Prometheusは障害発生時にEmail, Slack, Hipchatなど多数の通知機能を備えています。このページではアラートを定義し、アラートを通知する簡易的な操作を説明します。
単にアラートを発報するだけでは運用は成り立ちません。多くの場合はアラートを抑制したり類似アラートをまとめたりの必要性に迫られるでしょう。このような機能は「Prometheus アラートマネージャー」を参照ください。
前提
参照資料
動作確認済環境
- Rocky Linux 8.6
- Prometheus 2.36.2
- alertmanager 0.24.0
構成図
3台の仮想マシンに対して、以下コンポーネントがインストール済の状態とします。
+----------------+ +----------------+ +----------------+ | linux040 | | linux041 | | linux042 | | 172.16.1.40/24 | | 172.16.1.41/24 | | 172.16.1.42/24 | | node_exporter | | node_exporter | | node_exporter | | prometheus | | | | | +----------------+ +----------------+ +----------------+
アラートに関する設定
アラートの設定
アラートの書式は「Prometheus レコーディング」と非常によく似ています。以下のように設定すれば、jobがnodeという名前のマシンについて、80%未満が生存していればアラート「SomeInstancesDown」を発報し、50%未満が生存していればアラート「ManyInstancesDown」を発報します。
cat << EOF > /etc/prometheus/rules.yml
groups:
- name: example
rules:
- record: job:up:avg
expr: avg without(instance)(up{job="node"})
- alert: SomeInstancesDown
expr: job:up:avg < 0.8
for: 5m
labels:
severity: warn
- alert: ManyInstancesDown
expr: job:up:avg < 0.5
for: 5m
labels:
severity: critical
EOF
