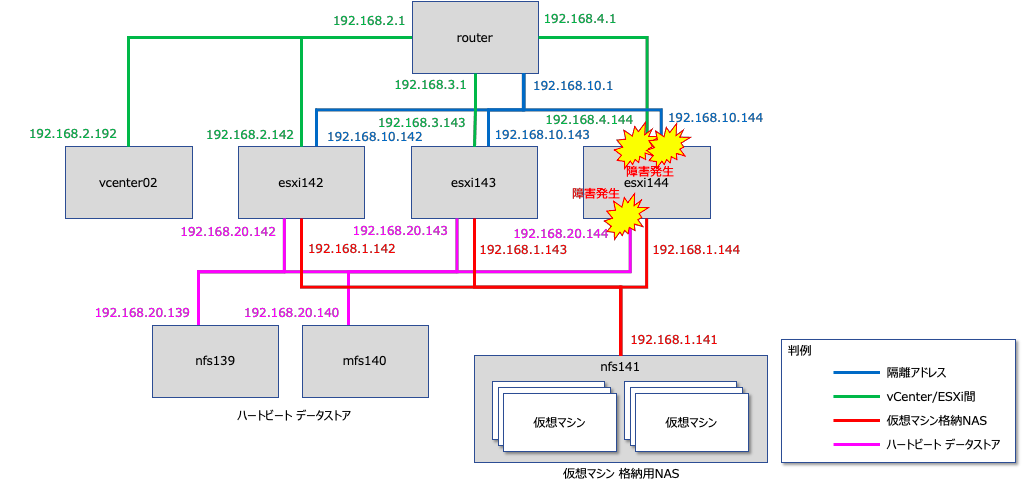
vSphere HAの挙動と可用性設定についてまとめます。vSphere HAはvCenterがESXiを監視するだけでなく、プライマリサーバとなるESXiが他のESXiを監視したり、隔離アドレスと呼ばれるIPアドレスへのicmp疎通確認をするなどの様々な障害検出の仕組みを備えています。
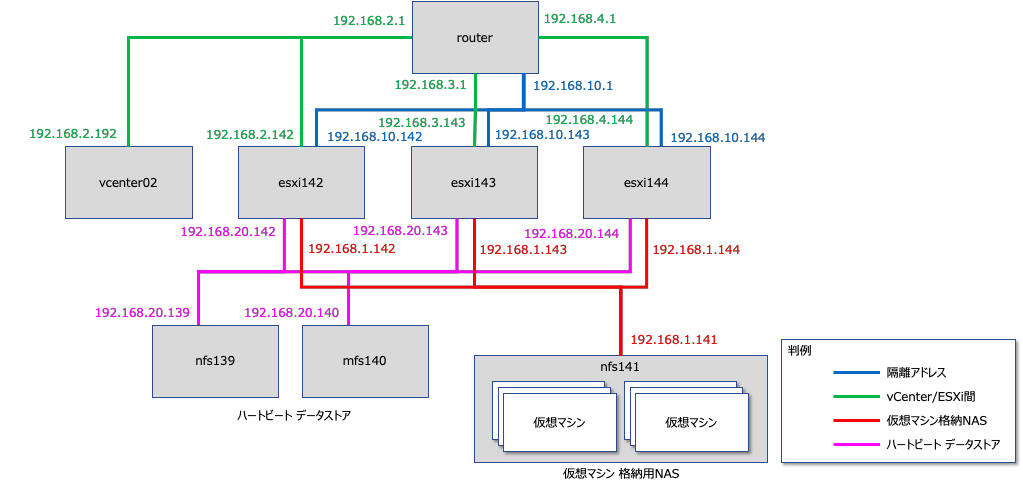
構成図
以下の環境で動作確認をします。
通信のまとめ
vCenterからESXiへ
vCenterはESXiを管理します。もし、vCenterからESXiへの疎通が出来なくなった場合は、vCenterはESXiに何らかの障害が発生したと判断します。
ESXiプライマリからへESXiセカンダリへ
vSphere HAクラスタが作成されると、ESXiのうちの1台がプライマリとして選定されます。プライマリはセカンダリへの疎通を試み、セカンダリの死活監視をします。
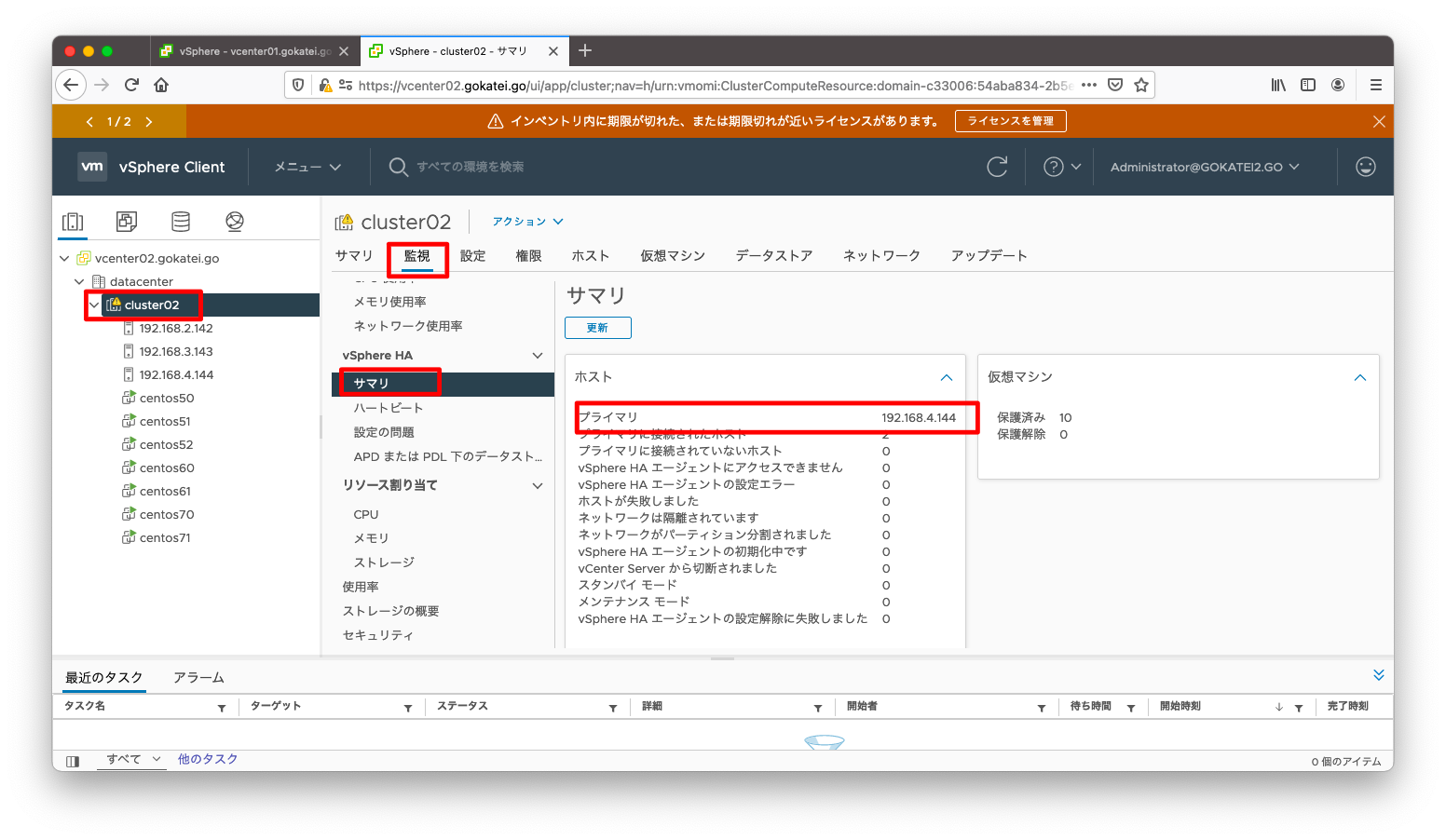
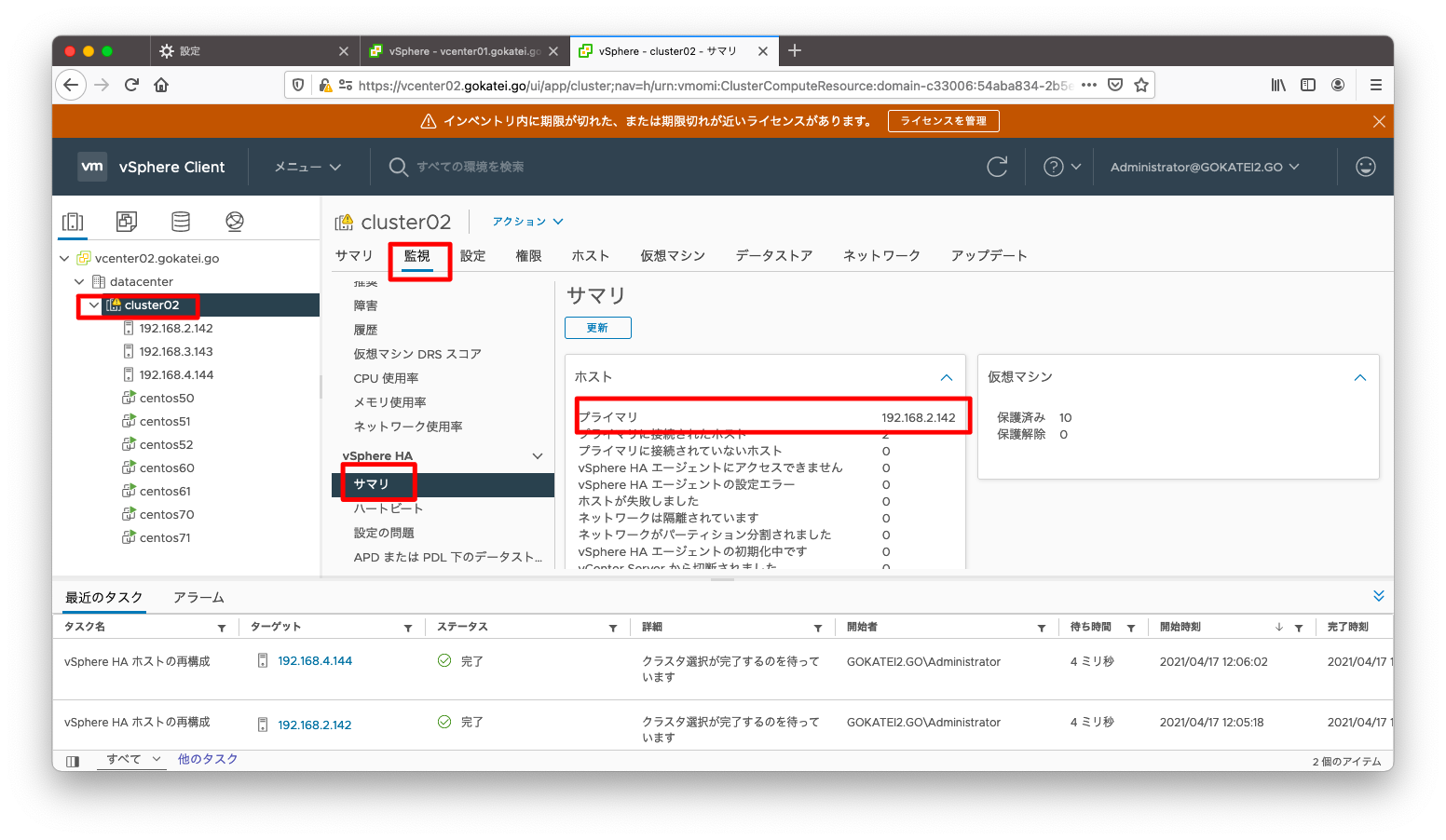
どのESXiがプライマリになっているかは、vCenterの画面にて、「クラスタ名」「監視」「vSphere HA / サマリ」の順に選択する事で確認する事ができます。
