Prometheusはコンテナやクラウドなどの大量コンポーネントを監視する事に特化したソフトウェアです。監視対象は大量に存在しますので、その監視対象を1つ1つ手作業で定義するのは非現実的です。このような問題に対応するため、Prometheusには監視対象を動的に検出するサービスディスカバリという機能が備わっています。このページではコンテナ(例:Docker)をサービスディスカバリする方法を説明します。
前提
参照資料
動作確認済環境
- Rocky Linux 8.6
- Prometheus 2.36.2
- Docker 20.10.16
cAdvisor
cAdvisorの起動
cAdvisorというコンテナを使用すると、コンテナの情報がprometheusが読み込める形式でexportされます。
docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:ro \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ --privileged \ --device=/dev/kmsg \ gcr.io/cadvisor/cadvisor
「http://<IPアドレス>:8080/metrics」へアクセスすると、Prometheusが読み込める形式でコンテナの情報が出力されるのが分かります。
[root@linux040 ~]# curl -s http://localhost:8080/metrics | head -n 20
# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="30515557",cadvisorVersion="v0.38.6",dockerVersion="20.10.16",kernelVersion="4.18.0-348.2.1.el8_5.x86_64",osVersion="Alpine Linux v3.12"} 1
# HELP container_cpu_load_average_10s Value of container cpu load average over the last 10 seconds.
# TYPE container_cpu_load_average_10s gauge
container_cpu_load_average_10s{id="/",image="",name=""} 0 1652697613107
container_cpu_load_average_10s{id="/docker",image="",name=""} 0 1652697613637
container_cpu_load_average_10s{id="/docker/130413466d00a78ec878bf1bbdea7ca31586cee581acad66134565a09676f30a",image="gcr.io/cadvisor/cadvisor",name="cadvisor"} 0 1652697613824
container_cpu_load_average_10s{id="/init.scope",image="",name=""} 0 1652697609458
container_cpu_load_average_10s{id="/system.slice",image="",name=""} 0 1652697614511
container_cpu_load_average_10s{id="/system.slice/NetworkManager-wait-online.service",image="",name=""} 0 1652697599505
