PrometheusはPromQLというクエリ言語を用いて、メトリックを集計できます。ですが、都度、大量データを集計するのは高負荷になります。また、場合によっては集計結果のみ保存したいという要件もあるかもしれません。このような状況に備え、Prometheusは定期的にクエリを実行するレコーディングと呼ばれる機能を備えています。
前提
参照資料
動作確認済環境
- Rocky Linux 8.6
- Prometheus 2.36.2
- alertmanager 0.24.0
構成図
2台の仮想マシンに対して、以下コンポーネントがインストール済の状態とします。
+----------------+ +----------------+ | linux010 | | linux020 | | 172.16.1.10/24 | | 172.16.1.20/24 | | node_exporter | | node_exporter | | prometheus | | | +----------------+ +----------------+
テスト用クエリの作成
レコーディングの機能を使うには、PromQLで使用可能な関数を理解する必要があります。必要に応じて、公式資料「FUNCTIONS」を参照ください。このページでは、PromQLを何となく理解しつつ、レコーディング機能の動作確認用のクエリをサンプル提示します。
Prometheusのグラフ画面(http://<IPアドレス>9090/graph)で、検索窓に以下を入力します。すると、mode単位で詳細な情報が出力されます。
node_cpu_seconds_total
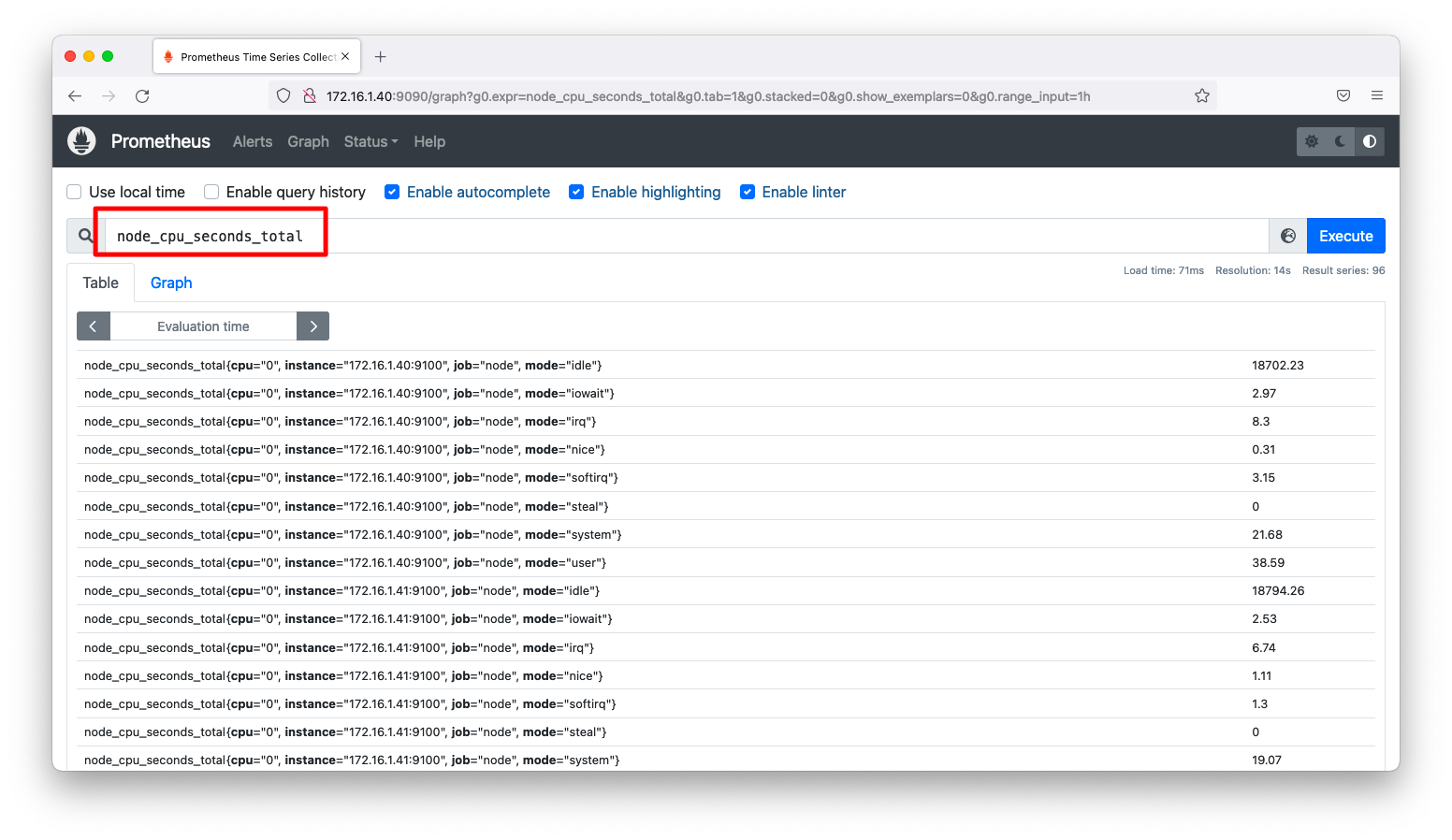
大雑把に情報を把握したいならば、idleのみ分かれば十分でしょう。modeというラベルがidleという値のものだけに絞り込むには以下のように指定します。
node_cpu_seconds_total{mode="idle"}
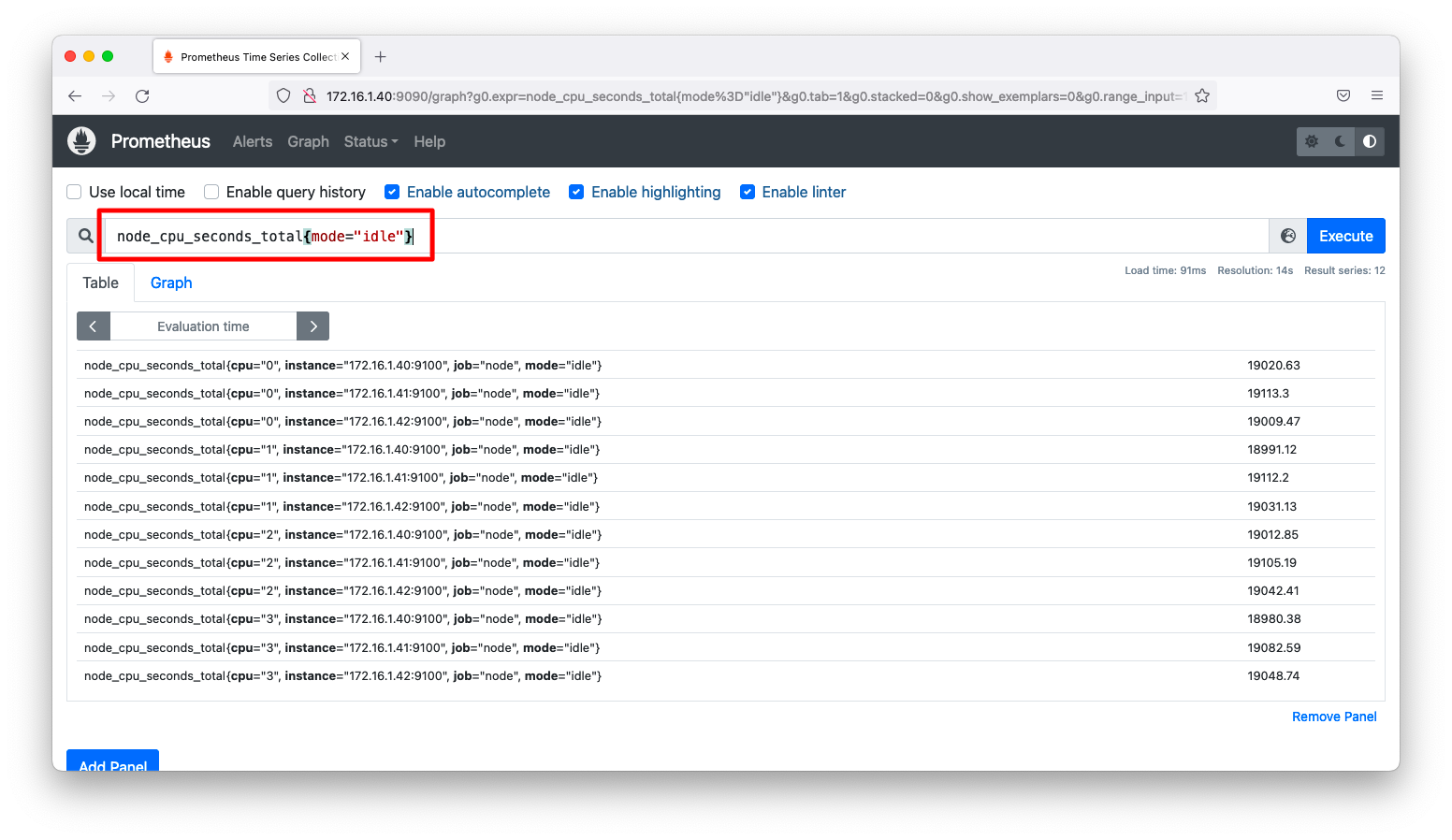
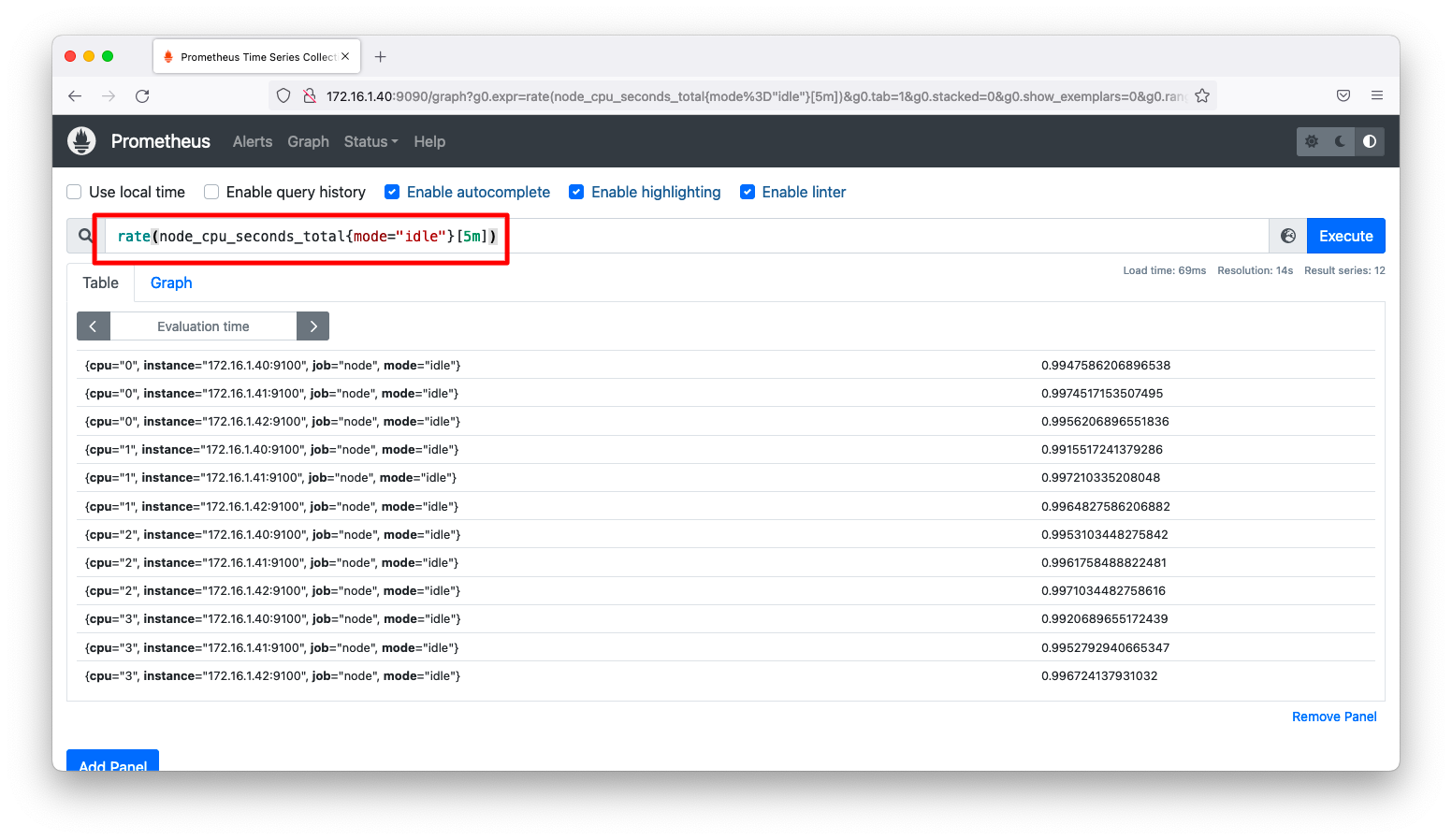
前述の操作で表示されるのは、サーバが起動してからのCPUがidle状態の時間です。これではCPU使用率が分かりづらいので、1秒あたりのidle時間に表示を変更しましょう。例えば、0.98を示すならばCPU使用率は2%になります。