パケットキャプチャを取得すると、UDP 8182 (vmware-fdm)による監視を試みている事が分かります。
[root@router020 ~]# tcpdump -i ens192.4 -nnn port 8182 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens192.4, link-type EN10MB (Ethernet), capture size 262144 bytes 20:05:20.991300 IP 192.168.4.144.8182 > 192.168.2.142.8182: UDP, length 312 20:05:20.991325 IP 192.168.4.144.8182 > 192.168.3.143.8182: UDP, length 312 20:05:21.469285 IP 192.168.4.144.8182 > 192.168.3.143.59755: Flags [P.], seq 3403622155:3403622192, ack 3309423501, win 130, options [nop,nop,TS val 209904640 ecr 4061053990], length 37 20:05:21.469305 IP 192.168.4.144.8182 > 192.168.2.142.10408: Flags [P.], seq 3404588867:3404588904, ack 1638299931, win 130, options [nop,nop,TS val 2711478081 ecr 3222932063], length 37 20:05:21.470096 IP 192.168.3.143.59755 > 192.168.4.144.8182: Flags [P.], seq 1:38, ack 37, win 130, options [nop,nop,TS val 4061054091 ecr 209904640], length 37 20:05:21.470128 IP 192.168.2.142.10408 > 192.168.4.144.8182: Flags [P.], seq 1:38, ack 37, win 130, options [nop,nop,TS val 3222932164 ecr 2711478081], length 37 20:05:21.586587 IP 192.168.4.144.8182 > 192.168.2.142.10408: Flags [.], ack 38, win 130, options [nop,nop,TS val 2711478093 