbix SERVICE_NAME: Zabbix Agent DISPLAY_NAME: Zabbix Agent C:\Windows\system32>
ログ監視 (動けば良いレベル)
Zabbixのログ監視の仕組みは非常に難しいです。いきなり、実運用に耐えられる仕組みを設計するのは難しいので、まずは「動けば良いレベル」の設定例を紹介します。
設定を行う前にZabbix Agentの設定を確認します。ログ監視は、Zabbix Agentがログを定期的に監視し、監視結果をZabbix AgentからZabbix ServerへZabbix Trapを用いて送信します。Zabbix Serverは、Zabbix Trap内に含まれたZabbixホスト名を元に、どのサーバから送られたログなのかを判断します。ですので、設定を行う前に以下2点の確認が必要となります。
- Zabbix Trapの宛先が想定通りである事
- Zabbixホスト名が想定通りである事
ログ監視 – 事前確認(1) Zabbix Trapの宛先
/etc/zabbix/zabbix_agentd.confのServerActiveはZabbix Trapの宛先を表します。ServerActiveが想定通りの宛先である事を確認します。
# vi /etc/zabbix/zabbix_agentd.conf ### Option: ServerActive # List of comma delimited IP:port (or hostname:port) pairs of Zabbix servers for active checks. # If port is not specified, default port is used. # IPv6 addresses must be enclosed in square brackets if port for that host is specified. # If port is not specified, square brackets for IPv6 addresses are optional. # If this parameter is not specified, active checks are disabled. # Example: ServerActive=127.0.0.1:20051,zabbix.domain,[::1]:30051,::1,[12fc::1] # # Mandatory: no # Default: # ServerActive= ServerActive=192.168.63.82
ログ監視 – 事前確認(2) Zabbixホスト名