このような情報を出力するのは、以下のように指定します。
rate(node_cpu_seconds_total{mode="idle"}[5m])
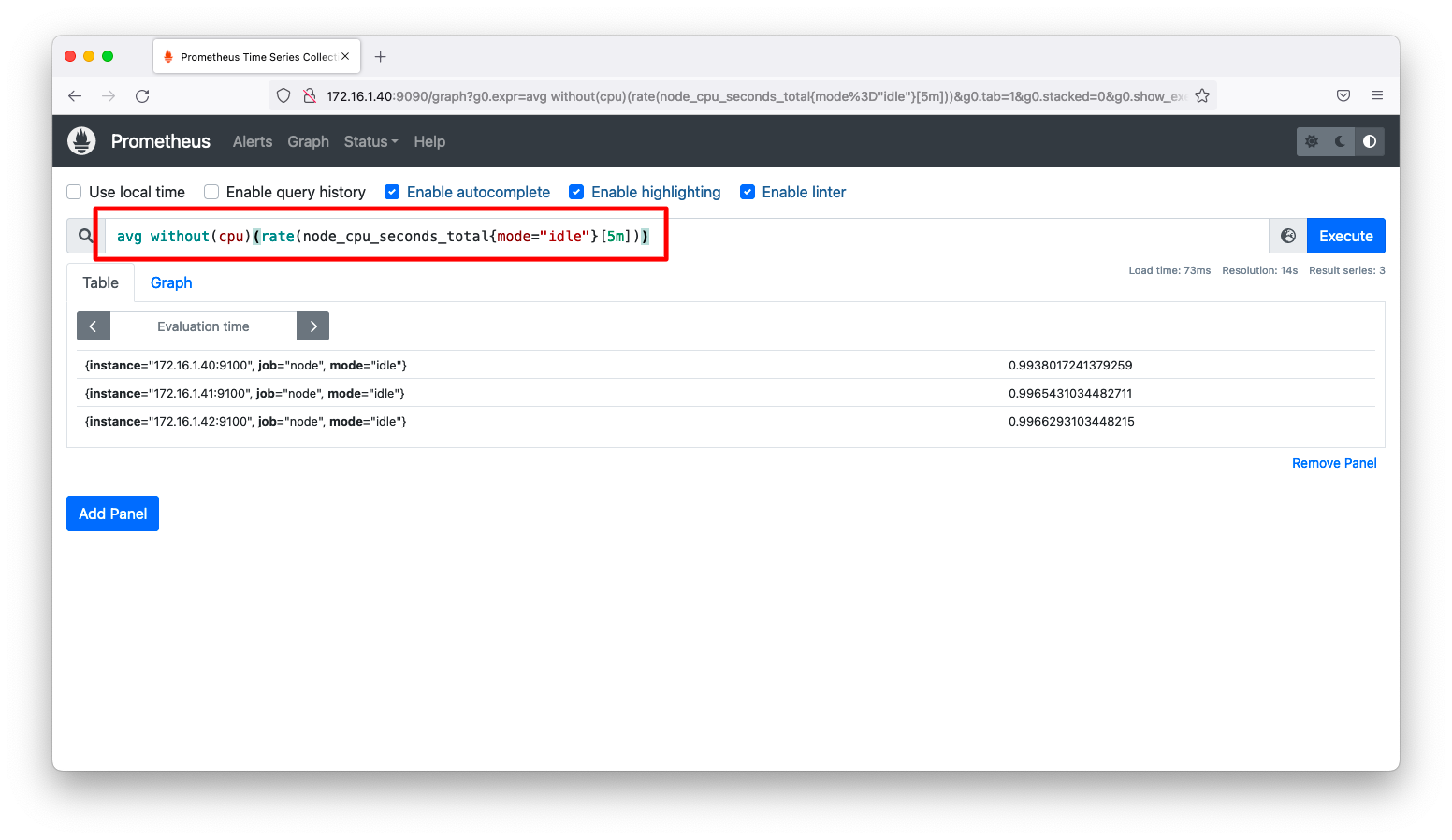
詳細なボトルネック分析をする時はコア単位のCPUを追跡する必要がありますが、概要の把握ならば全コアの平均値の方が都合が良いかもしれません。このような状況に対応するには、以下のように指定します。
avg without(cpu)(rate(node_cpu_seconds_total{mode="idle"}[5m]))
レコーディング
設定の作成
レコーディング機能を使うには、以下のようなrule_filesという指定を使います。具体的なルールは別のファイルに外出しする事ができます。
cat << EOF > /etc/prometheus/prometheus.yml
global:
scrape_interval: 10s
evaluation_interval: 10s
