AlertManagerはPrometheusと連携される事が多いアラートの通報を管理する機能です。運用でありがちな悩みのアラートのグループ化や通報抑止や通報先の管理などの機能を備えます。このページではAlertManagerの操作をまとめます。
前提
参照資料
動作確認済環境
- Rocky Linux 8.6
- Prometheus 2.36.2
- alertmanager 0.24.0
構成図
7台の仮想マシンに対して、以下コンポーネントがインストール済の状態とします。web01, web02などのホスト名は名前解決可能である事を前提とします。
+----------------+ | linux040 | | 172.16.1.40/24 | | node_exporter | | prometheus | +----------------+ +----------------+ +----------------+ +----------------+ | web01 | | web02 | | web03 | | 172.16.1.41/24 | | 172.16.1.42/24 | | 172.16.1.43/24 | | node_exporter | | node_exporter | | node_exporter | | | | | | | +----------------+ +----------------+ +----------------+ +----------------+ +----------------+ +----------------+ | db01 | | db02 | | db03 | | 172.16.1.44/24 | | 172.16.1.45/24 | | 172.16.1.46/24 | | node_exporter | | node_exporter | | node_exporter | | | | | | | +----------------+ +----------------+ +----------------+
初期設定
prometheus.ymlの初期設定は以下の通りとします。
cat << EOF > /etc/prometheus/prometheus.yml
global:
scrape_interval: 10s
evaluation_interval: 10s
rule_files:
- rules.yml
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: node
static_configs:
- targets:
- web01:9100
- web02:9100
- web03:9100
- db01:9100
- db02:9100
- db03:9100
alerting:
alertmanagers:
- static_configs:
- targets:
- 'localhost:9093'
EOF
AlertManagerの機能確認
タグの付与
AlertManagerはグループを定義し、そのグループに対してアラートの通報先を定義したり個別のチューニングをしたりする事ができます。
まずはグループ化の前準備としてアラートに対してタグを付けます。以下はアラートに対してseverityとteamsの2種類のタグを付与する設定例です。
インスタンス名が正規表現「web.*:9100」に合致するサーバの町外はチームwebを割り当て、インスタンス名が正規表現「db.*:9100」に合致するサーバの町外はチームdbを割り当てます。その他の通報はチームfullstackを割り当てます。
cat << EOF > /etc/prometheus/rules.yml
groups:
- name: example
rules:
- record: job:node:up:avg
expr: avg without(instance)(up{job="node"})
- alert: SomeInstancesDown
