
Azureの仮想マシンスケールセットで仮想マシンをアップデートする場合は、全台同時にアップデートするか、1台ずつアップデート(ローリングアップデート)するかを選択できます。このページでは仮想マシンをアップデートする方法についてまとめます。
仮想マシンをアップデートするには正常性監視が設定されている事が前提になっています。正常性監視の方法は「Azure 仮想マシンスケールセット 正常性監視と自動インスタンス修復」を参照ください。
前提
公式ドキュメント
参考になる公式ドキュメントを以下に示します。
事前設定
以下、リソースグループを作成します。
az group create --name MyResourceGroup --location japaneast
仮想マシンスケールセットを作成します。仮想マシンはnginxインストール済かつ5台構成とします。
デフォルト設定のローリングアップデートは20%ずつアップグレードします。言い換えれば、デフォルト設定は5台以上の構成を前提としています(4台未満の構成では1台ロールアウトすると20%以上の台数減となります)。
az vmss create \
--resource-group MyResourceGroup \
--name MyScaleSet01 \
--image UbuntuLTS \
--vm-sku Standard_B1s \
--admin-username azureuser \
--ssh-key-values ~/.ssh/authorized_keys \
--instance-count 5 \
--custom-data /dev/stdin << EOF
#!/bin/bash
apt install -y nginx
echo "this is ${HOSTNAME}" > /var/www/html/index.html
EOF
正常性監視を定義します。正常性監視の実装方法は「Azure 仮想マシンスケールセット 正常性監視と自動インスタンス修復」を参照ください。
az vmss extension set \
--name ApplicationHealthLinux \
--publisher Microsoft.ManagedServices \
--version 1.0 \
--resource-group MyResourceGroup \
--vmss-name MyScaleSet01 \
--settings /dev/stdin << EOF
{
"protocol": "http",
"port": 80,
"requestPath": "/index.html"
}
EOF
az vmss update-instances \
--resource-group MyResourceGroup \
--name MyScaleSet01 \
--instance-ids '*'
アップグレードポリシー概要
仮想マシンスケールセットの仮想マシンに対して設定変更をすると、その設定変更反映のタイミングはアップグレードポリシーに従います。アップグレードポリシーは以下3通りの設定が可能です。
| アップグレードポリシー | 説明 |
|---|---|
| 手動 | 明示的なアップグレード操作が行われたタイミングで更新される |
| 自動 | 全台同時にアップグレードされる |
| ローリング | 一定台数ずつアップグレードされる |
アップグレードポリシーの動作確認
手動
1台ずつのアップグレード
アップグレードポリシーのデフォルト設定は「手動」です。「手動」の場合は、以下のようなコマンドを実行すると、仮想マシン1台をアップグレードできます。詳細な操作方法は「Azure 仮想マシンスケールセット 手動スケール」を参照ください。
az vmss update-instances \ --resource-group <リソースグループ名> \ --name <仮想マシンスケールセット名> \ --instance-ids <インスタンスID>
全台同時のアップグレード
全台同時にアップグレードするには、引数instance-idsに「*」を指定してください。
bashで使用する場合は、ブレース展開されないように’*’と指定します。