Zabbix AgentはZabbix Trapを送信する際に、Zabbix Trapのメッセージ内にホスト名を格納します。このホスト名は、OSに設定されるホスト名でもなく、名前解決(DNS)で使用されるホスト名でもありません。/etc/zabbix/zabbix_agentd.confに設定されたHostnameです。
# vi /etc/zabbix/zabbix_agentd.conf ### Option: Hostname # Unique, case sensitive hostname. # Required for active checks and must match hostname as configured on the server. # Value is acquired from HostnameItem if undefined. # # Mandatory: no # Default: # Hostname= Hostname=CentOS80
このZabbixホスト名が、Zabbix Serverの「ホスト」の名前と一致している事を確認して下さい。
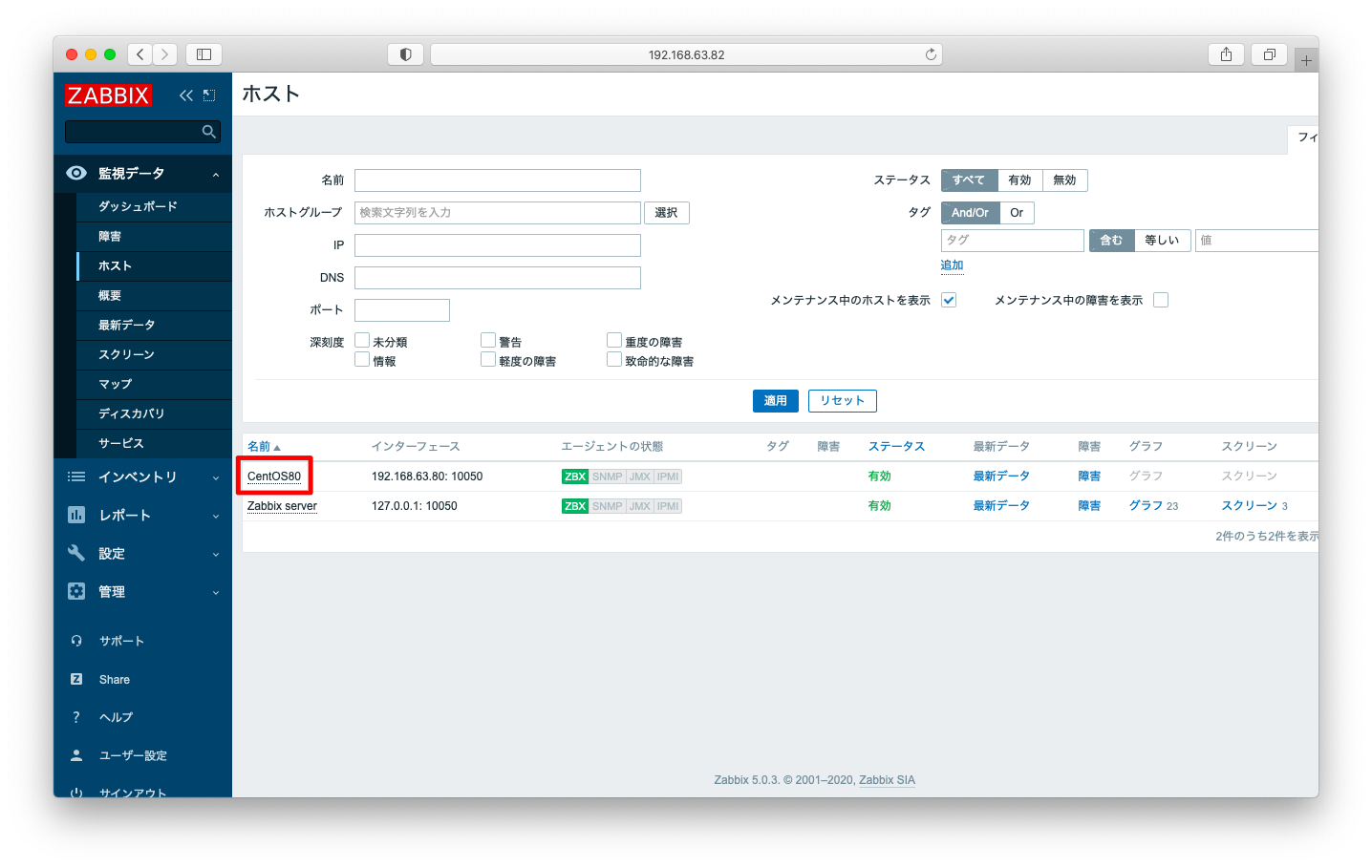