expr: job:node:up:avg < 0.7
for: 5m
labels:
severity: info
team: fullstack
- record: job:web:up:avg
expr: avg without(instance)(up{instance=~"web.*:9100"})
- alert: WebInstanceDown
expr: job:web:up:avg < 0.7
for: 5m
labels:
severity: info
team: web
- record: job:db:up:avg
expr: avg without(instance)(up{instance=~"db.*:9100"})
- alert: DbInstanceDown
expr: job:db:up:avg < 0.7
for: 5m
labels:
severity: info
team: db
EOF
以降、このようなタグに基づいたグループを定義しながら各種の設定を行います。
ルーティング(通報先の定義)
アラートマネージャーにはルーティングと呼ばれる機能が備わっており、前述のteamなどのタグに基づいて通報先を設定する事ができます。以下にアラートによって通報先を分ける設定例を示します。
複数の通報先を動作確認したいならば、gmail aliasなどを使用すると容易に動作確認ができます。
cat << EOF > /etc/prometheus/alertmanager.yml
global:
smtp_smarthost: 'mail.xxxxxxxx.net:465'
smtp_from: 'prometheus alert <xxxxxxxx@xxxxx.co.jp>'
smtp_auth_username: 'xxxxxxxx@xxxxx.co.jp'
smtp_auth_password: 'P@ssw0rd'
smtp_require_tls: false
route:
receiver: 'email-fallback'