az vmss update-instances \ --resource-group <リソースグループ名> \ --name <仮想マシンスケールセット名> \ --instance-ids '*'
自動
アップグレードポリシーを「自動」に変更します。操作例は以下の通りです。
az vmss update \ --resource-group MyResourceGroup \ --name MyScaleSet01 \ --set upgradePolicy.mode=Automatic
動作確認のため、仮想マシンスケールセットの設定を変更します。実践ではアプリケーションのデプロイが多いかと思いますが、ここでは簡単に動作確認できるように、vm-skuの変更を例示します。
az vmss update \ --resource-group MyResourceGroup \ --name MyScaleSet01 \ --vm-sku Standard_DS1_v2
アップグレードポリシーが「手動」の場合はaz vmss update-instancesコマンド等の操作を必要としますが、アップグレードポリシーが「自動」の場合は明示的な操作なしにアップグレードが開始されます。以下のようなコマンドを実行し、仮想マシンのvm-skuが変わった事を確認します。
az vmss list-instances \
--resource-group MyResourceGroup \
--name MyScaleSet01 \
--query "[].{name:name, sku:sku.name }" \
--output table
Name Sku
-------------- ---------------
MyScaleSet01_1 Standard_DS1_v2
MyScaleSet01_2 Standard_DS1_v2
MyScaleSet01_3 Standard_DS1_v2
MyScaleSet01_5 Standard_DS1_v2
MyScaleSet01_6 Standard_DS1_v2
ローリング
アップグレードポリシーを「ローリング」に変更します。操作例は以下の通りです。
ローリングアップデートをするには「正常性監視」が定義されている事が前提です。
az vmss update \ --resource-group MyResourceGroup \ --name MyScaleSet01 \ --set upgradePolicy.mode=Rolling
ローリングアップデートの動作確認をするために、仮想マシンのvm-skuを変更します。
az vmss update \ --resource-group MyResourceGroup \ --name MyScaleSet01 \ --vm-sku Standard_B1s
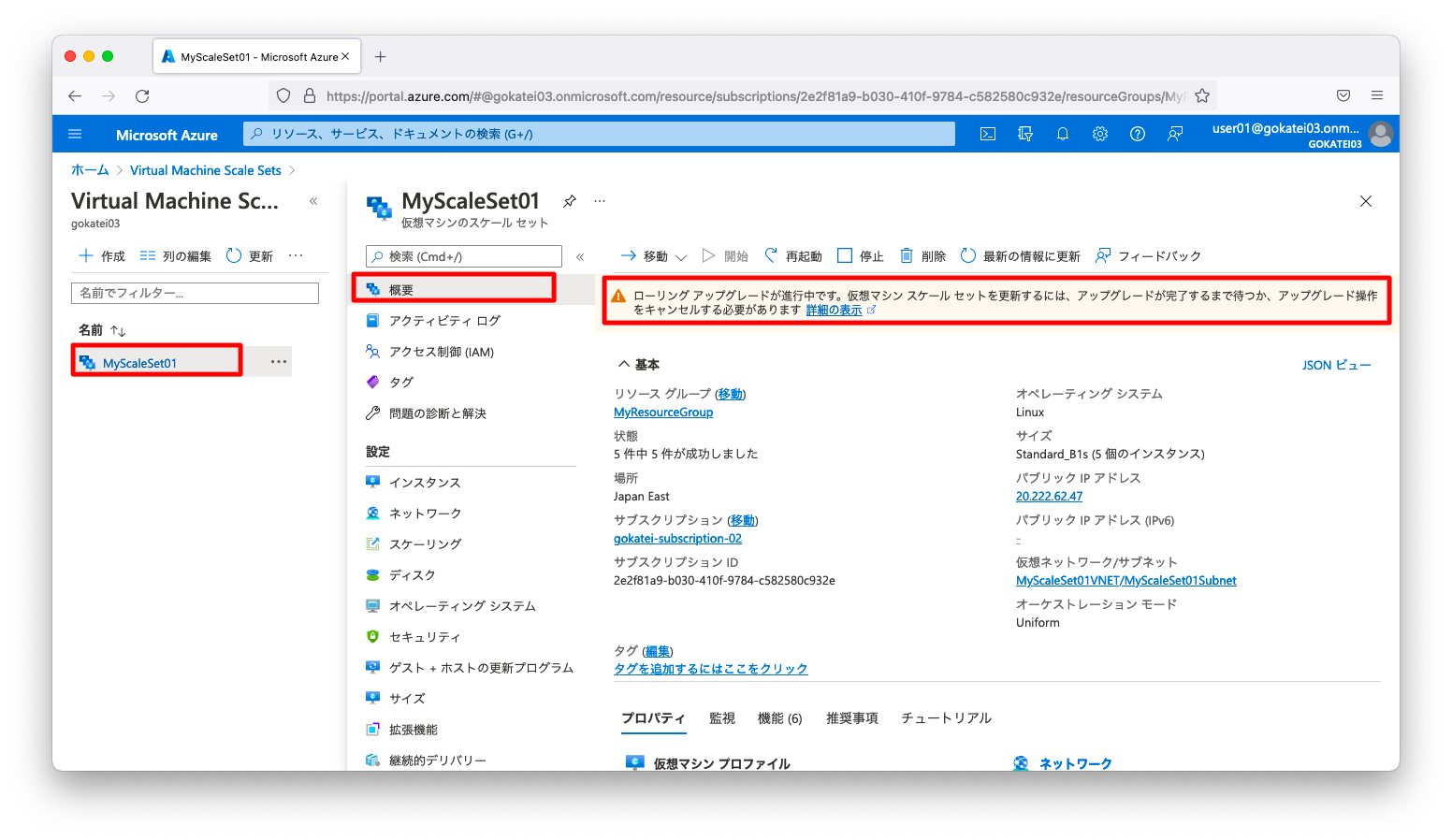
ポータル(GUI)で、仮想マシンスケールセットの「概要」画面を確認します。すると、「ローリング アップグレードが進行中です。仮想マシン スケール セットを更新するには、アップグレードが完了するまで待つか、アップグレード操作をキャンセルする必要があります」とのメッセージが表示されています。
「インスタンス」画面を見ると、ローリングアップデートの進捗を確認できます。

ローリングアップデートの進捗をazコマンドで確認するには以下のaz vmss rolling-upgrade get-latestコマンドを使用します。
$ az vmss rolling-upgrade get-latest \
--resource-group MyResourceGroup \
--name MyScaleSet01
{
"error": null,
"id": null,
"location": "japaneast",
"name": null,
"policy": {
"enableCrossZoneUpgrade": null,
"maxBatchInstancePercent": 20,
"maxUnhealthyInstancePercent": 20,
"maxUnhealthyUpgradedInstancePercent": 20,
"pauseTimeBetweenBatches": "PT0S",