「Prometheus レコーディング」と同様に、prometheus.ymlに外部ファイルrules.ymlを参照するように設定する。
cat << EOF > /etc/prometheus/prometheus.yml
global:
scrape_interval: 10s
evaluation_interval: 10s
rule_files:
- rules.yml
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- 172.16.1.40:9090
- job_name: node
static_configs:
- targets:
- 172.16.1.40:9100
- 172.16.1.41:9100
- 172.16.1.42:9100
EOF
アラートマネージャーの設定
アラートを発報するにはアラートマネージャーというソフトウェアが必要です。このページでは動作確認用の最低限の説明に留めます。
まずは、アラートマネージャーをインストールします。
dnf install alertmanager
メールを用いた通報をするには以下のように設定します。
cat << EOF > /etc/prometheus/alertmanager.yml
route:
receiver: 'email-notice'
receivers:
- name: 'email-notice'
email_configs:
- to: '<宛先メールアドレス>'
from: '送信元名 <送信元メールアドレス>'
smarthost: '<メールサーバFQDN>:<メールサーバポート番号>'
auth_username: '<メールユーザ名>'
auth_password: '<メールパスワード>'
require_tls: false
EOF
アラートマネージャーを起動します。
systemctl enable alertmanager.service --now
アラートマネージャーはtcp9093でlistenしています。Prometheusからアラートマネージャーのtcp9093へ通報するように設定します。
cat << EOF > /etc/prometheus/prometheus.yml
global:
scrape_interval: 10s
evaluation_interval: 10s
rule_files:
- rules.yml
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- 172.16.1.40:9090