rule_files:
- rules.yml
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- 172.16.1.40:9090
- job_name: node
static_configs:
- targets:
- 172.16.1.40:9100
- 172.16.1.41:9100
- 172.16.1.42:9100
EOF
ルールの設定例は以下の通りです。exprにはPromQLで記述した計算式を入力し、recordはメトリック名を指定します。メトリック名は混乱を招かないよう機械的な命名ルールにすると良いでしょう。
cat << EOF > /etc/prometheus/rules.yml
groups:
- name: example
rules:
- record: job:node_cpu_seconds_total:rate5m
expr: avg without(cpu)(rate(node_cpu_seconds_total{mode="idle"}[5m]))
- record: job:process_open_fds:max
expr: max without(instance)(process_open_fds)
EOF
設定の反映
レコーディングルールを机上でミスなく記述するのは非常に難しいでしょう。ですので、prometheusには設定反映前に構文チェックをする機能があります。以下のようにpromtoolを使用すると、構文のエラー有無を確認できます。エラーがある場合は以下のようにFAILEDと表示されます。
[root@linux040 ~]# promtool check config /etc/prometheus/prometheus.yml
Checking /etc/prometheus/prometheus.yml
SUCCESS: 1 rule files found
SUCCESS: /etc/prometheus/prometheus.yml is valid prometheus config file syntax
Checking /etc/prometheus/rules.yml
FAILED:
/etc/prometheus/rules.yml: 5:15: group "example", rule 1, "job:node_cpu_seconds_total:rate5m": could not parse expression: 1:23: parse error: expected type range vector in call to function "rate", got instant vector
エラーなしの場合は以下のようにSUCCESSと表示されます。
[root@linux040 ~]# promtool check config /etc/prometheus/prometheus.yml Checking /etc/prometheus/prometheus.yml SUCCESS: 1 rule files found SUCCESS: /etc/prometheus/prometheus.yml is valid prometheus config file syntax Checking /etc/prometheus/rules.yml SUCCESS: 2 rules found
RPM版のPrometheusを使用している方はPrometheusのreloadで設定を反映できます。systemdを整備していない場合は、prometheusプロセスに対してHUPシグナルを送る事で設定を反映できます。
systemctl reload prometheus.service
動作確認
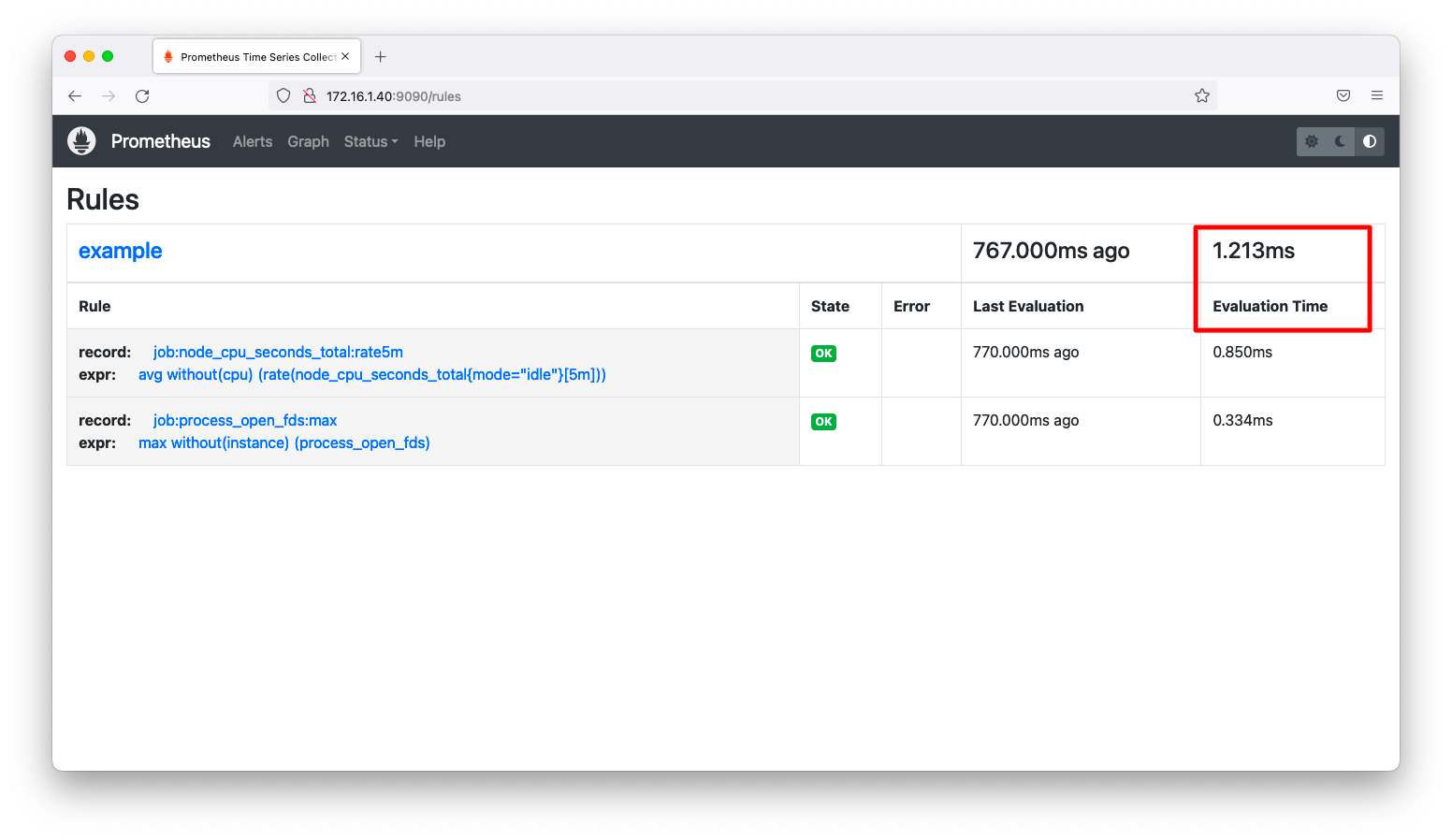
ルールページ(http://<IPアドレス>:9090/rules)をブラウザで閲覧すると、ルールの一覧が表示されます。念の為、Evaluation Timeをチェックしておきましょう。prometheus.ymlではevaluation_intervalを10秒と定義していますので、この値が10秒を超えると、集計が追いつかないほどの複雑なクエリを処理している事を意味します。
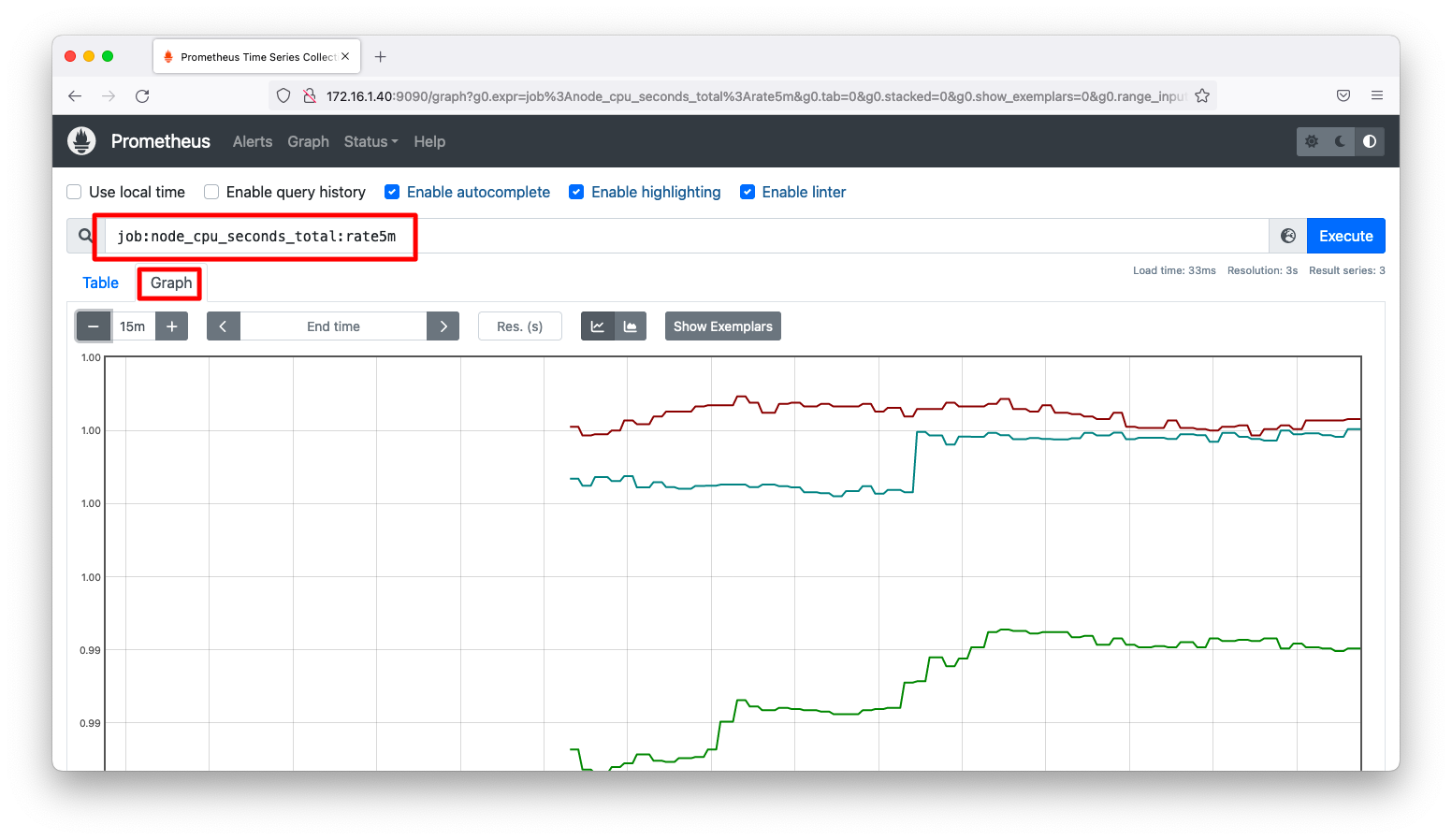
グラフページ(http://<IPアドレス>:9090/graph)をブラウザで開きます。rules.ymlで定義したメトリック名(例 : job:node_cpu_seconds_total:rate5m)を検索窓に入力し、グラフが描画される事を確認します。