"prioritizeUnhealthyInstances": null
},
"progress": {
"failedInstanceCount": 0,
"inProgressInstanceCount": 1,
"pendingInstanceCount": 3,
"successfulInstanceCount": 1
},
"runningStatus": {
"code": "RollingForward",
"lastAction": "Start",
"lastActionTime": "2022-03-26T07:12:48.595262+00:00",
"startTime": "2022-03-26T07:12:48.735889+00:00"
},
"tags": null,
"type": "Microsoft.Compute/virtualMachineScaleSets/rollingUpgrades"
}
どの仮想マシンがアップデート中かを確認するには、az vmss get-instance-viewの出力を確認します。出力される情報量が多いので、適宜queryで整形してください。
$ az vmss get-instance-view \
--resource-group MyResourceGroup \
--name MyScaleSet01 \
--instance-id '*' \
--query "[].{computerName:computerName, status:statuses[0].displayStatus}" \
--output table
ComputerName Status
--------------- ----------------------
myscae302000001 Provisioning succeeded
myscae302000002 Updating
myscae302000003 Provisioning succeeded
myscae302000005 Provisioning succeeded
myscae302000006 Provisioning succeeded
ローリングアップデートのパラメタ変更
デフォルト設定は20%ずつアップグレードします。場合によっては、20%ずつではなく40%ずつアップデートして早く完了させたいと思う事もあれば、20%ずつではなく10%ずつのアップデートでより慎重な計画を立てたいと思う事もあるでしょう。
ローリングアップデートは以下パラメタの指定が可能です。
| パラメタ | デフォルト値 | 説明 |
|---|---|---|
| pause-time-between-batches | PT0S | バッチ間の一時停止間隔 |
| max-batch-instance-percent | 20 | ローリング アップグレードのバッチ サイズ(%) |
| max-unhealthy-instance-percent | 20 | 異常状態のインスタンスの最大(%) |
| max-unhealthy-upgraded-instance-percent | 20 | アップグレードされた異常状態のインスタンスの最大(%) |
動作確認のため、同時にアップグレード可能なパーセントを20%から40%に増やします。5台構成ならば2台同時にアップグレード可能になるように設定変更します。
azコマンドで、引数pause-time-between-batchesを指定する場合はISO 8601という日付と時刻を表す規格で指定する必要があります。0秒間ならば「PT0S」と、1分間ならば「PT1M」のように指定します。
az vmss update \ --resource-group MyResourceGroup \ --name MyScaleSet01 \ --pause-time-between-batches PT0S \ --max-batch-instance-percent 40 \ --max-unhealthy-instance-percent 40 \ --max-unhealthy-upgraded-instance-percent 40
ローリングアップデートの動作確認をするために、仮想マシンのvm-skuを変更します。