routes:
- match:
team: web
receiver: 'email-web'
- match:
team: db
receiver: 'email-db'
receivers:
- name: 'email-web'
email_configs:
- to: 'xxxxxxxx+web@gmail.com'
- name: 'email-db'
email_configs:
- to: 'xxxxxxxx+db@gmail.com'
- name: 'email-fallback'
email_configs:
- to: 'xxxxxxxx+other@gmail.com'
EOF
再起動し設定を反映させます。
systemctl restart alertmanager.service
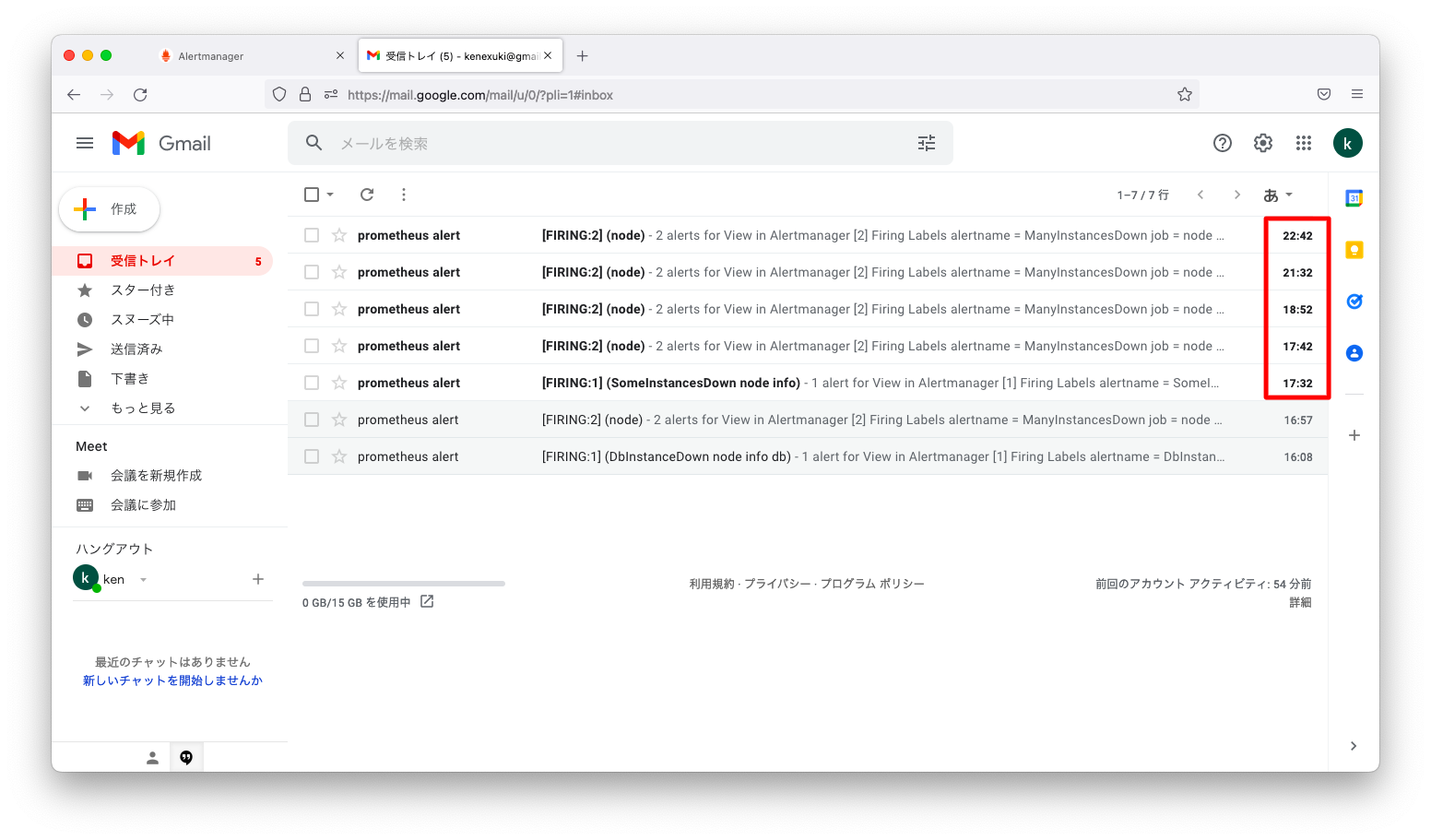
この状態でデータベースサーバの1台を停止させます。すると、以下スクリーンショットのようにデータベースの通報先であるxxxxxxxx+db@gmail.comにメールが送付されます。
次の検証シナリオに備えて、データベースサーバを復旧させます。
アラートの集約
デフォルトの挙動
複数のアラートをまとめ、運用者の負担を減らす事が求められます。AlertManagerはデフォルト設定でも、ある程度はアラートをまとめる設定がなされています。
動作確認の都合上、rules.ymlとalertmanager.ymlを以下のように変更します。90%未満のノード生存でSomeInstancesDownを発報し、70%未満のノード生存でManyInstancesDownを発報します。通報先はxxxxxxx-other@gmail.comのみとします。
cat << EOF > /etc/prometheus/rules.yml
groups:
- name: example
rules:
- record: job:node:up:avg