- job_name: node
static_configs:
- targets:
- 172.16.1.40:9100
- 172.16.1.41:9100
- 172.16.1.42:9100
alerting:
alertmanagers:
- static_configs:
- targets:
- 'localhost:9093'
EOF
アラートの動作確認
アラートの状態遷移
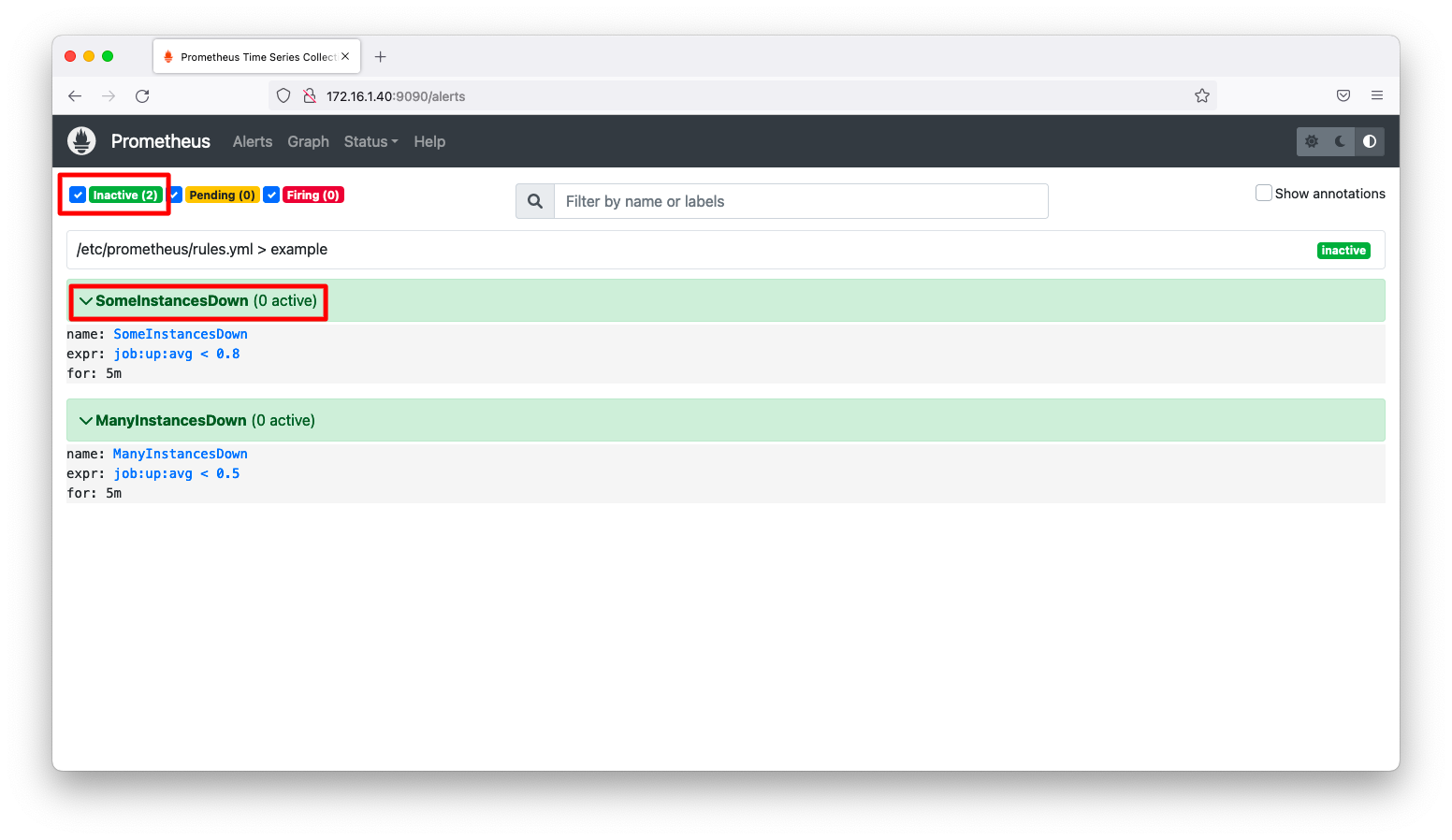
アラート画面(http://<IPアドレス>9090/alerts)をブラウザで閲覧します。すると、アラートが緑色で「inactive」と表示されます。これが正常な状態です。
1台のマシンでNode Exporterを停止し、疑似的な障害を発生させます。
systemctl stop node_exporter.service
アラート画面を見ると、黄色で「pending」と表示されます。この時点ではアラートは発報されません。
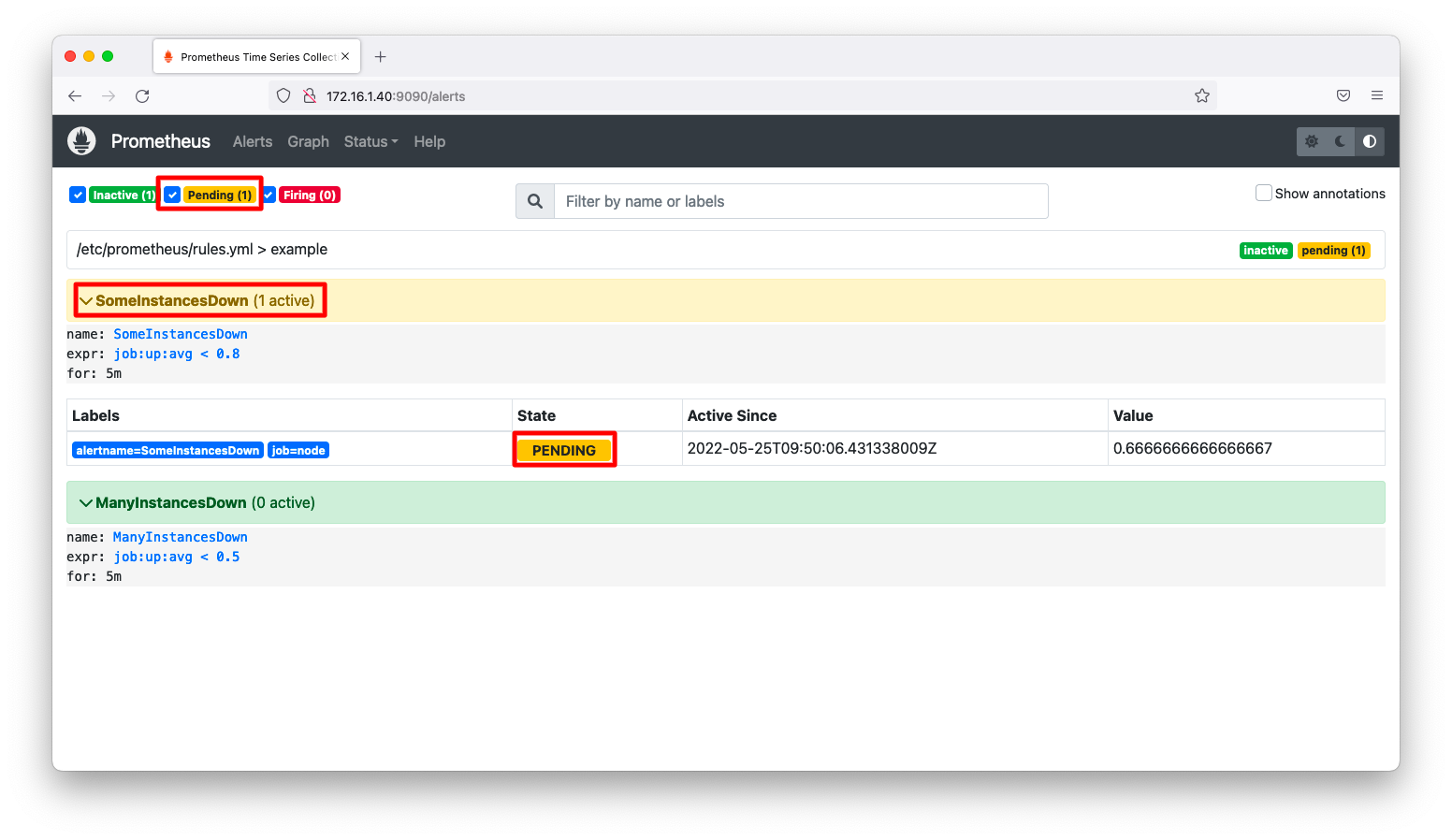