「/etc/zabbix/zabbix_agentd.confに設定されたHostname」と、「Zabbix Serverのホストの名前」が一致していない場合は、/var/log/zabbix/zabbix_server.logにcannot send list of active checks toとのログが出力されます。
[root@centos82 ~]# tail -n 3 /var/log/zabbix/zabbix_server.log 1390:20201003:192603.541 executing housekeeper 1390:20201003:192604.549 housekeeper [deleted 14190 hist/trends, 6962 items/triggers, 0 events, 0 problems, 0 sessions, 0 alarms, 0 audit, 0 records in 1.006224 sec, idle for 1 hour(s)] 1420:20201003:201807.812 cannot send list of active checks to "192.168.63.80": host [centos80.gokatei.go] not found
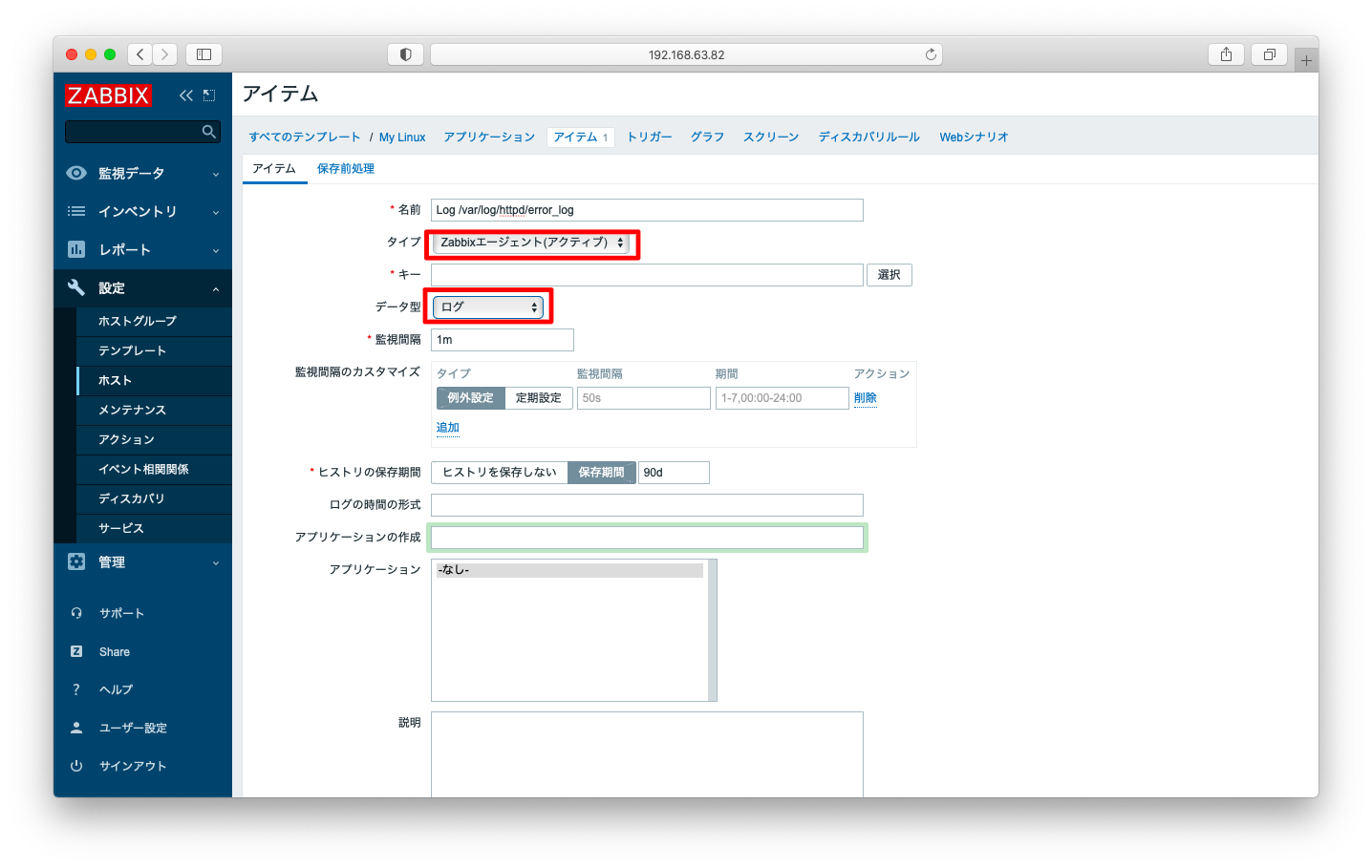
ログ監視 – アイテム設定