expr: avg without(instance)(up{job="node"})
- alert: SomeInstancesDown
expr: job:node:up:avg < 0.9
labels:
severity: info
- alert: ManyInstancesDown
expr: job:node:up:avg < 0.7
labels:
severity: warn
EOF
cat << EOF > /etc/prometheus/alertmanager.yml
global:
smtp_smarthost: 'mail.xxxxxxxx.net:465'
smtp_from: 'prometheus alert <xxxxxxxx@xxxxx.co.jp>'
smtp_auth_username: 'xxxxxxxx@xxxxx.co.jp'
smtp_auth_password: 'P@ssw0rd'
smtp_require_tls: false
route:
receiver: 'email-notice'
receivers:
- name: 'email-notice'
email_configs:
- to: 'xxxxxxx-other@gmail.com'
EOF
再起動し設定を反映させます。
systemctl restart prometheus.service systemctl restart alertmanager.service
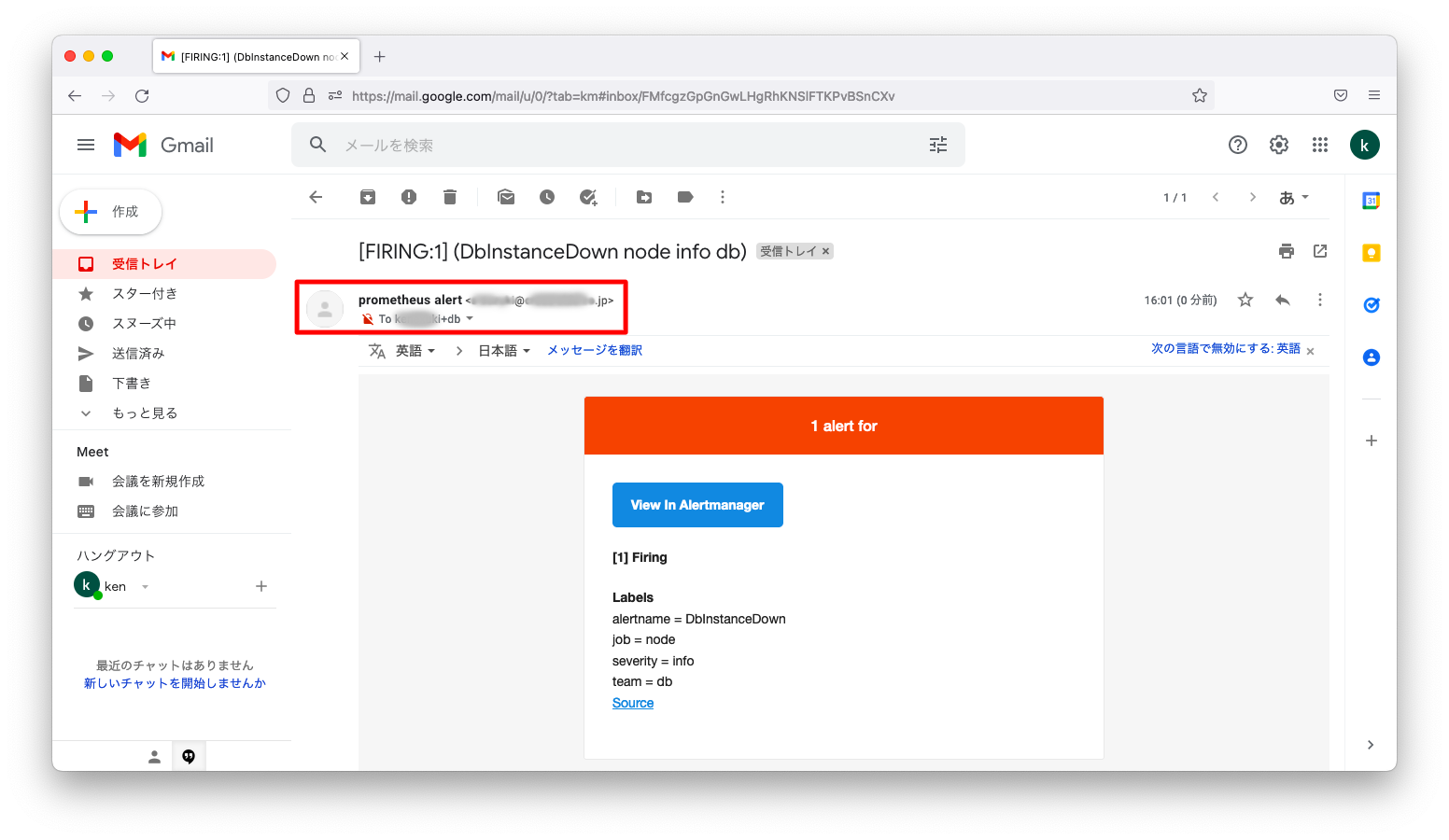
この状態でサーバを2つ同時に停止させます。すると、「SomeInstancesDown」「ManyInstancesDown」が1通のメールにまとめて送付されます。
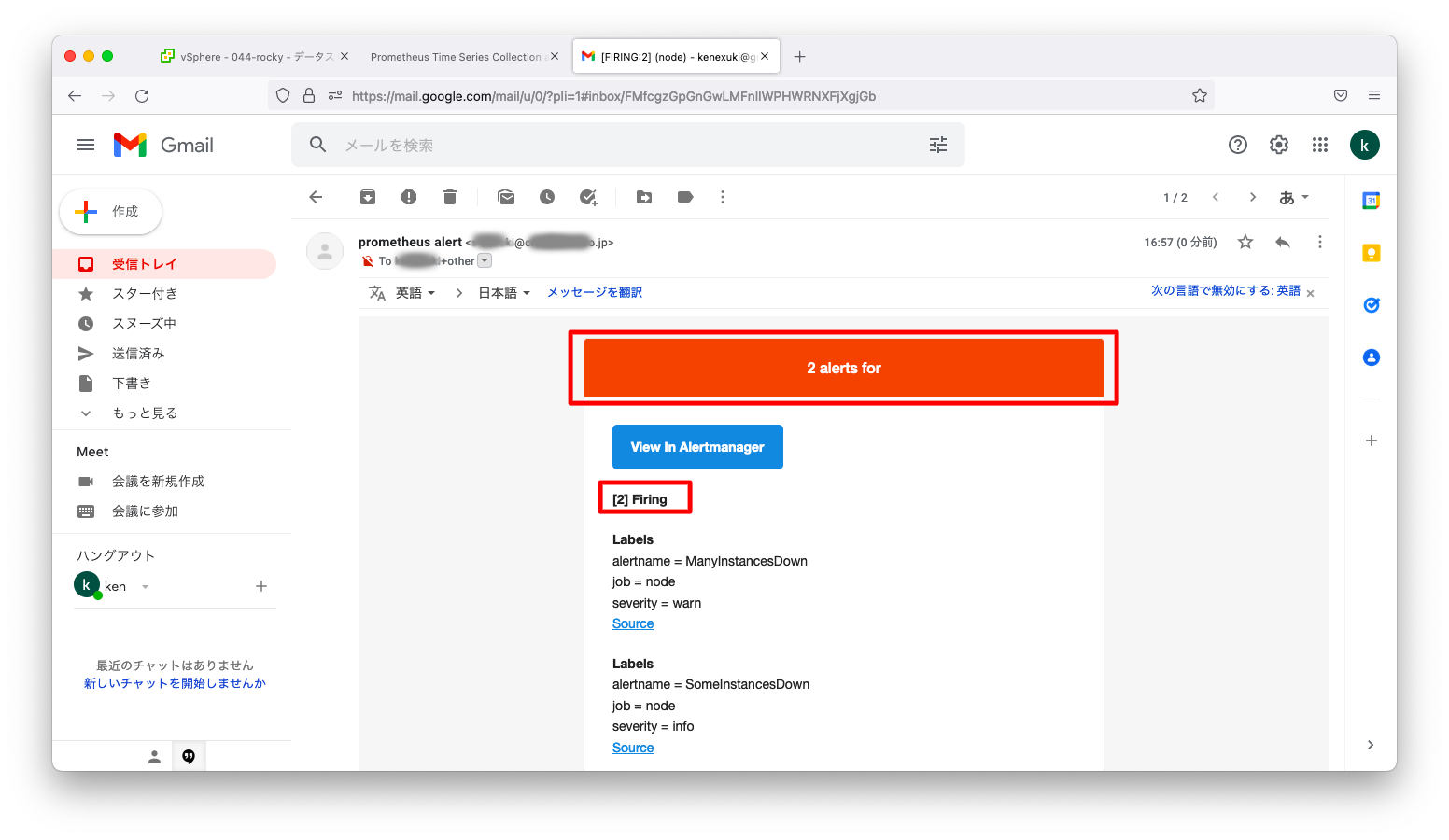
AlertManagerのデフォルト設定は、アラート受信後30秒待機し、その30秒間で受信したアラートは1件のメールにまとめる仕様になっています。