ecr 3222932164], length 0 20:05:21.586607 IP 192.168.4.144.8182 > 192.168.3.143.59755: Flags [.], ack 38, win 130, options [nop,nop,TS val 209904652 ecr 4061054091], length 0 20:05:21.992307 IP 192.168.4.144.8182 > 192.168.2.142.8182: UDP, length 312 20:05:21.992345 IP 192.168.4.144.8182 > 192.168.3.143.8182: UDP, length 312
隔離アドレスへのping確認
ESXiは隔離アドレスへのpingを試み、障害発生時に「パーティション(分断された状態)」「隔離(孤立した状態)」「障害」のどの状態なのかを判定します。
デフォルトの状態では隔離アドレスはvmkのデフォルトゲートウェイになっています。もし、デフォルトゲートフェイが設定されていない場合は、隔離アドレスへのpingを試みない挙動になっており、「パーティション(分断された状態)」か「隔離(孤立した状態)」かの判断はしません。
隔離アドレスを設定したルータにてパケットキャプチャを実施すると、ESXiが定期的にpingを試みている事が分かります。
[root@router020 ~]# tcpdump -i ens224.10 -nnn icmp tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens224.10, link-type EN10MB (Ethernet), capture size 262144 bytes 20:31:58.091028 IP 192.168.10.144 > 192.168.10.1: ICMP echo request, id 2727, seq 22, length 87 20:31:58.091092 IP 192.168.10.1 > 192.168.10.144: ICMP echo reply, id 2727, seq 22, length 87 20:31:58.102064 IP 192.168.10.142 > 192.168.10.1: ICMP echo request, id 2883, seq 22, length 87 20:31:58.102074 IP 192.168.10.1 > 192.168.10.142: ICMP echo reply, id 2883, seq 22, length 87 20:31:58.110568 IP 192.168.10.143 > 192.168.10.1: ICMP echo request, id 3024, seq 22, length 87 20:31:58.110599 IP 192.168.10.1 > 192.168.10.143: ICMP echo reply, id 3024, seq 22, length 87 20:36:58.093116 IP 192.168.10.144 > 192.168.10.1: ICMP echo request, id 2727, seq 23, length 87 20:36:58.093193 IP 192.168.10.1 > 192.168.10.144: ICMP echo reply, id 2727, seq 23, length 87 20:36:58.107094 IP 192.168.10.142 > 192.168.10.1: ICMP echo request, id 2883, seq 23, length 87 20:36:58.107147 IP 192.168.10.1 > 192.168.10.142: ICMP echo reply, id 2883, seq 23, length 87 20:36:58.114295 IP 192.168.10.143 > 192.168.10.1: ICMP echo request, id 3024, seq 23, length 87 20:36:58.114306 IP 192.168.10.1 > 192.168.10.143: ICMP echo reply, id 3024, seq 23, length 87
ハードビートデータストア
ハートビート データストアを定義することによって、データストアへの疎通が可能かどうかで、障害発生時に「パーティション(分断された状態)」「隔離(孤立した状態)」「障害」のどの状態なのかを判定します。
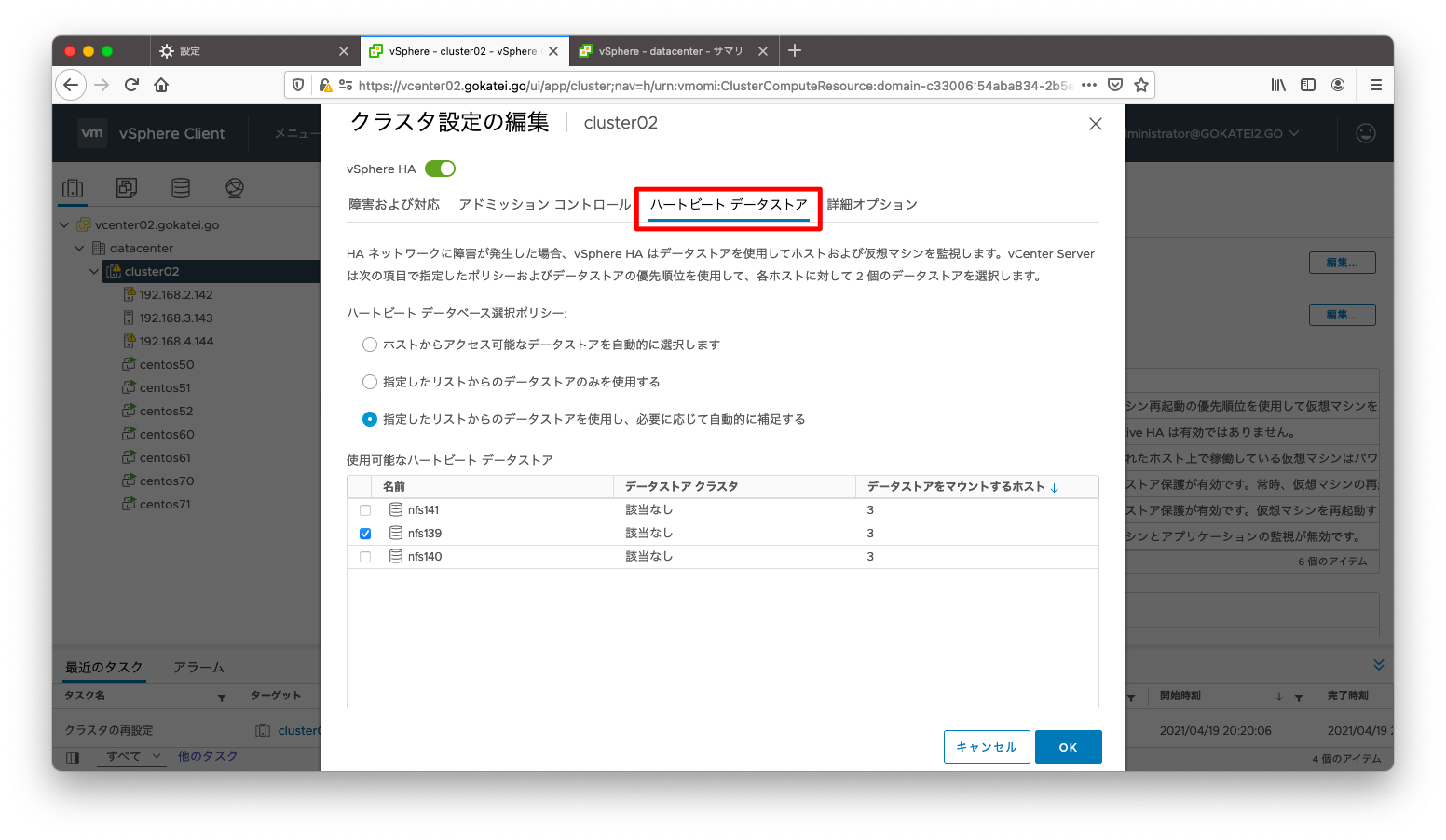
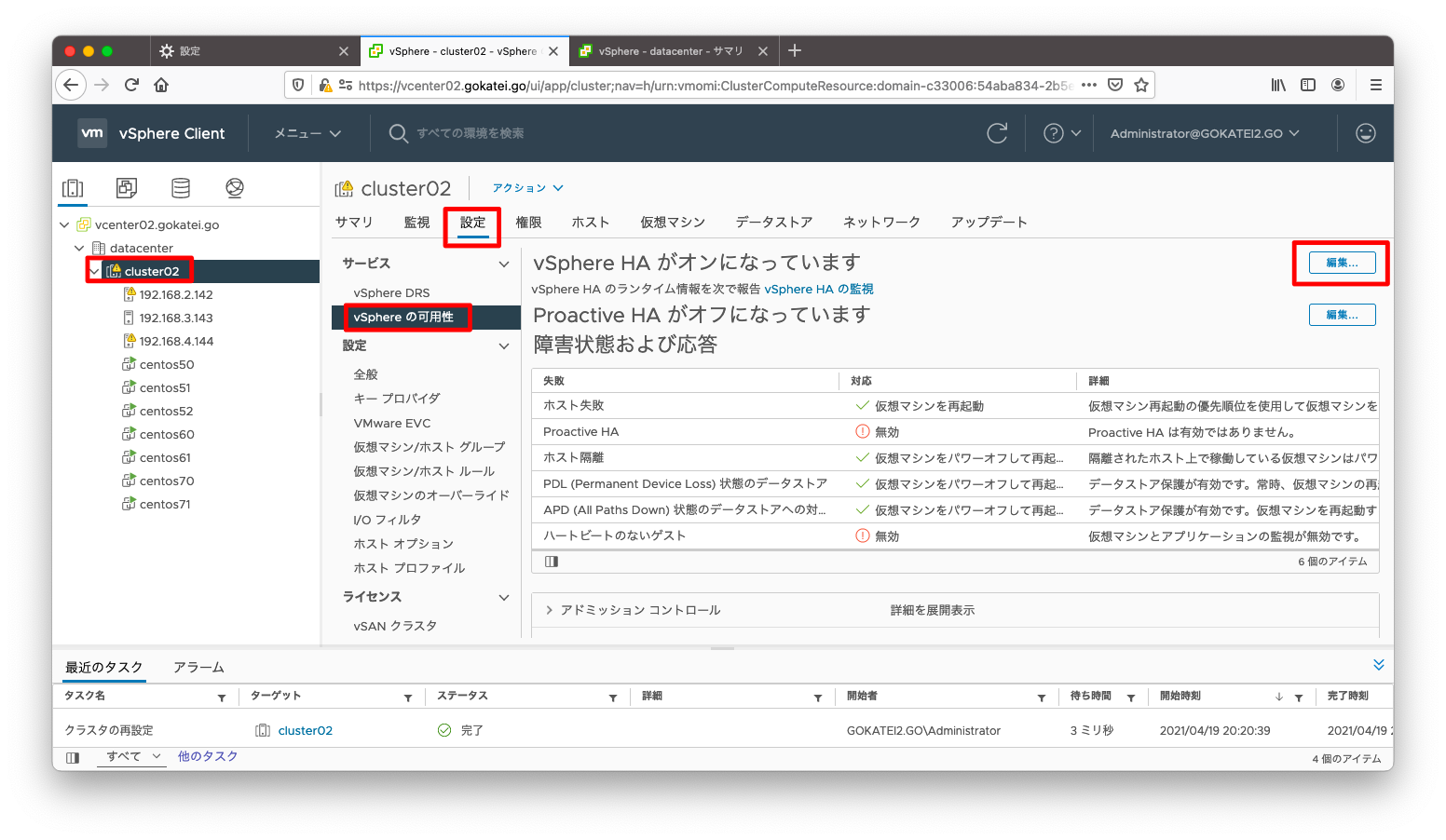
ハートビートデータストアを定義するには、vCenterの画面にて、「クラスタ名」「設定」「vSphereの可用性」「編集」の順に押下します。
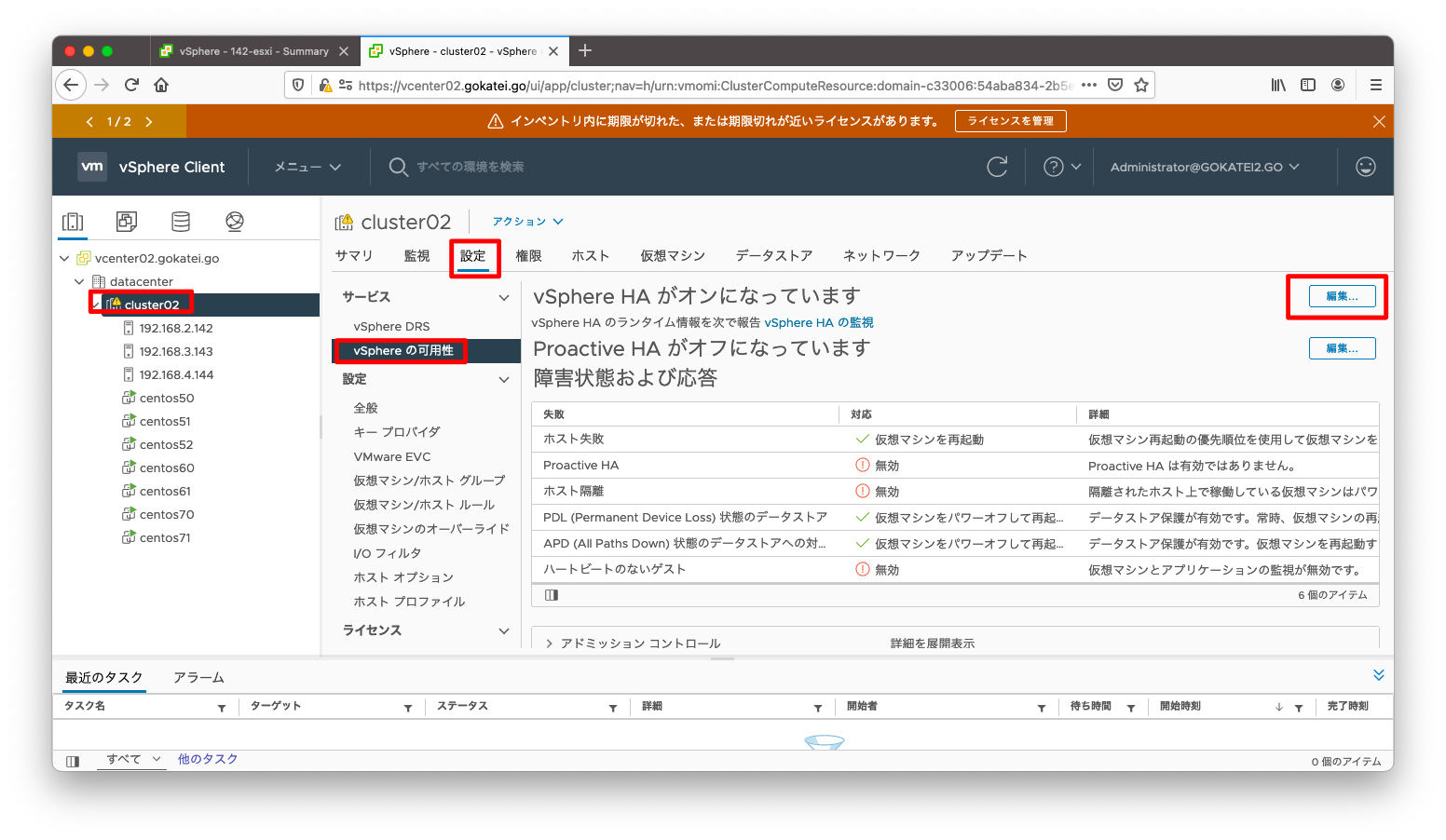
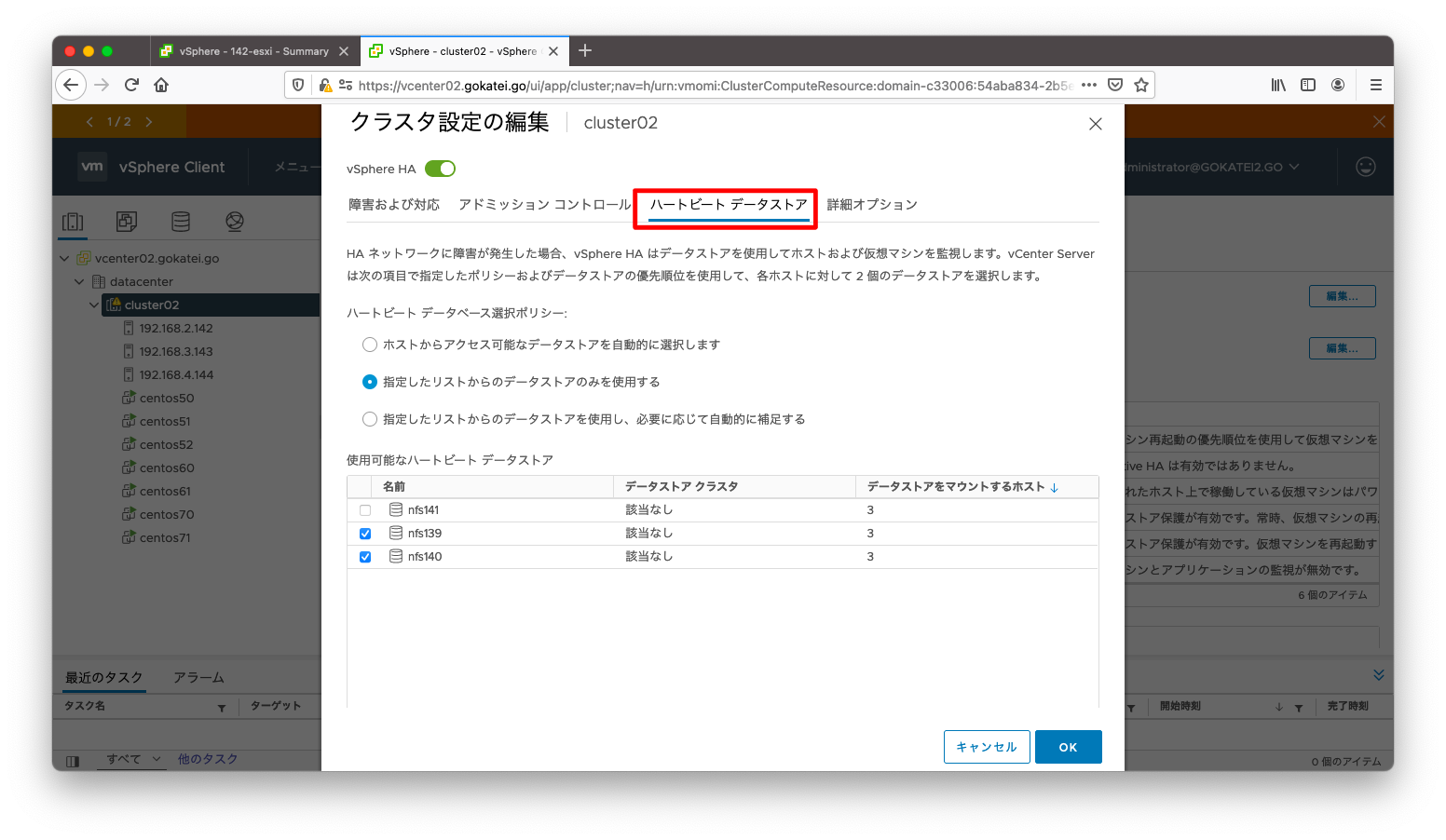
次に「ハートビート データストア」タブを押下することで、ハートビート データストアの選択が可能です。
障害発生時の挙動確認
前提条件
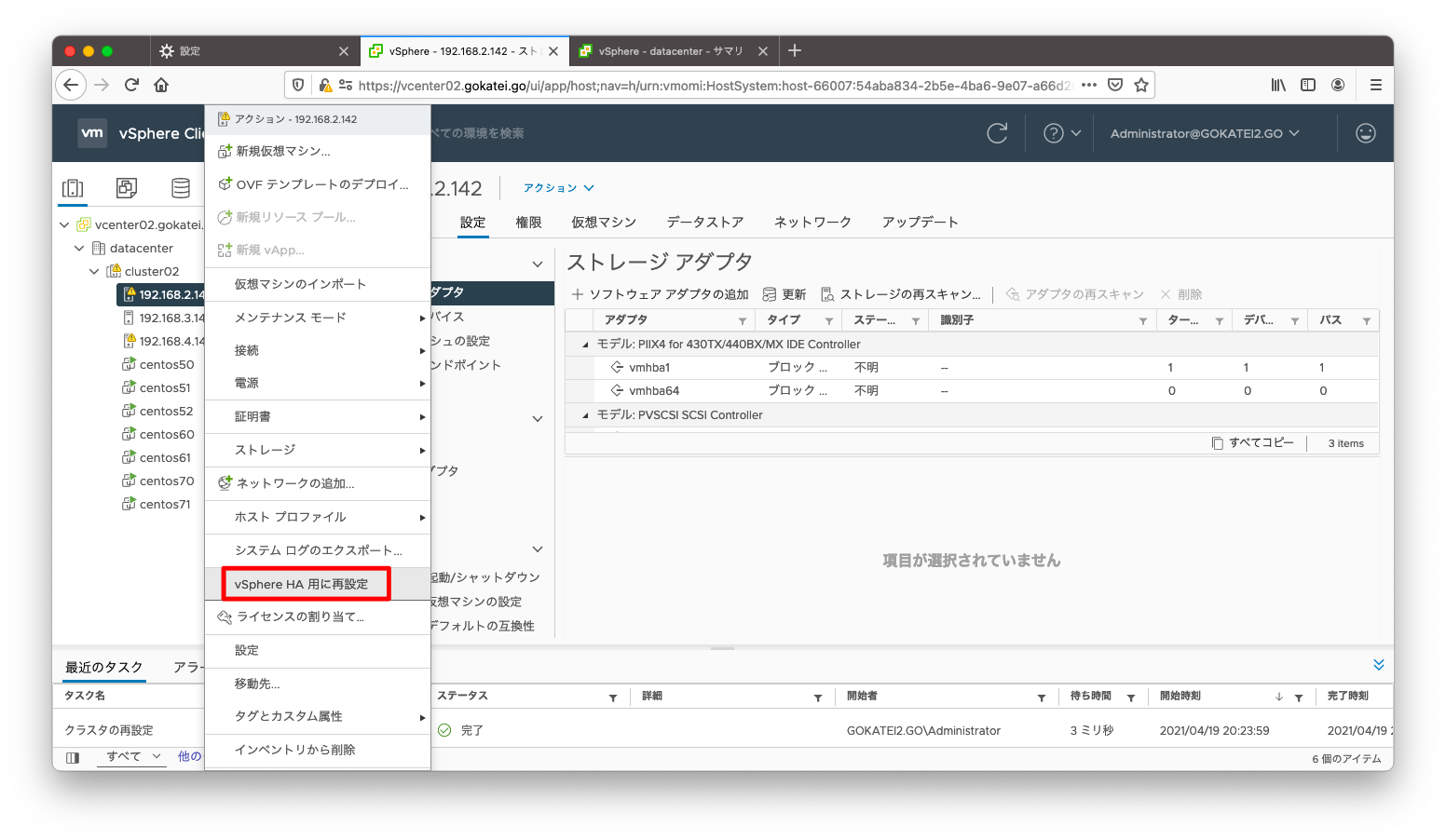