az vmss update \ --resource-group MyResourceGroup \ --name MyScaleSet01 \ --vm-sku Standard_DS1_v2
ローリングアップデートの進捗を確認します。40%同時のアップデートを許容したため、アップグレード中のインスタンス数を示すinProgressInstanceCountが1から2に増えた事が分かります。
$ az vmss rolling-upgrade get-latest \
--resource-group MyResourceGroup \
--name MyScaleSet01
{
"error": null,
"id": null,
"location": "japaneast",
"name": null,
"policy": {
"enableCrossZoneUpgrade": null,
"maxBatchInstancePercent": 40,
"maxUnhealthyInstancePercent": 40,
"maxUnhealthyUpgradedInstancePercent": 40,
"pauseTimeBetweenBatches": "PT0S",
"prioritizeUnhealthyInstances": null
},
"progress": {
"failedInstanceCount": 0,
"inProgressInstanceCount": 2,
"pendingInstanceCount": 3,
"successfulInstanceCount": 0
},
"runningStatus": {
"code": "RollingForward",
"lastAction": "Start",
"lastActionTime": "2022-03-26T07:55:02.117741+00:00",
"startTime": "2022-03-26T07:55:02.195870+00:00"
},
"tags": null,
"type": "Microsoft.Compute/virtualMachineScaleSets/rollingUpgrades"
}
仮想マシンの状態を確認すると以下のようになります。
$ az vmss get-instance-view \
--resource-group MyResourceGroup \
--name MyScaleSet01 \
--instance-id '*' \
--query "[].{computerName:computerName, status:statuses[0].displayStatus}" \
ComputerName Status
--------------- ----------------------
myscae302000001 Provisioning succeeded
myscae302000002 Updating
myscae302000003 Provisioning succeeded
myscae302000005 Provisioning succeeded
myscae302000006 Updating
補足
ローリングアップグレードのキャンセル
本来論で言えばあってはならない事ですが、新バージョンの仮想マシンで何らかの誤りが発覚した場合はローリングアップデートを中断する事もできます。操作方法は以下の通りです。
az vmss rolling-upgrade cancel \ --resource-group <リソースグループ名> \ --name <仮想マシンスケールセット名> \
ローリングアップデートのデメリット
初学者の陥りやすい間違えとして「全台同時アップデート」よりも「ローリングアップデート」の方が優れているという誤解があります。「ローリングアップデート」は確かにトラフィックを無停止で負荷分散する事ができますが、これは「新旧のアプリケーションが混在してもデータ不整合などの不具合が発生しない」という前提条件が必要になります。
もし、新旧のアプリケーションが混在する事によって不具合が発生するならば、「全台同時」のアップグレードを計画します。場合によって(例:周辺システムのキャッシュ等)は、「全台同時」のアップグレードではなく計画停止を考えた方が良い事もあります。