次の検証シナリオに備えサーバを復旧させます。
チューニング可能なパラメタ
アラートマネージャーは以下3つのパラメタをチューニングできます。デフォルト設定で運用上の支障がある場合は、以下パラメタを変更します。
| パラメタ | デフォルト値 | 説明 |
|---|---|---|
| group_wait | 30s | 発報する前に待機する時間。待機時間の間に複数のアラートが発生すれば、そのアラートは1つにまとめられる。 |
| group_interval | 5m | アラートを発報してから、次のアラートを発報するまでの待機時間 |
| repeat_interval | 4h | 同じアラートを再送するまでの時間。アラートが発報されたとしても「人」が対応を忘れる可能性もあるため、このようなヒューマンエラーに備えた機能。 |
パラメタ変更の動作確認
それでは、前述のパラメタが想定通りの挙動をするかを確認してみましょう。group_wait等のパラメタはrouteに対して指定します。設定例は以下の通りです。
cat << EOF > /etc/prometheus/alertmanager.yml global: smtp_smarthost: 'mail.xxxxxxxx.net:465' smtp_from: 'prometheus alert <xxxxxxxx@xxxxx.co.jp>' smtp_auth_username: 'xxxxxxxx@xxxxx.co.jp' smtp_auth_password: 'P@ssw0rd' smtp_require_tls: false route: receiver: 'email-notice' group_wait: 45s group_interval: 10m repeat_interval: 1h receivers: - name: 'email-notice' email_configs: - to: 'xxxxxxx-other@gmail.com' EOF