ここでrules.ymlに設定したアラートのルールを思い出してください。以下にrules.yamlを再掲します。「for:5m」という期間を設定しています。これは一時的なダウンで発報しないための仕様で、exprの条件を満たした時間がforを超過すると、「pending」から「firing」に変わります。
cat << EOF > /etc/prometheus/rules.yml
groups:
- name: example
rules:
- record: job:up:avg
expr: avg without(instance)(up{job="node"})
- alert: SomeInstancesDown
expr: job:up:avg < 0.8
for: 5m
- alert: ManyInstancesDown
expr: job:up:avg < 0.5
for: 5m
EOF
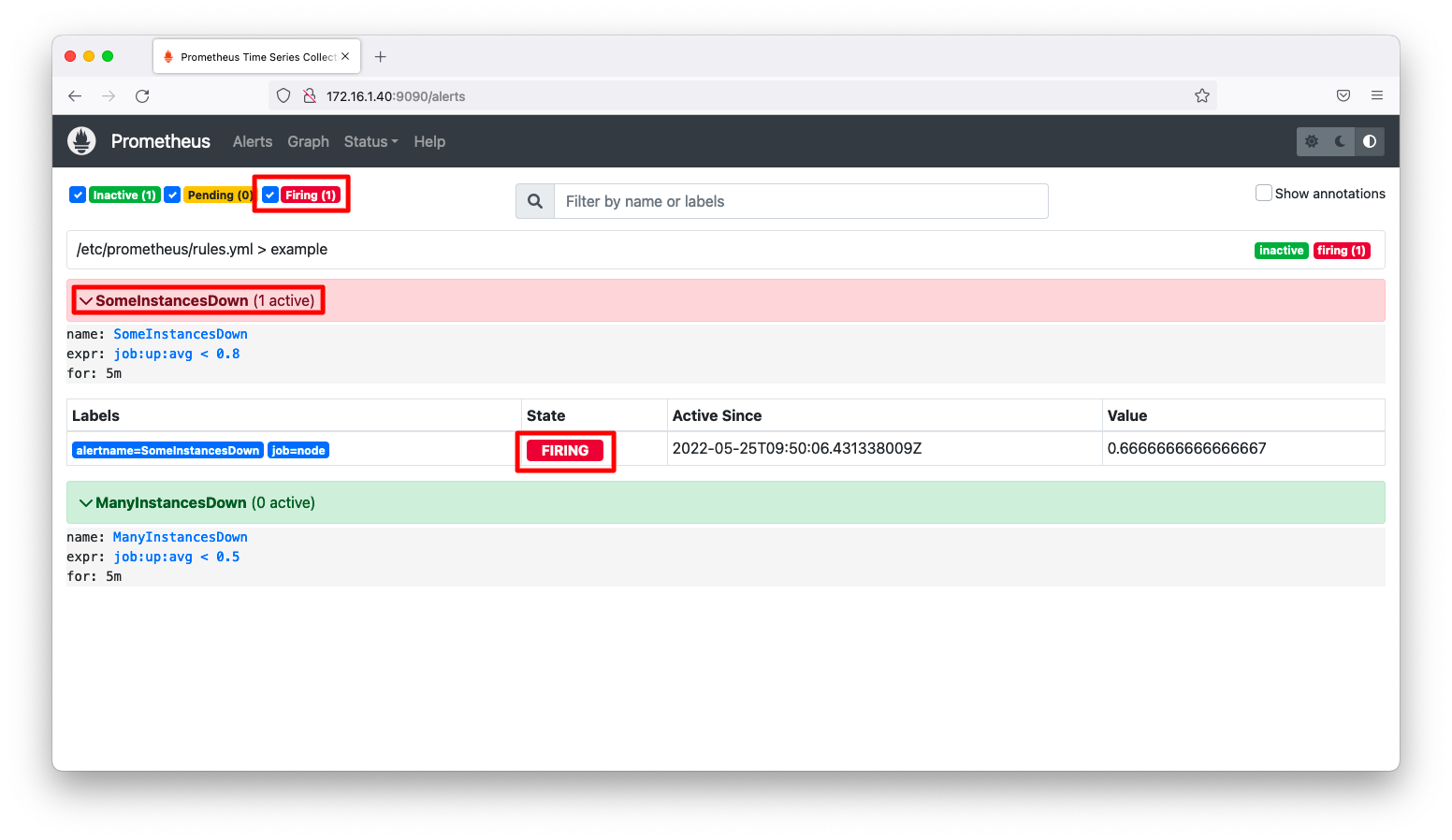
5分経過後、再度、アラート画面を見ます。状態が「pending」から「firing」に変わった事を確認します。
メールの受信確認
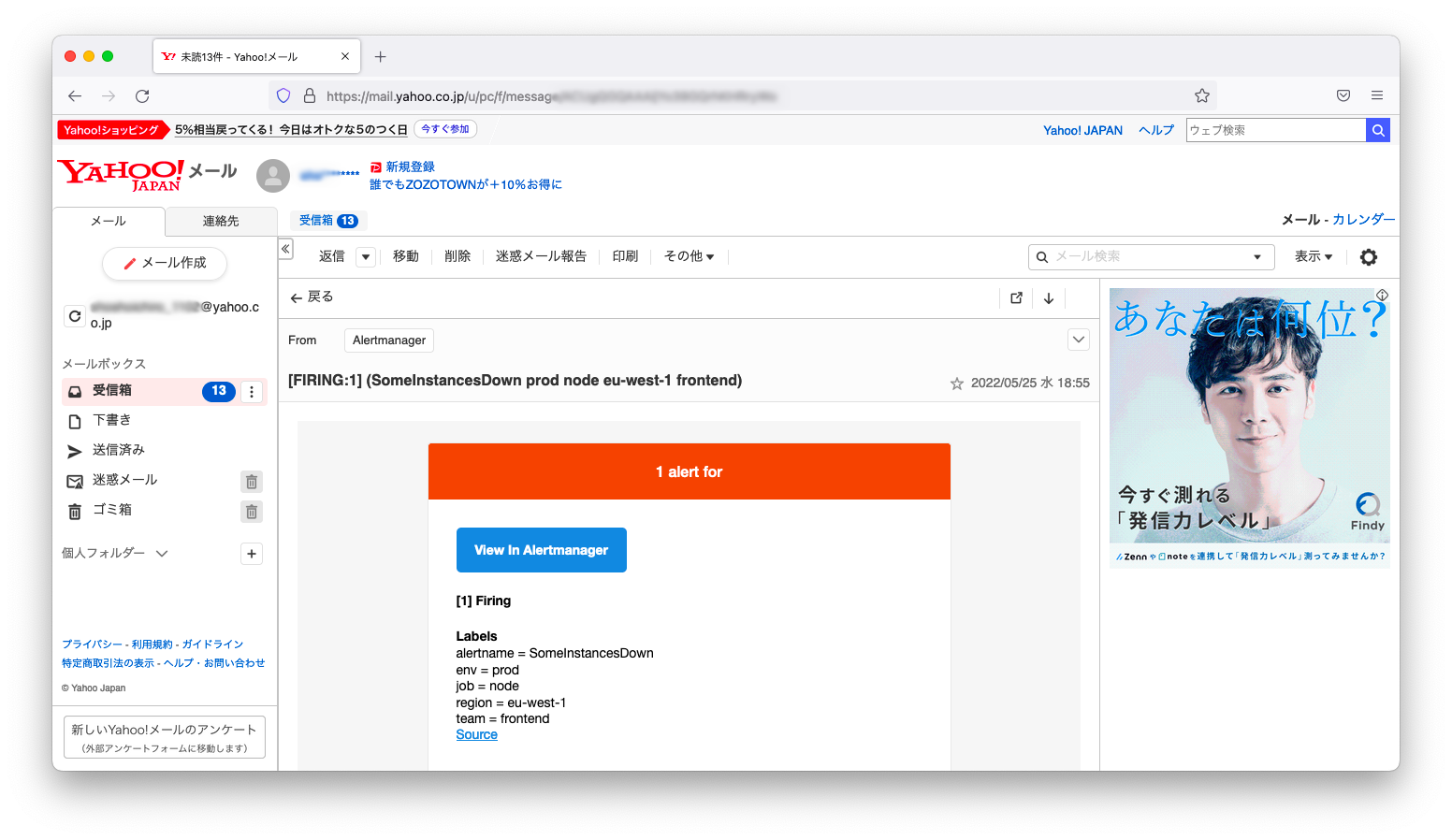
メールサーバの設定に誤りがないならば、以下スクリーンショットのようにメールの受信を確認できます。もし、メールサーバの構築が手間ならばSMTPによる接続を公開しているフリーメール(Gmail, Yahooメールなど)を利用しても良いでしょう。