ログを監視するアイテムを作成します。タイプは「Zabbixエージェント(アクティブ)」を選び、データ型は「ログ」を選択して下さい。
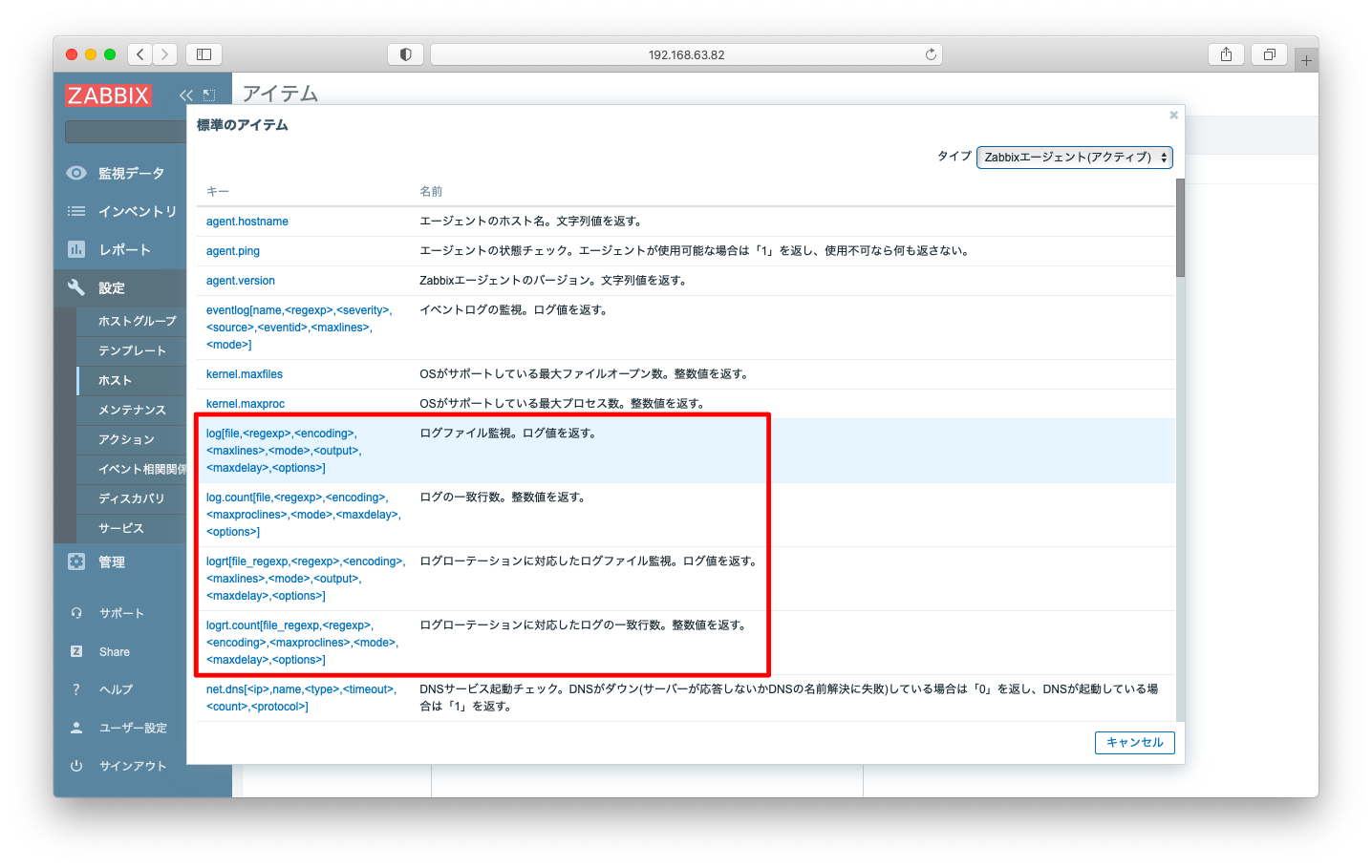
アイテムキー「log」や「logrt」を利用する事でログ監視が可能です。書式は以下の通りです。各引数の説明は省略します。
log[file,<regexp>,<encoding>,<maxlines>,<mode>,<output>,<maxdelay>,<options>] log.count[file,<regexp>,<encoding>,<maxproclines>,<mode>,<maxdelay>,<options>] logrt[file_regexp,<regexp>,<encoding>,<maxlines>,<mode>,<output>,<maxdelay>,<options>] logrt.count[file_regexp,<regexp>,<encoding>,<maxproclines>,<mode>,<maxdelay>,<options>]
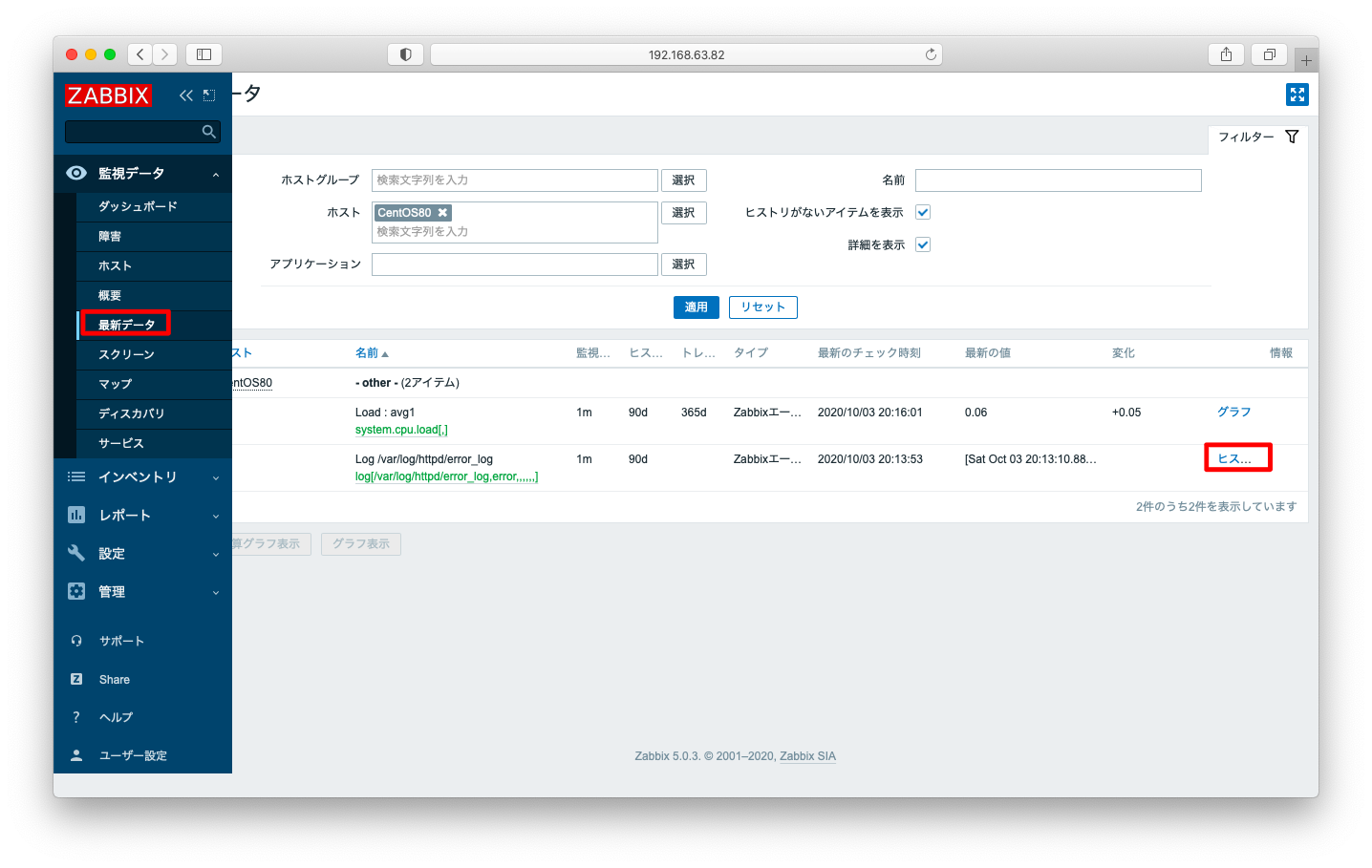
最新データの画面で対象のログが取得されている事を確認します。以下は、キーとして「log[/var/log/httpd/error_log,error,,,,,,]」を設定した場合の画面です。この画面で「ヒストリー」を押下すると、第二引数に指定した文字列「error」を含むログを参照する事ができます。