アラートを抑制する時間は/var/lib/prometheus/alertmanagerにキャッシュとして残ります。前述の動作確認のキャッシュによって想定通りの時間に発報されない事もありますので、再起動とキャッシュ削除をします。
systemctl stop alertmanager.service rm -rf /var/lib/prometheus/alertmanager systemctl start alertmanager.service
動作確認のために、1分差で2台のマシンを停止してみましょう。もし、正確に1分差で操作したいならば、以下のようにスクリプト化すると良いでしょう。
ssh web01 "shutdown -h now" sleep 60 ssh web02 "shutdown -h now"
しばらく待つと、擬似障害発生の1分後, 11分後, 81分後にメールを受信している事が分かります。
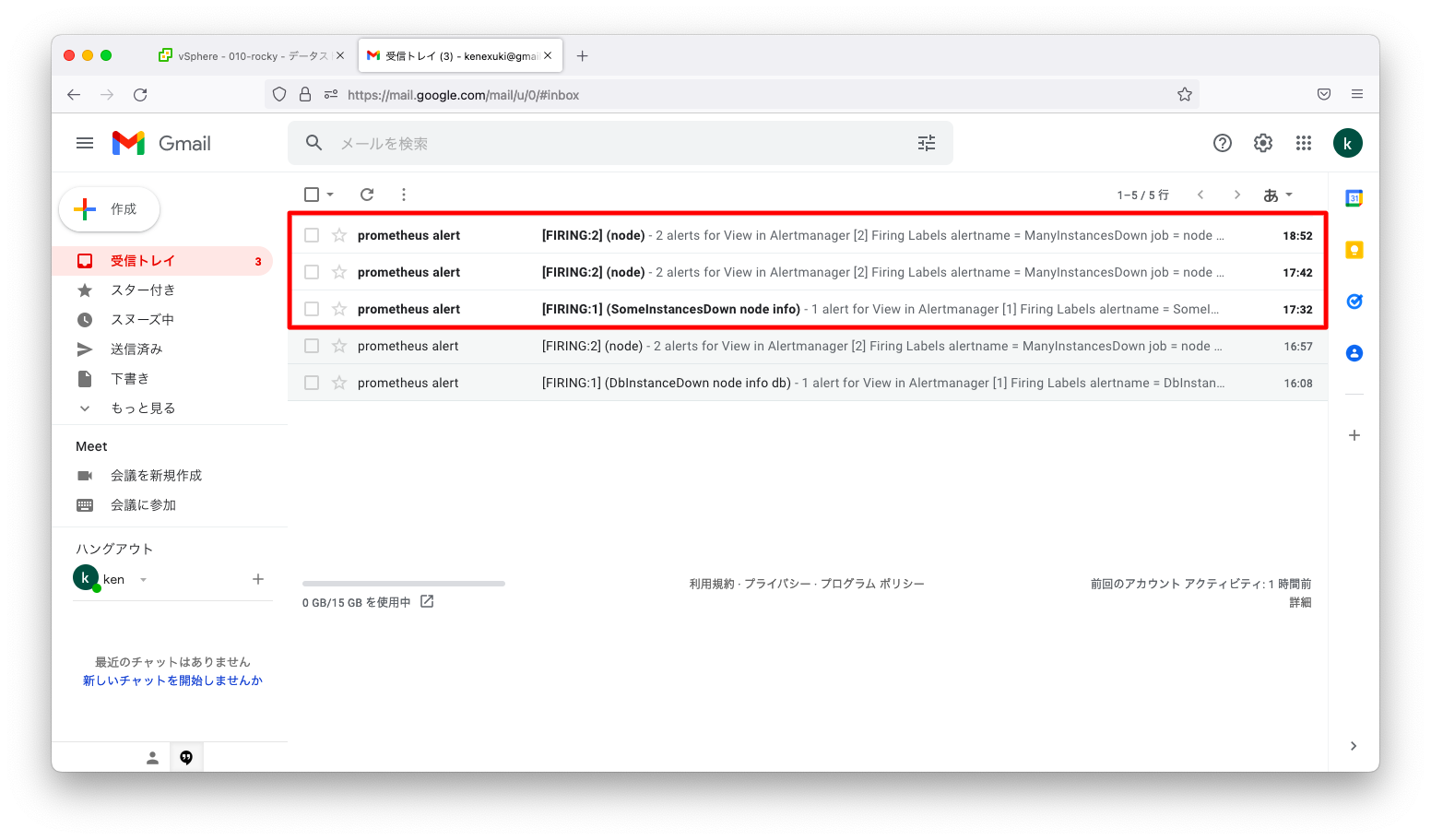
発生した現象を時系列で整理すると以下のようになります。
| 時刻 | 現象 |
|---|---|
| 17:31:35 | 1台目のサーバ障害 |
| 17:32:20 | 障害からgroup_wait(45秒)待ってからのSomeInstancesDownのアラート発報 |
| 17:32:35 | 2台目のサーバ障害 |
| 17:42:20 | 前回の通報からgroup_interval(10分)待ってからのManyInstancesDownのアラート発報 |
| 18:52:20 | 前回の通報からgroup_interval + repeat_interval(70分)待ってからの繰り返しのアラート発報 |
アラート抑制
アラート抑制の新規作成
多くの運用の現場では、4時間や24時間など障害復旧の目標時間をアラートのチケットクローズの目標時間を定めている事があります。ですが、アラートの種類によっては早期の解決が難しく、一時的にアラートを抑制するような操作が求められるかもしれません。