補足
メール以外の通知方法
webhook
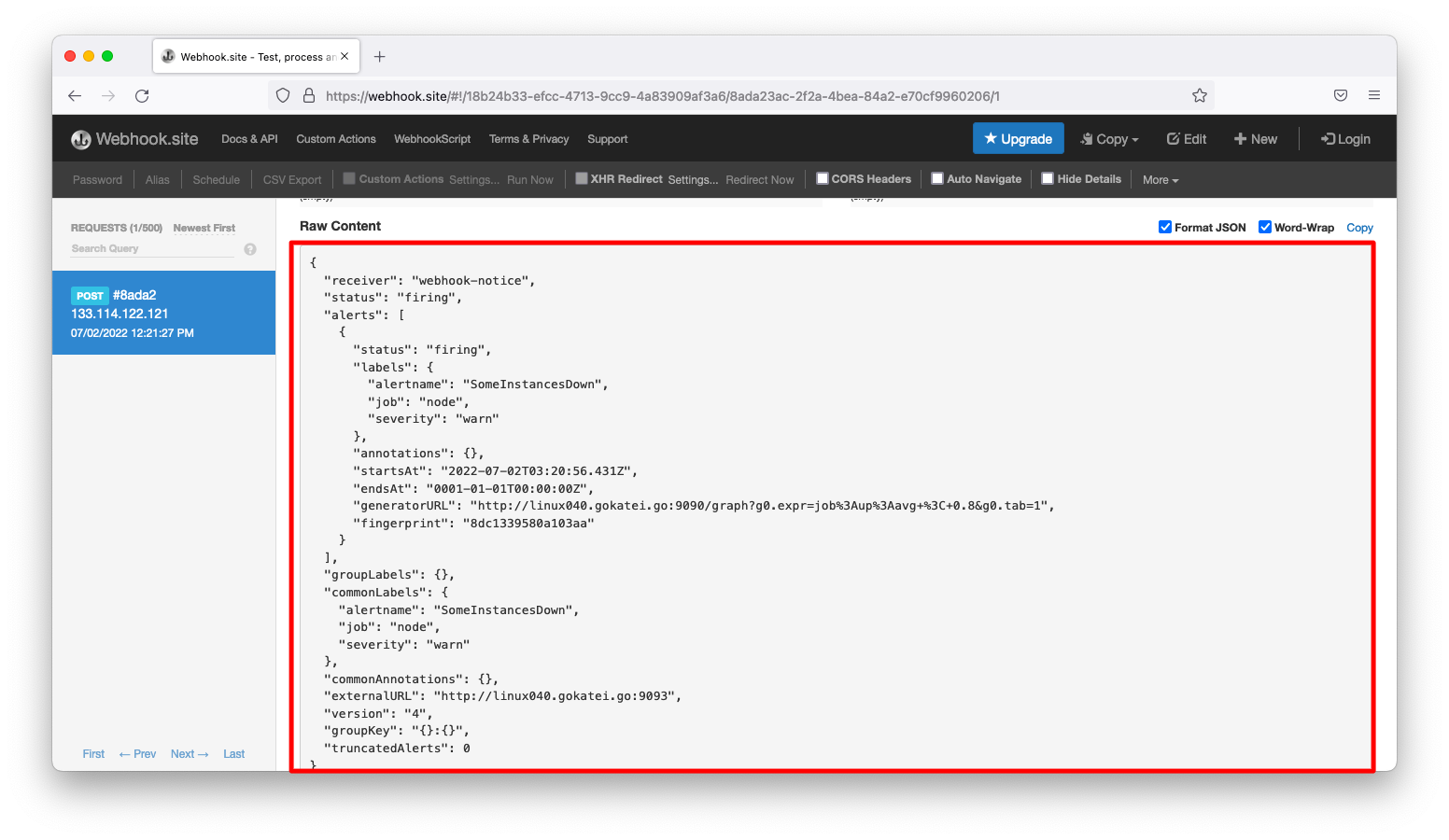
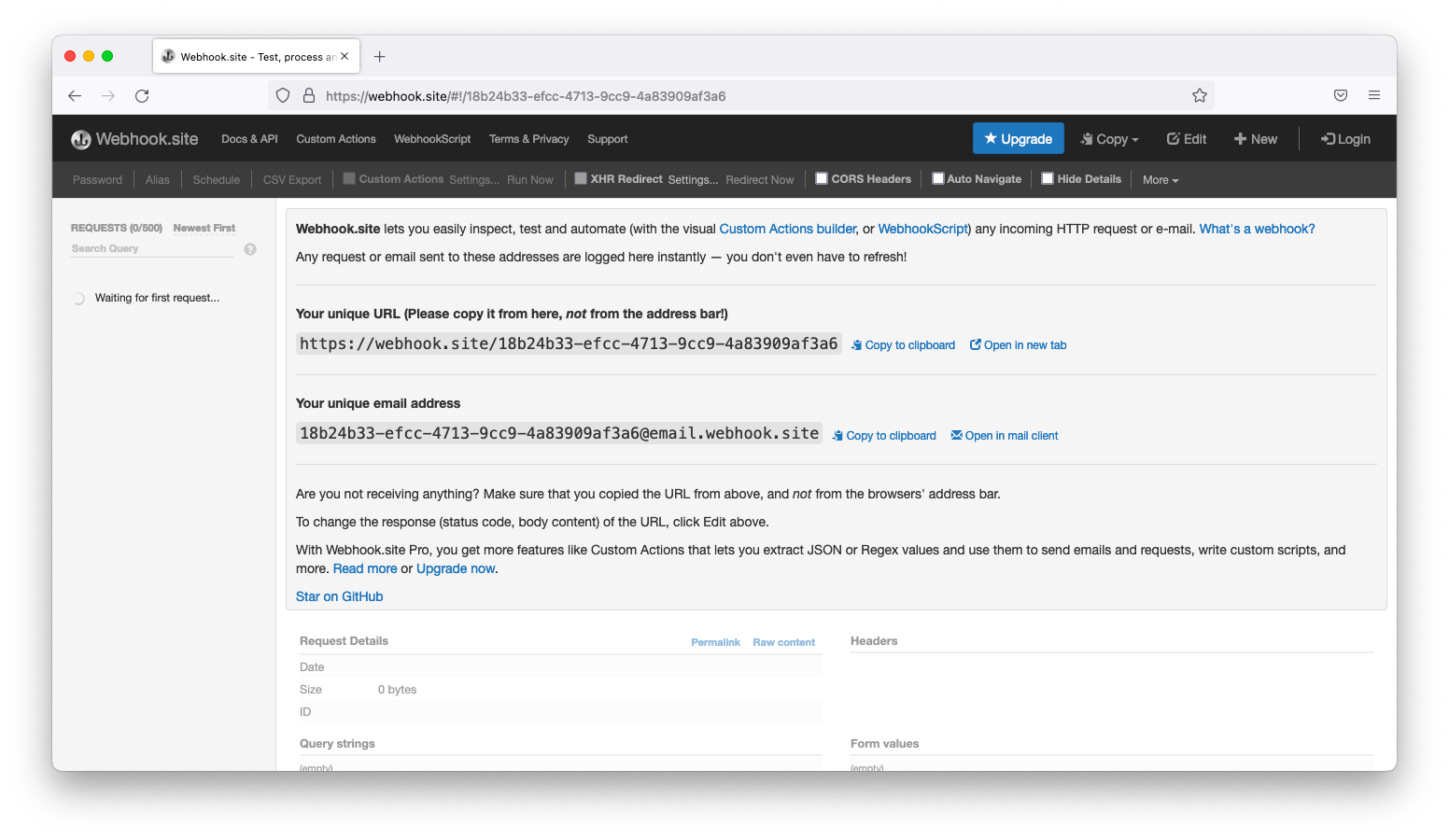
アラートマネージャーはwebhookによる通知も可能です。適当な動作確認用のwebhookをすぐに準備できない方はwebhook.siteを利用すると良いでしょう。以下スクリーンショットのようなサービスです。
webhookに通知するには以下のような設定を作成します。urlの部分は環境に合わせて適宜変更してください。
cat << EOF > /etc/prometheus/alertmanager.yml route: receiver: 'webhook-notice' receivers: - name: webhook-notice webhook_configs: - url: https://webhook.site/18b24b33-efcc-4713-9cc9-4a83909af3a6 EOF
node exporterのうち1台を停止させると、以下のようなアラートが発報されます。