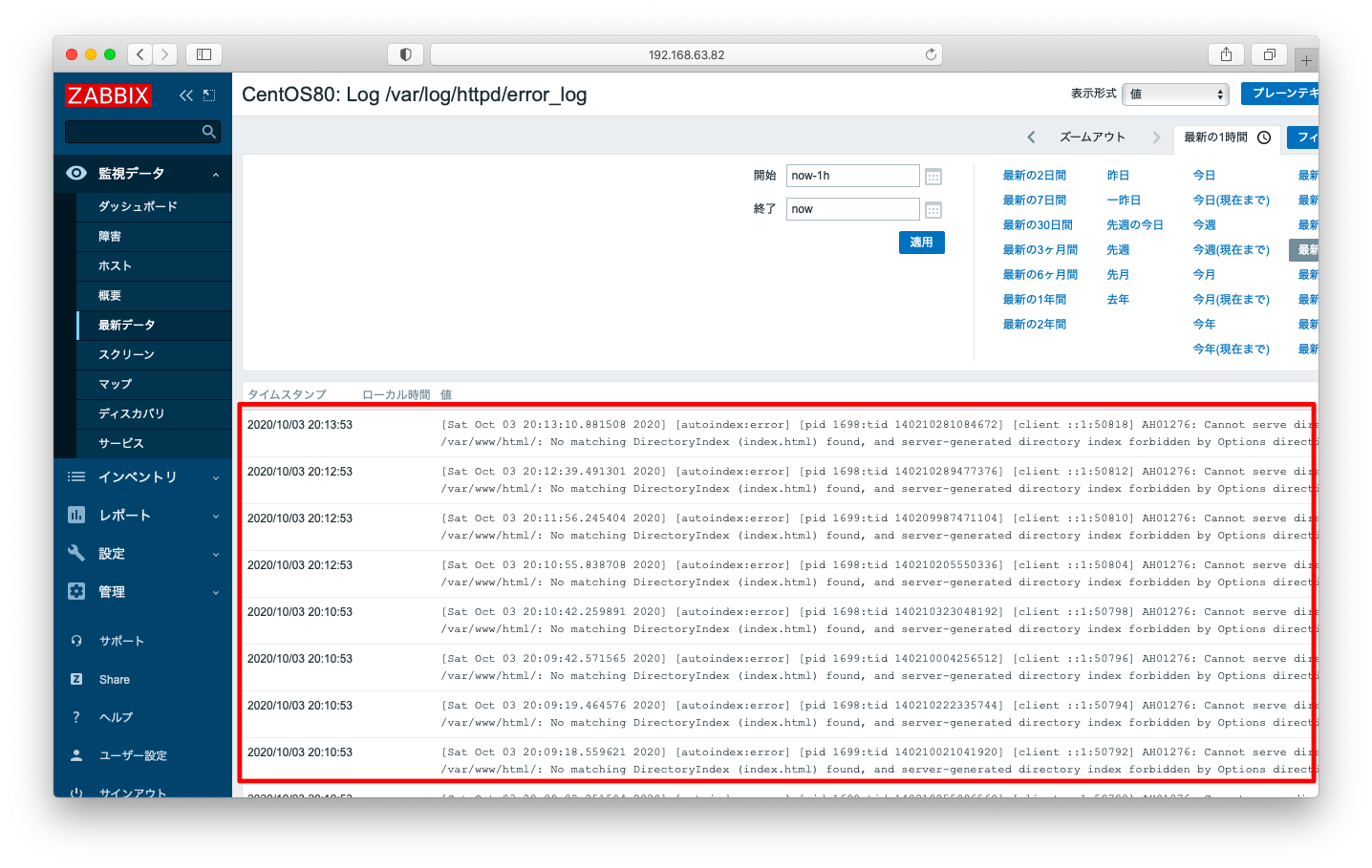
「error」を含むログが確認できます。
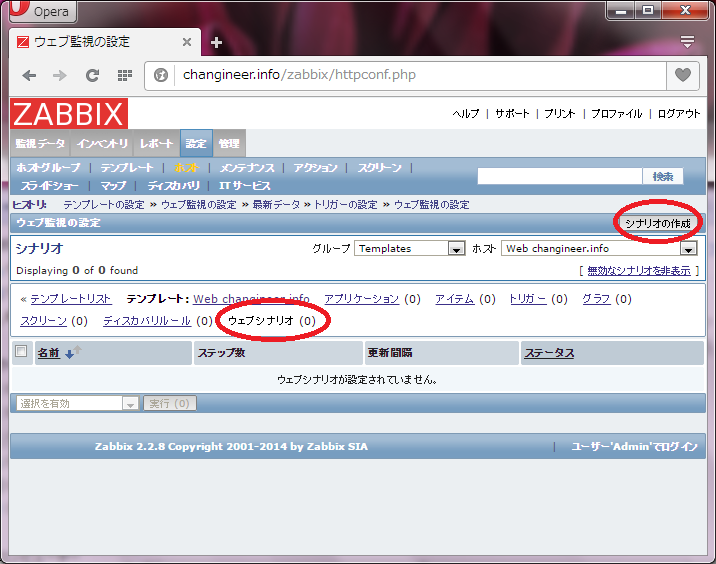
URL監視
ウェブシナリオの定義
URL監視を行うには「ウェブシナリオ」を定義する必要があります。「ウェブシナリオ」という名前がついていも、できる事はいわゆるURL監視です。seleniumのような一連の画面操作をテストする物ではございません。
テンプレートまたはホストの設定画面で、「ウェブシナリオ」「シナリオの作成」の順に押下します。
「名前」「更新間隔」「リトライ回数」を入力します。
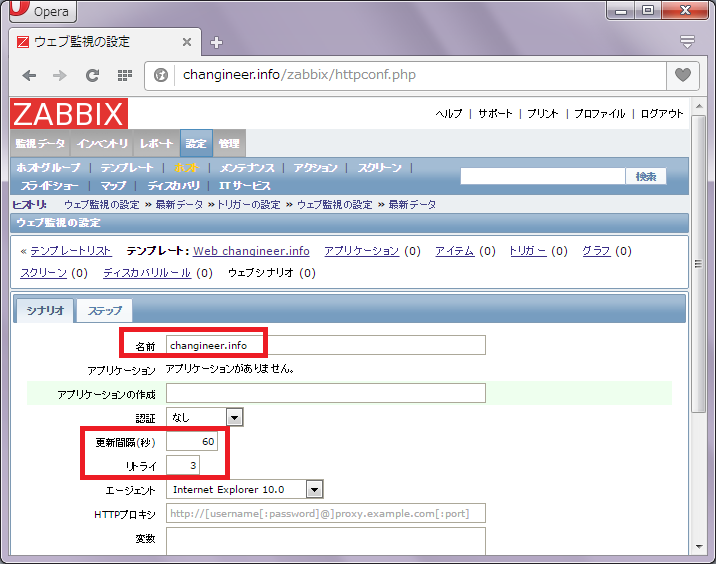
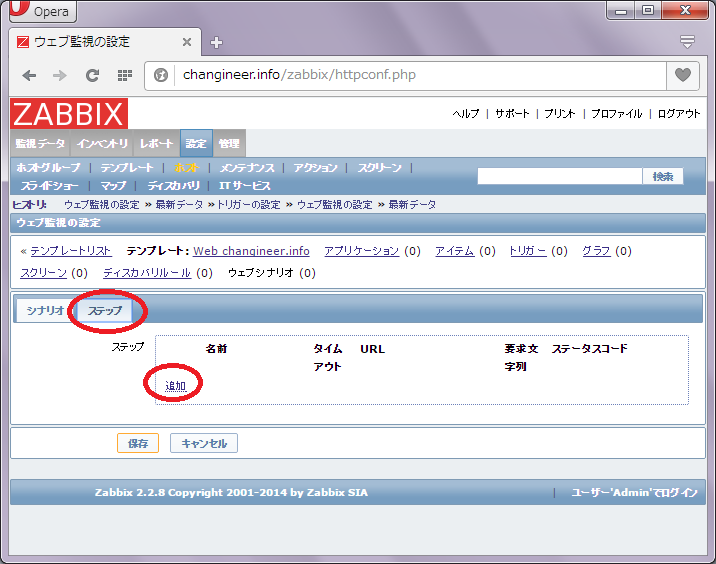
上記入力が完了しましたら、「ステップ」タブを押下します。「追加」ボタンから監視対象のURLを設定する事ができます。
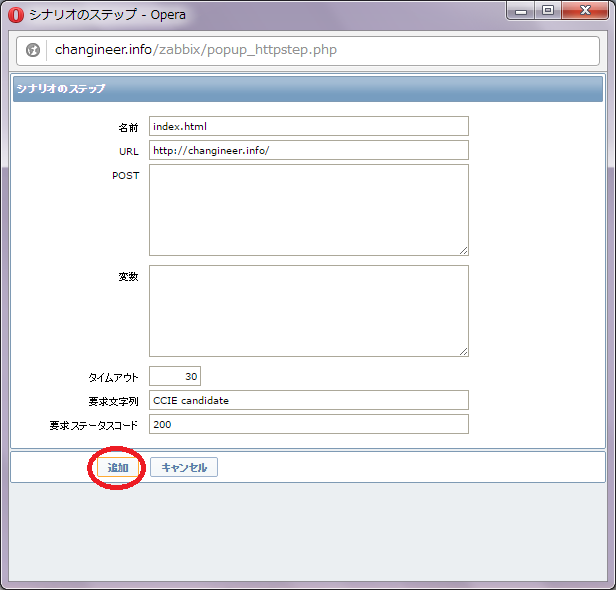
「名前」「URL」「要求ステータスコード」を入力し、「追加」を押下します。