container_cpu_load_average_10s{id="/system.slice/NetworkManager.service",image="",name=""} 0 1652697613818
container_cpu_load_average_10s{id="/system.slice/auditd.service",image="",name=""} 0 1652697610690
container_cpu_load_average_10s{id="/system.slice/chronyd.service",image="",name=""} 0 1652697612820
container_cpu_load_average_10s{id="/system.slice/containerd.service",image="",name=""} 0 1652697614053
container_cpu_load_average_10s{id="/system.slice/crond.service",image="",name=""} 0 1652697598933
container_cpu_load_average_10s{id="/system.slice/dbus.service",image="",name=""} 0 1652697604632
container_cpu_load_average_10s{id="/system.slice/dbus.socket",image="",name=""} 0 1652697603055
container_cpu_load_average_10s{id="/system.slice/dev-disk-by\\x2did-dm\\x2dname\\x2drl\\x2dswap.swap",image="",name=""} 0 1652697594790
container_cpu_load_average_10s{id="/system.slice/dev-disk-by\\x2did-dm\\x2duuid\\x2dLVM\\x2dJG5rXBqBPNU39ZPvVq5acZjWQCtNMoM2Ei3NZl79LgC9HkDOGA5pVSo1haNwdWRg.swap",image="",name=""} 0 1652697606283
prometheus.ymlの設定例
/etc/prometheus/prometheus.ymlを以下のように編集し、cAdvisorが出力するメトリックをスクレイプするようにします。
Prometheusの操作は説明を省略します。
global:
scrape_interval: 10s
scrape_configs:
- job_name: cAdvisor
static_configs:
- targets:
- localhost:8080
動作確認
テスト用コンテナの起動
動的にコンテナを検出できるかどうかを確認するため、テスト用のコンテナを2つ起動します。
docker run -d \ --name nginx01 \ --publish=8000:80 \ nginx docker run -d \ --name nginx02 \ --publish=8001:80 \ nginx
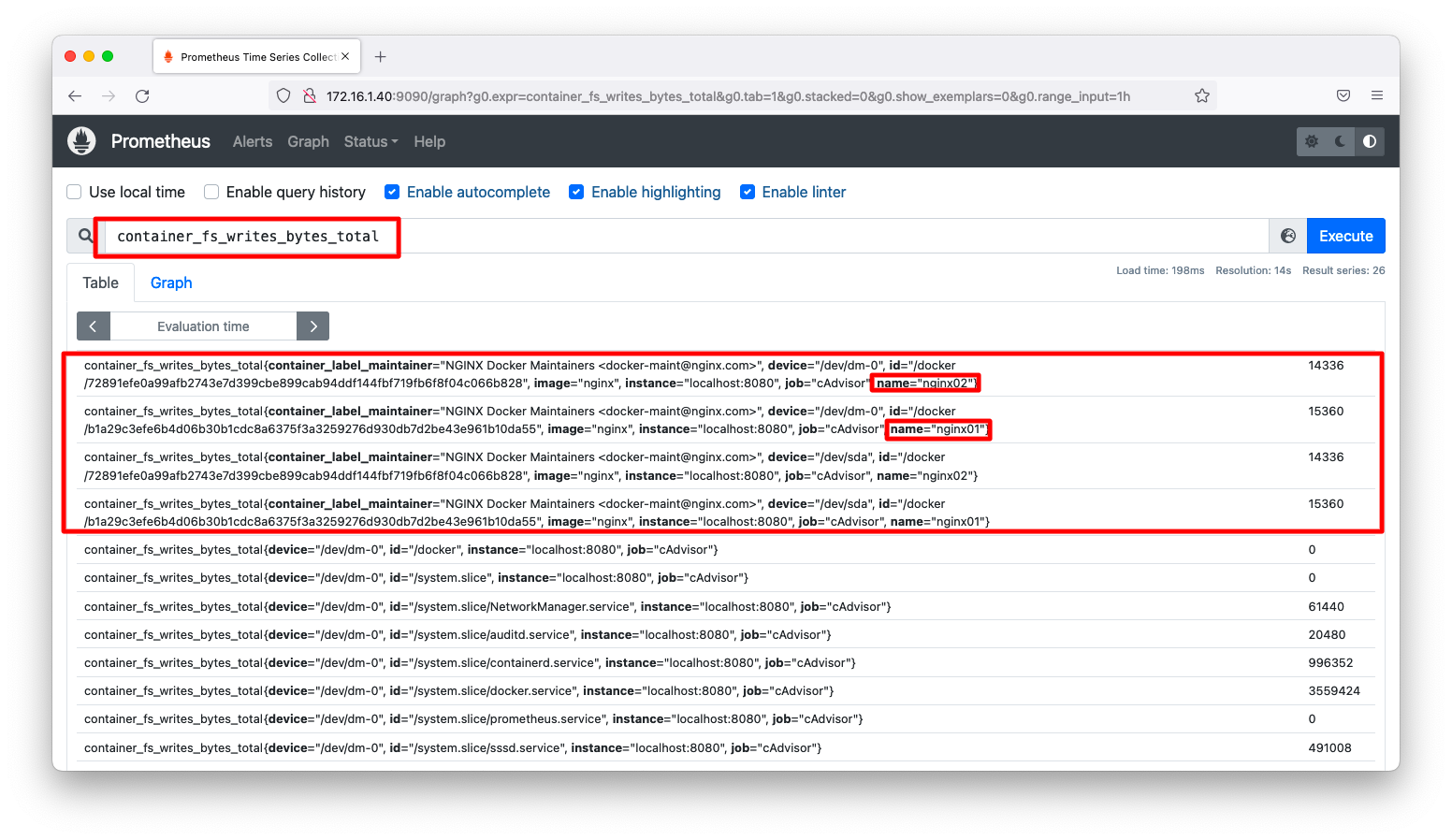
画面確認
グラフ画面(http://<IPアドレス>:9090/graph/)をブラウザで開きます。「container_」で始まるメトリックはコンテナに関する情報を表します。検索窓に「container_fs_writes_bytes_total」と入力すると、nginx01, nginx02の2つのコンテナの情報が出力される事が分かります。