他の統合監視ツールと同様に、アラートマネージャーはアラート抑制機能が備わっています。アラートマネージャーがインストールされたマシンのtcp9093(http://<IPアドレス>:9093)をブラウザで開きます。すると、以下のような画面が現れます。
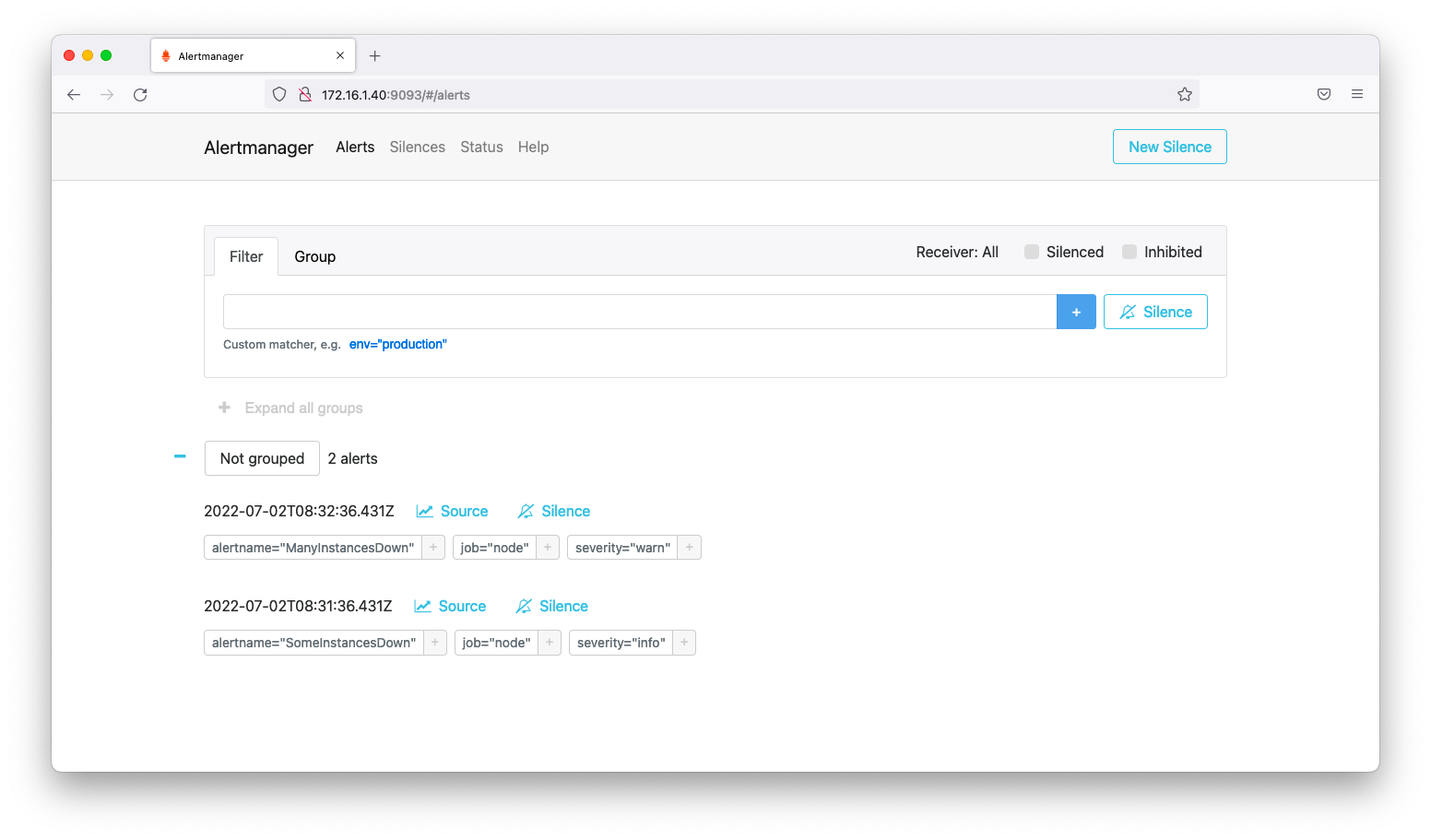
アラートマネージャーは、タグやグループに一致するアラートを同時に抑制する事ができます。旧来の監視ツールのように、アラート1つ1つに対してGUI手作業の操作は必要ありません。
それでは、jobがnodeであるアラートをまとめて抑制してみましょう。検索窓に「job=”node”」と入力した後にエンターキーを押下します。
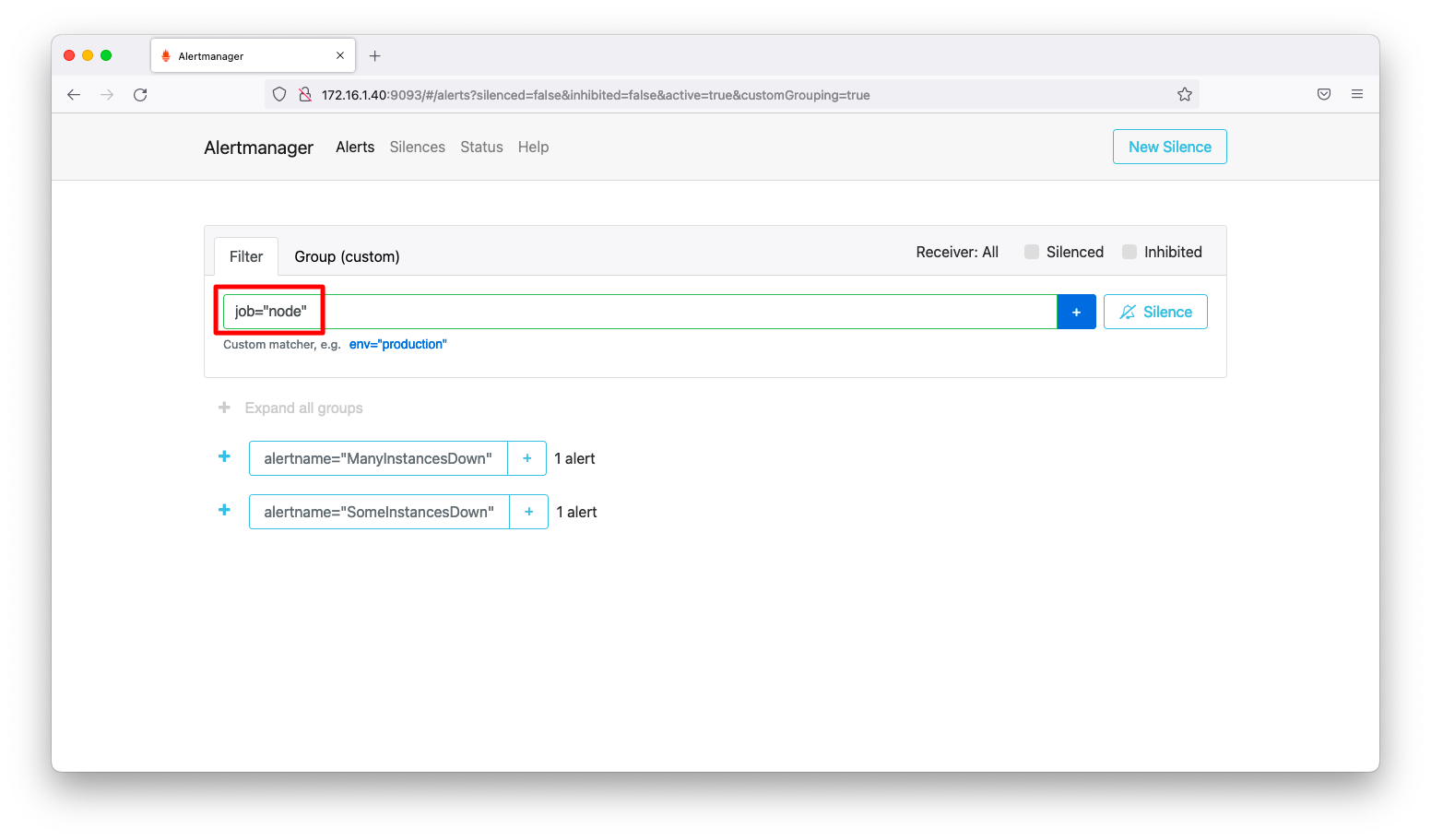
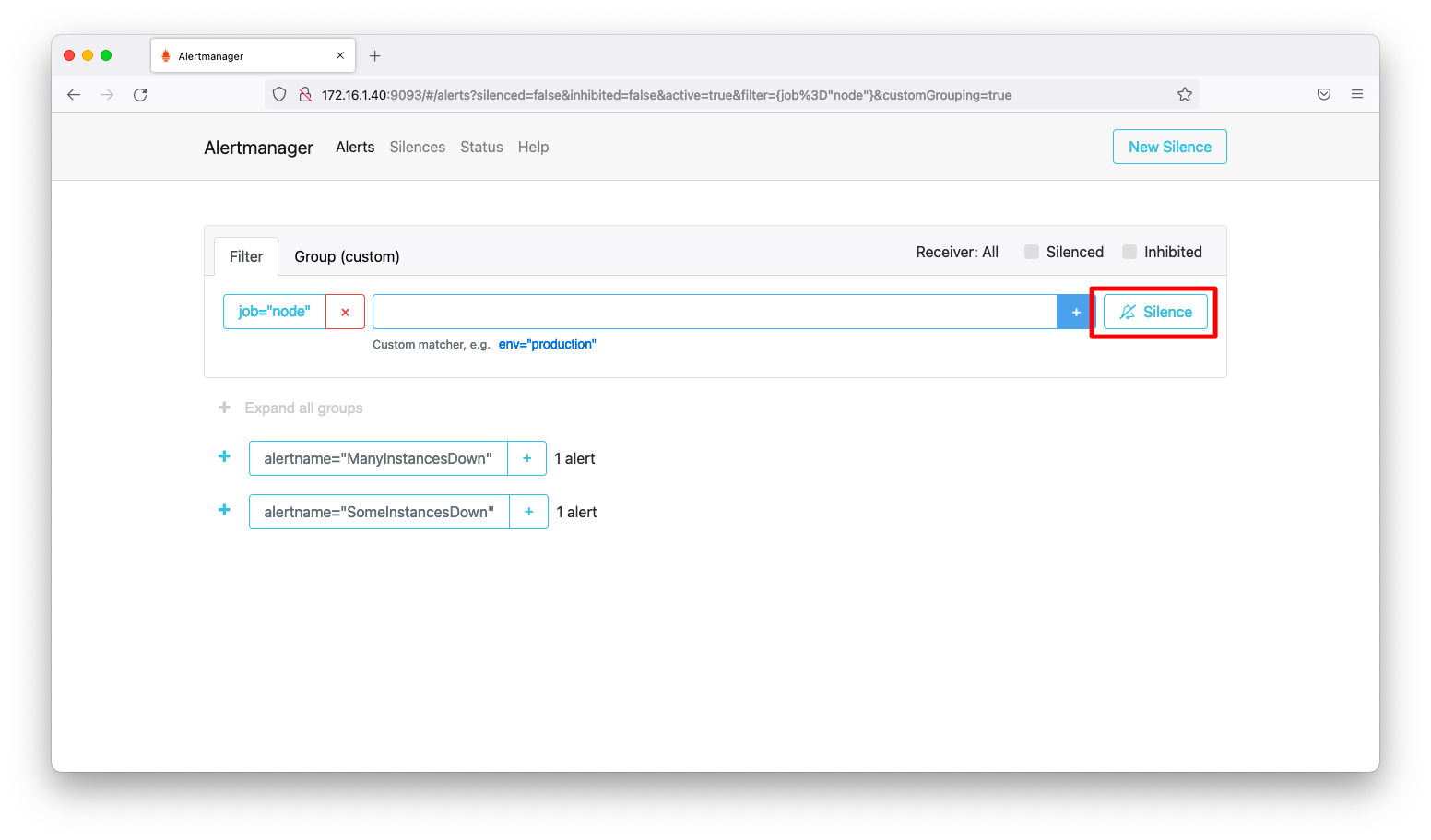
検索対象が絞り込まれた状態にして、「Silence」を押下します。
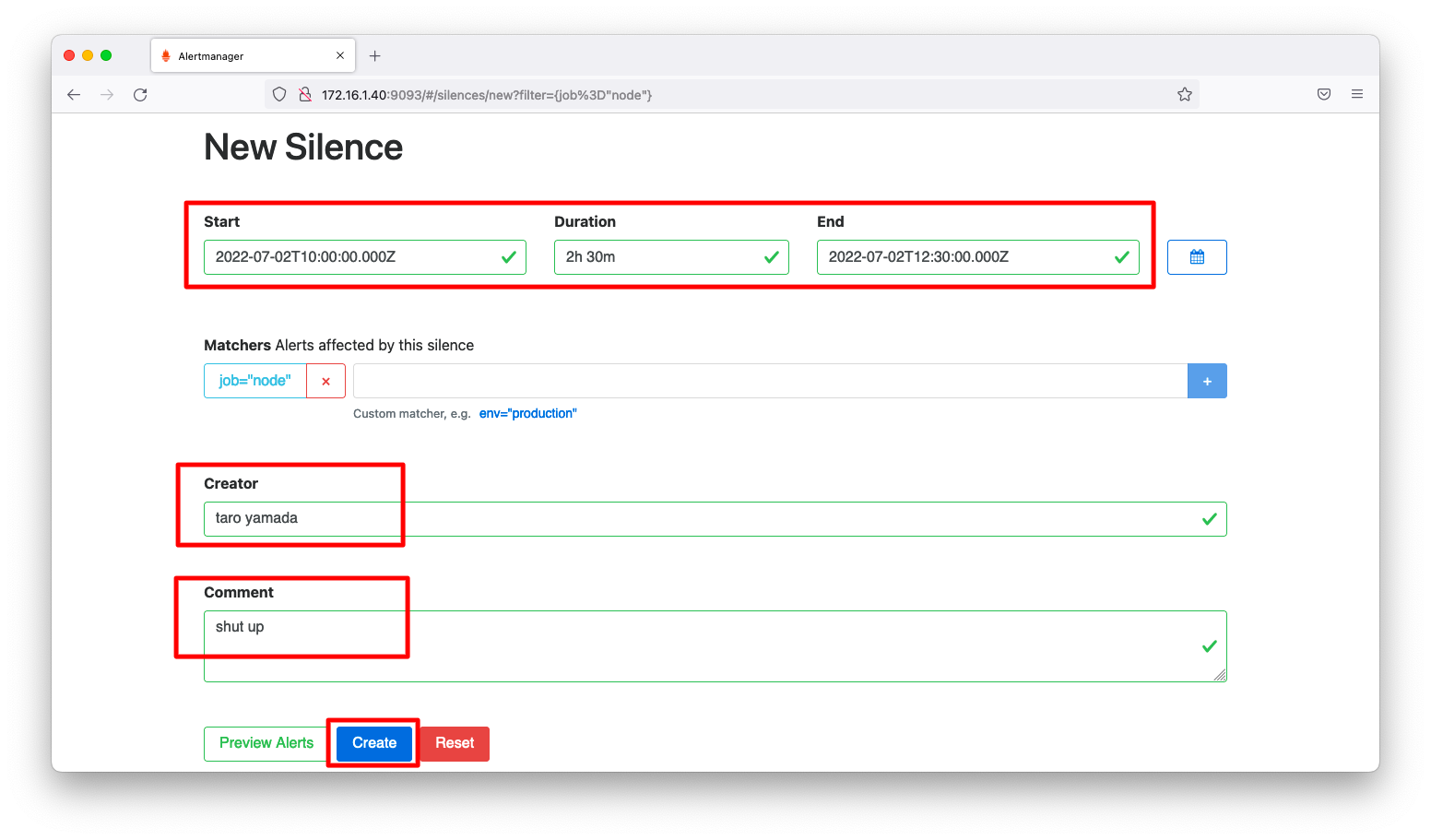
アラートが抑制される期間、Creator、Commentを入力します。期間はUTCで入力して下さい。2022年7月時点でアラートマネージャーはタイムゾーンの変更をサポートしていません。
入力完了後、「Create」を押下します。
アラート抑制の状態確認
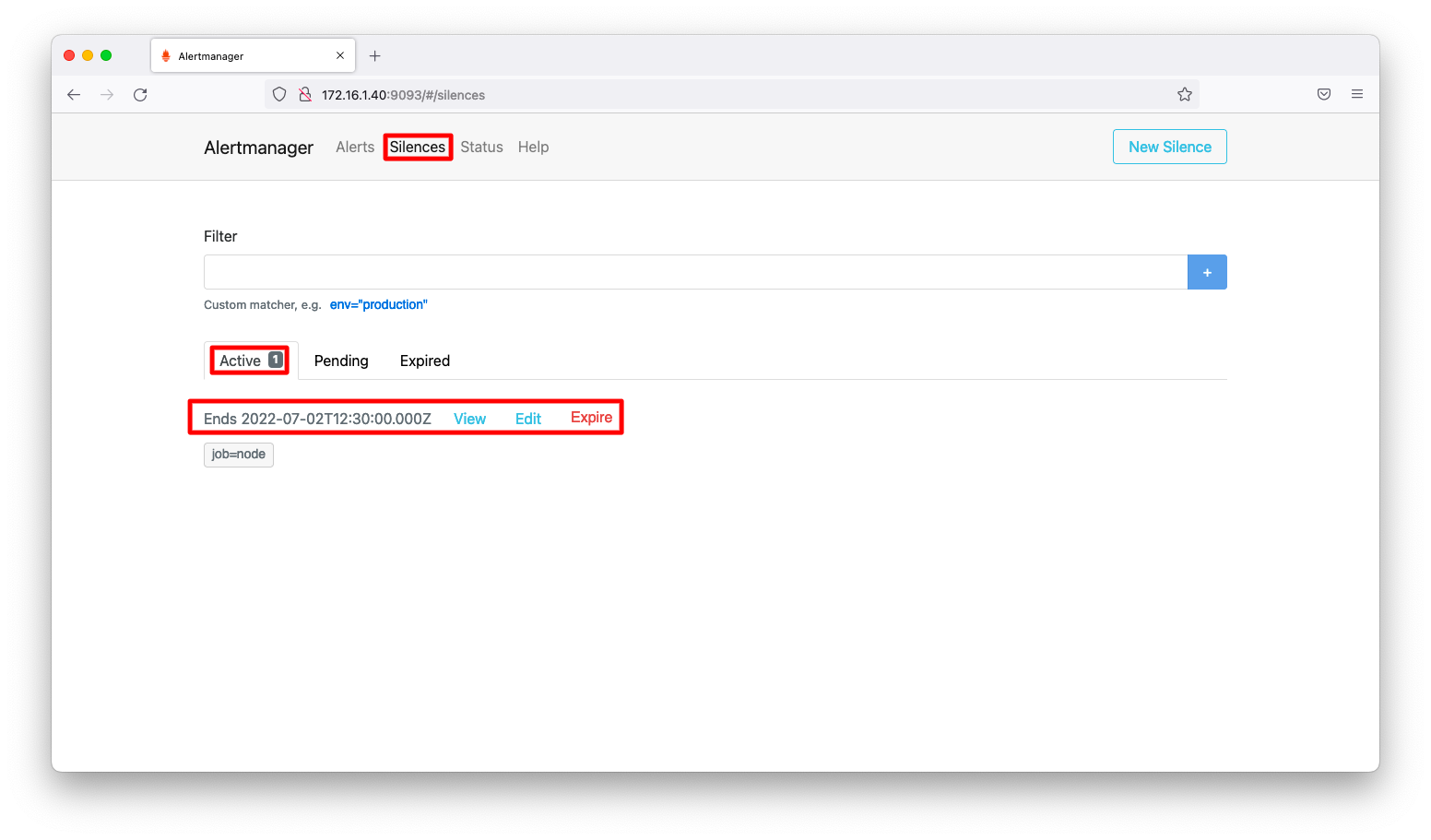
今現在の抑止されているアラートは、「Silence」「Active」タブに表示されます。
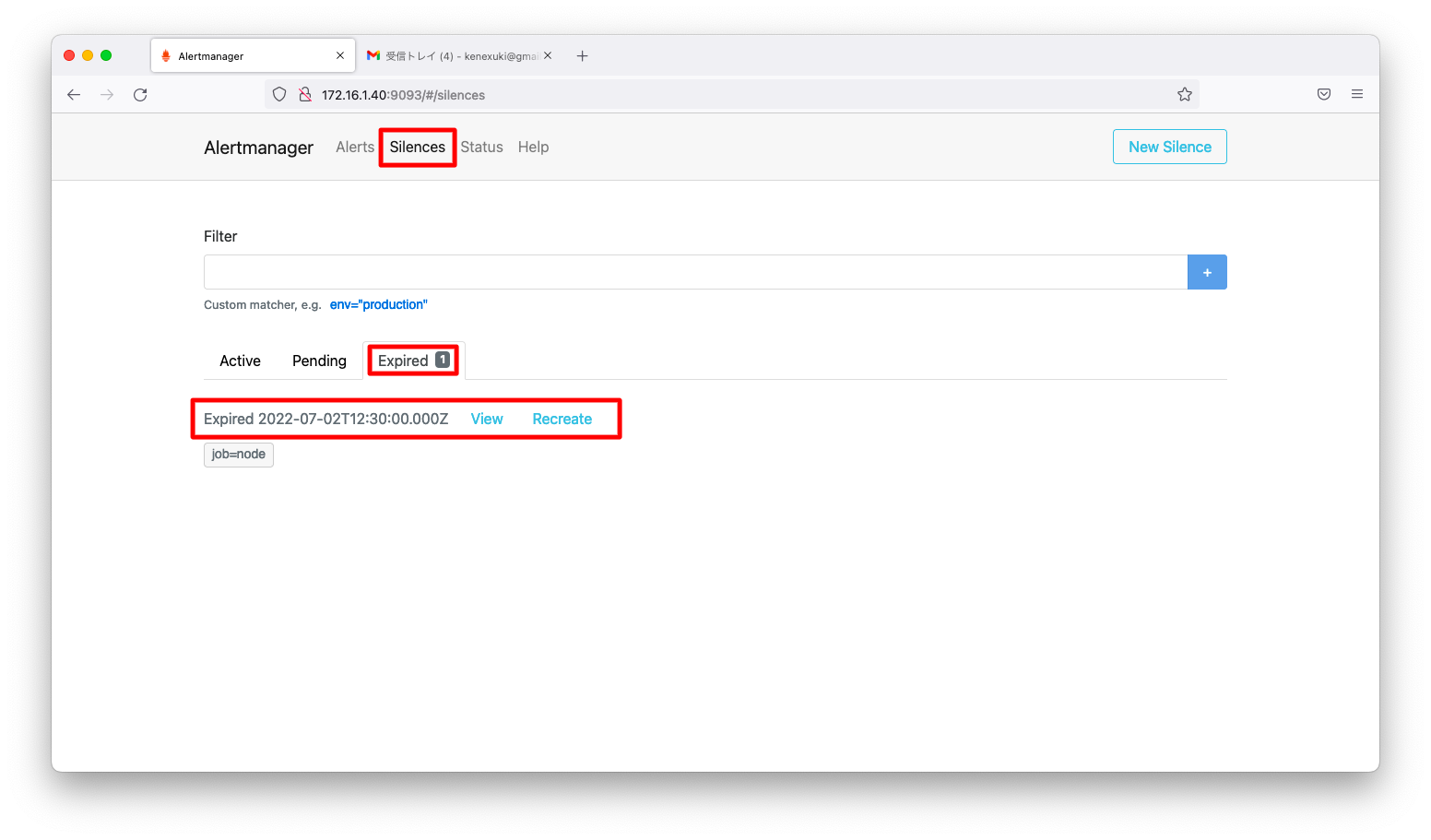
抑止が終了したアラートは、「Silence」「Expired」タブに表示されます。
アラート抑制の動作確認
前述の操作例では、日本時刻で19:00-21:30の期間でアラートを抑制しています。アラートメールの受信時刻を確認すると、確かに19:00-21:30を除く期間で受信している事が分かります。