「要求文字列」は監視結果に特定の文字列が含まれるかどうかを確認する処理です。要求文字列(監視文字列)を定義する事によって200番応答でもアプリケーションに異常がある場合を検知する事ができます。
私の経験則ですが、仕様変更の多いアプリの場合、要求文字列の変更によってアラートが発生し睡眠時間を奪われる事が多くなります。運用担当者の負担と相談しつつ、要求文字列を監視すべきかどうか判断するのが良いでしょう。ユーザ企業ならば、google analyticsのトラッキングIDなど仕様変更が発生しづらい文字列を選ぶという考え方もあります。
監視対象のURLが1つではない場合は、「追加」ボタンから監視対象のURLを増やす事ができます。
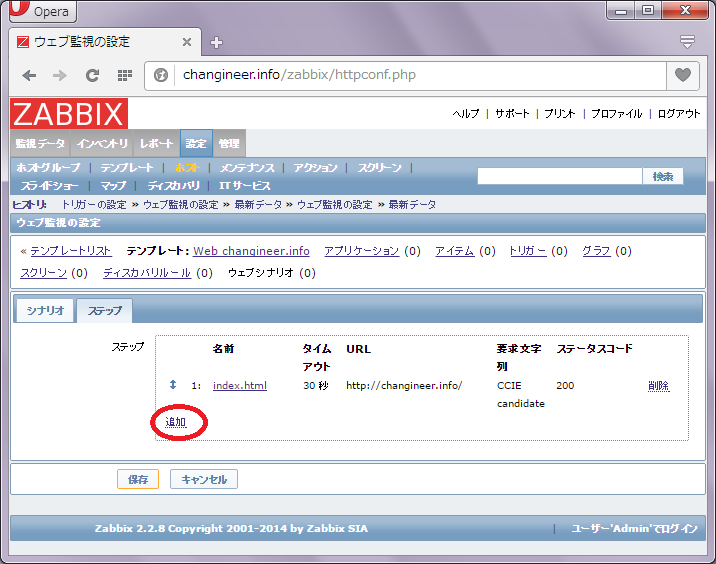
監視対象のURL定義が完了しましたら、「保存」を押下します。
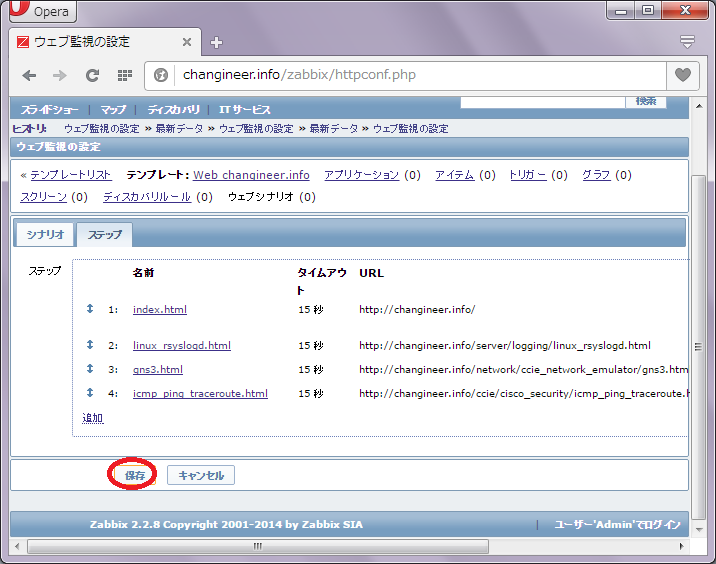
URL監視のトリガー定義
「ウェブシナリオ」を定義すると、自動的に以下のようなアイテム(監視項目)が作成されます。最低限監視すべきは、URL監視のエラー件数を表す「Failed step of senario」です。余力があれば、応答時間を表す「Response time for step」も監視しましょう。
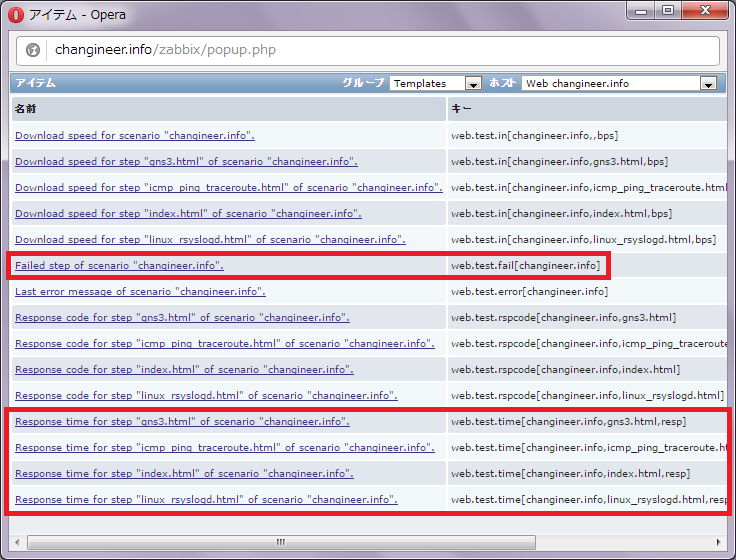
「Failed step of senario」はURL監視のエラー件数を表します。例えば、3つのURLを監視しており、そのうち1つがエラー(タイムアウト、ステータスコード期待値と異なる、要求文字列(監視文字列)未検知)となる場合、「Failed step of senario」は1を返します。
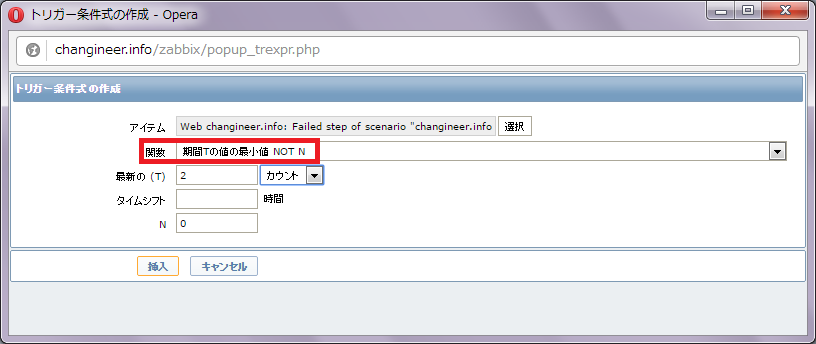
どれか1つでもエラーがある状態が一定期間続いた場合にエラーを返すようにしたいので、関数は「期間Tの値の最小値 NOT N」を選んでおくと良いでしょう。以下スクリーンショットのように設定しておく事で、URL監視のうちどれか1つでもエラーを返す状態が2回連続したら、アラートが発報されます。
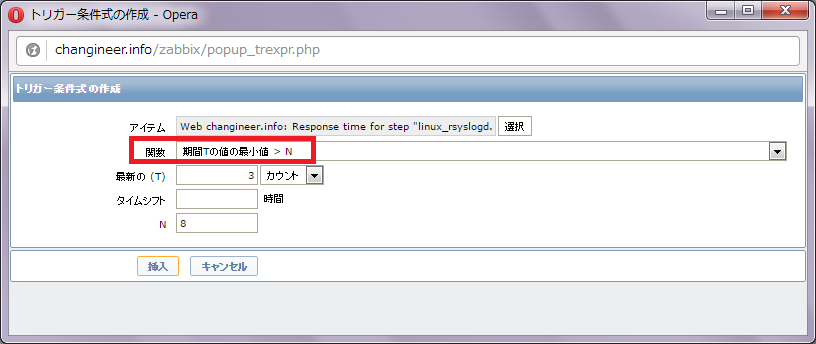
「Response time for step」は応答時間(レスポンスタイム)を表します。
応答時間(レスポンスタイム)が悪化している状態が一定期間続いた場合にエラーを返すようにしたいので、関数は「期間Tの値の最小値 > N」を選んでおくと良いでしょう。以下スクリーンショットのように設定しておく事で、応答時間(レスポンスタイム)が8秒を超える状態が3回連続したら、アラートが発報されます。