esxi142(192.168.2.142)がvSphere HAのプライマリとして選ばれている状態で動作確認をします。プライマリサーバを変更するには、 ESXiの右クリックメニューで「vSphere HA用に再設定」を選びます。
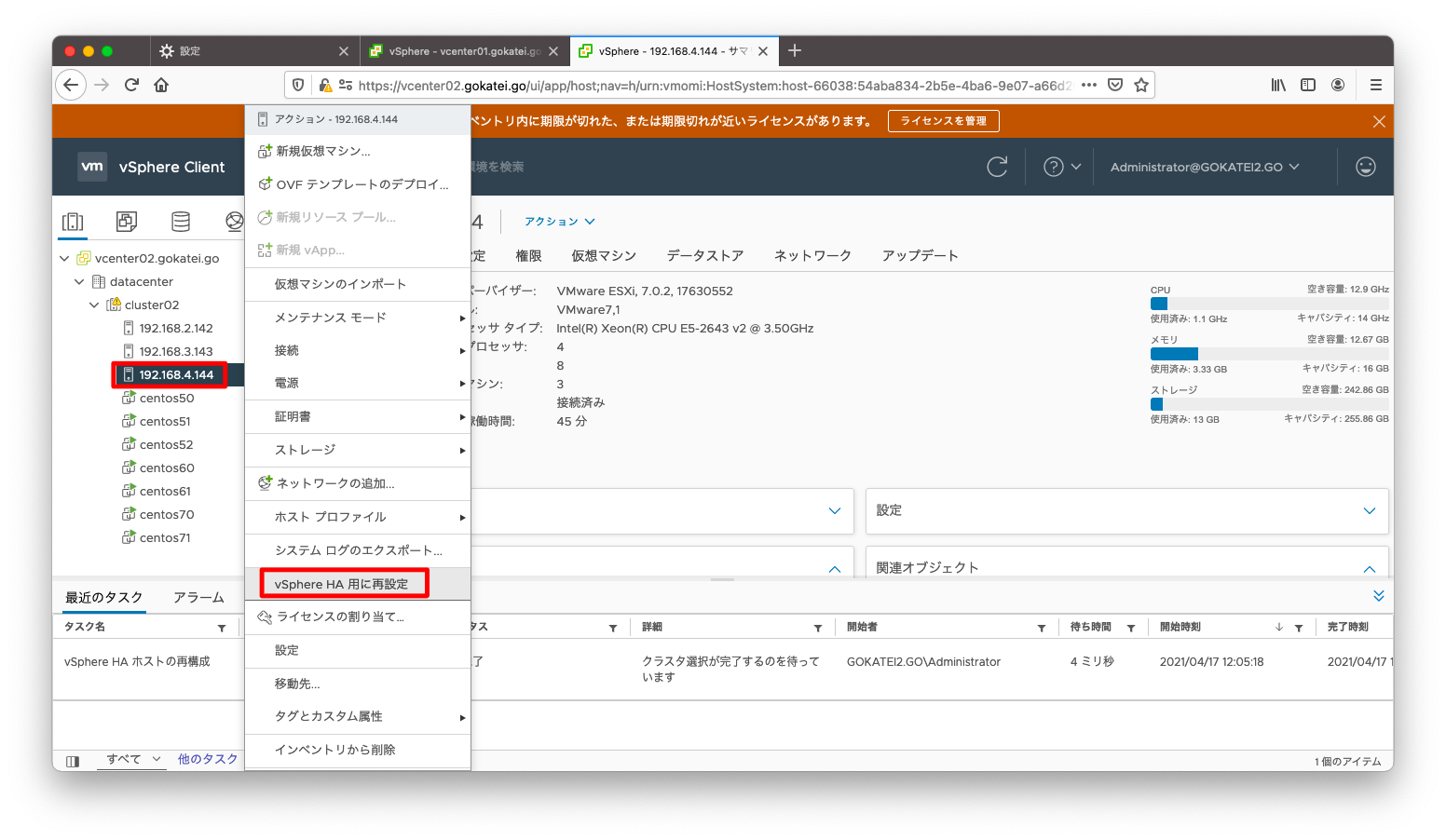
esxi142(192.168.2.142)がプライマリサーバとして選ばれた事を確認します。
vCenterとESXi間、ESXiとESXi間の通信障害
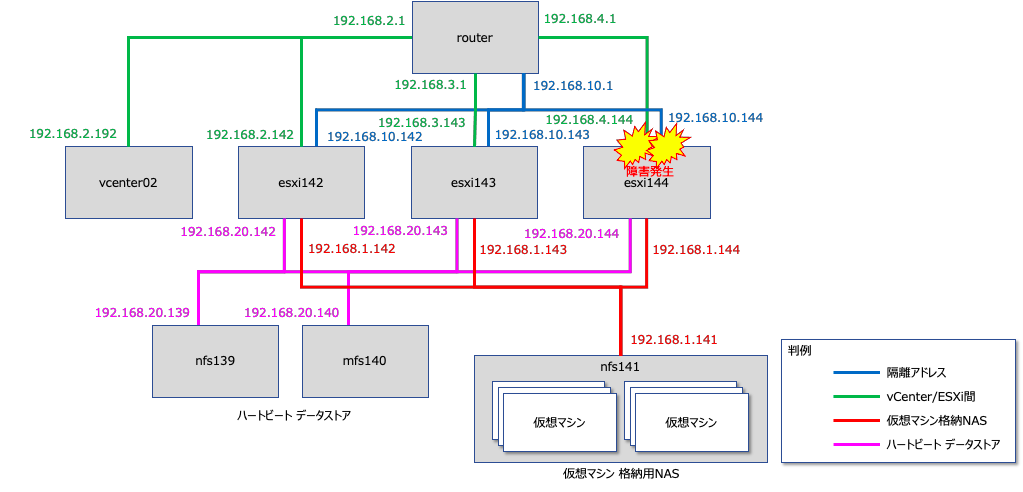
vCenterとESXi間、ESXiとESXi間の通信障害が起きた挙動を確認します。構成図で示すと以下の通りです。
障害発生方法は色々ありますが、Nested ESXi環境ならば、ホストOS側のネットワークを切断する事で障害を再現させる事ができます。
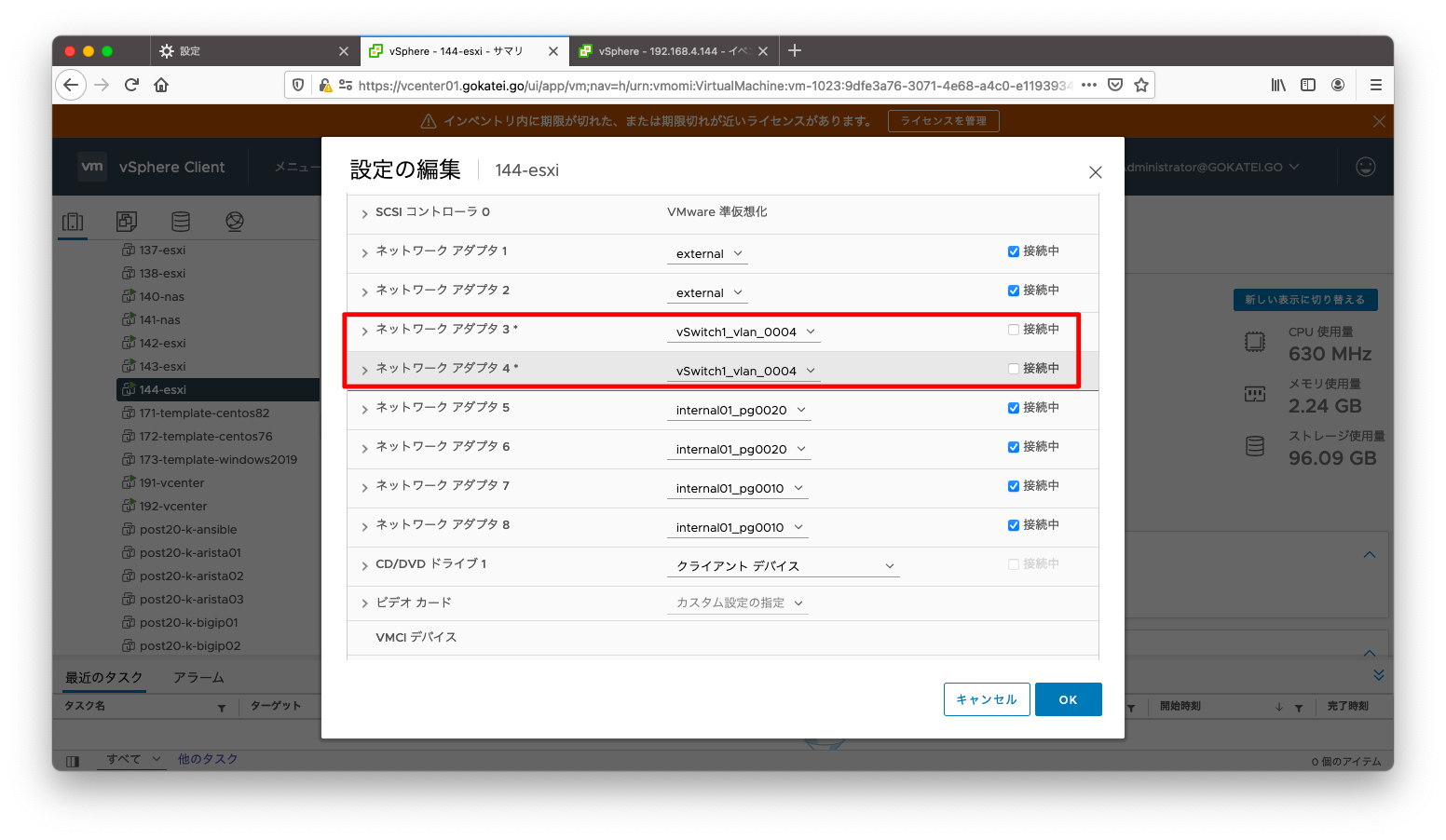
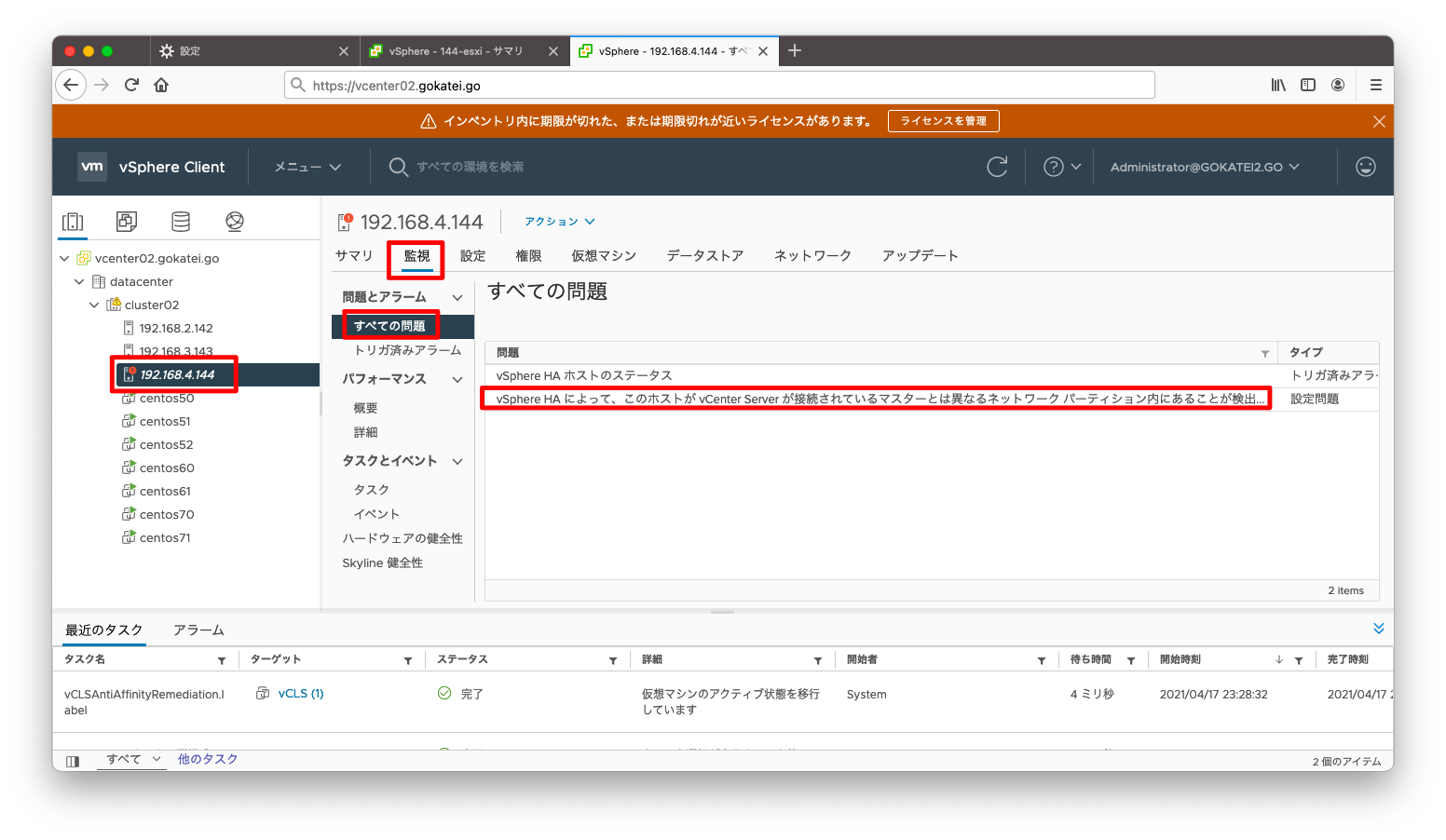
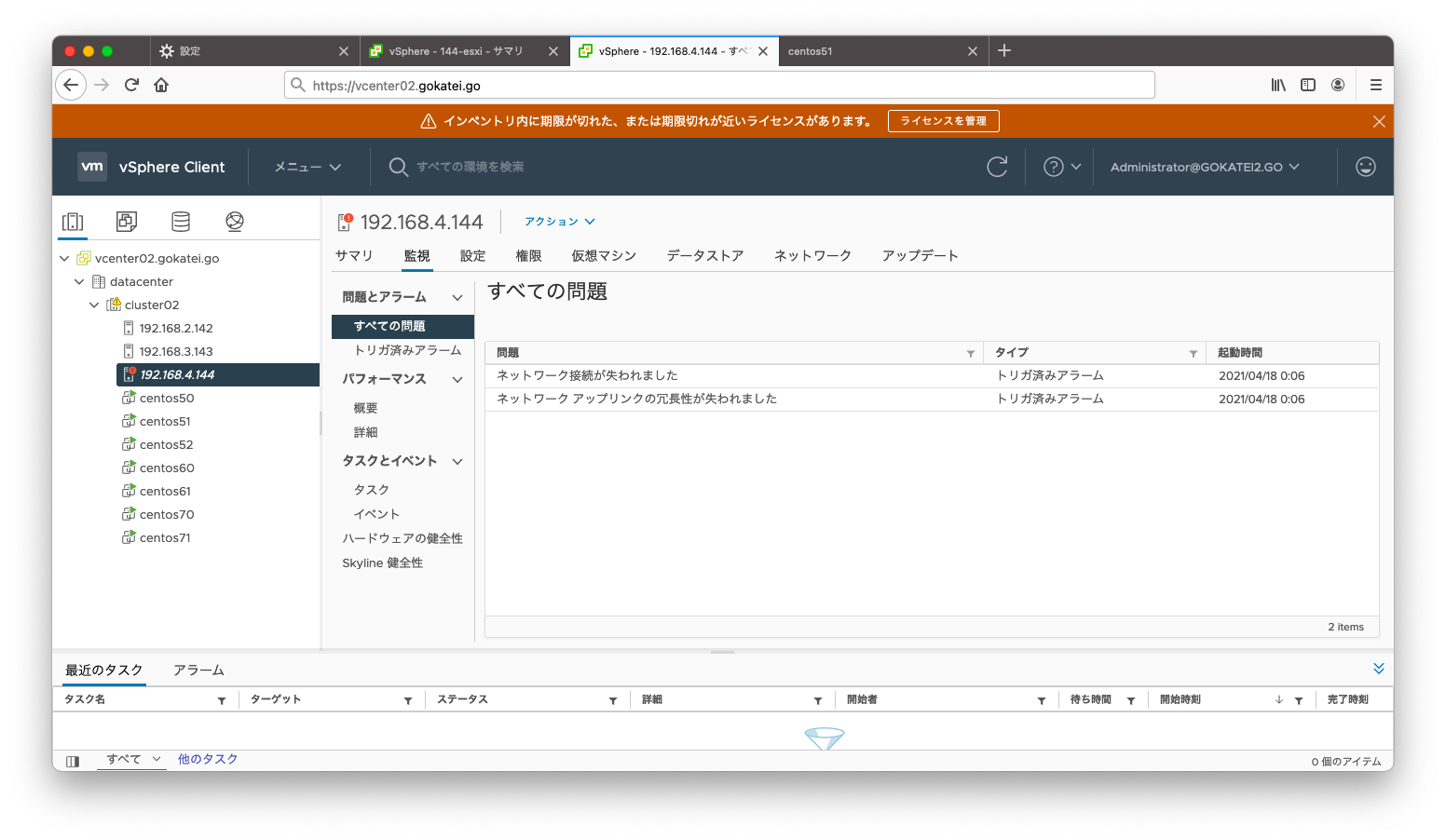
「すべての問題」を確認すると、「ホスト障害の可能性が検出されました」または「異なるネットワークパーティション内にあることが検出されました」とのメッセージが出力されています。
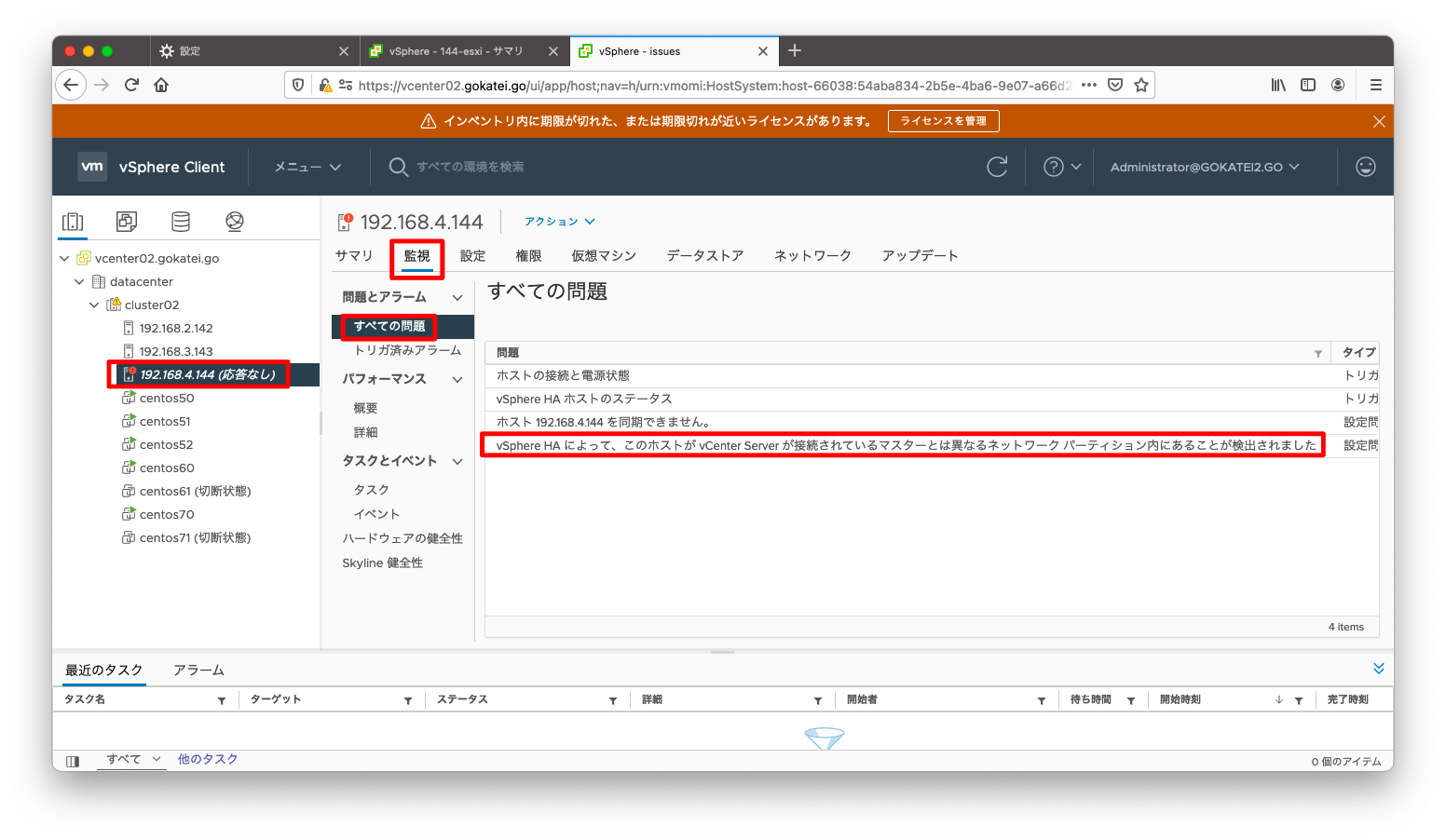
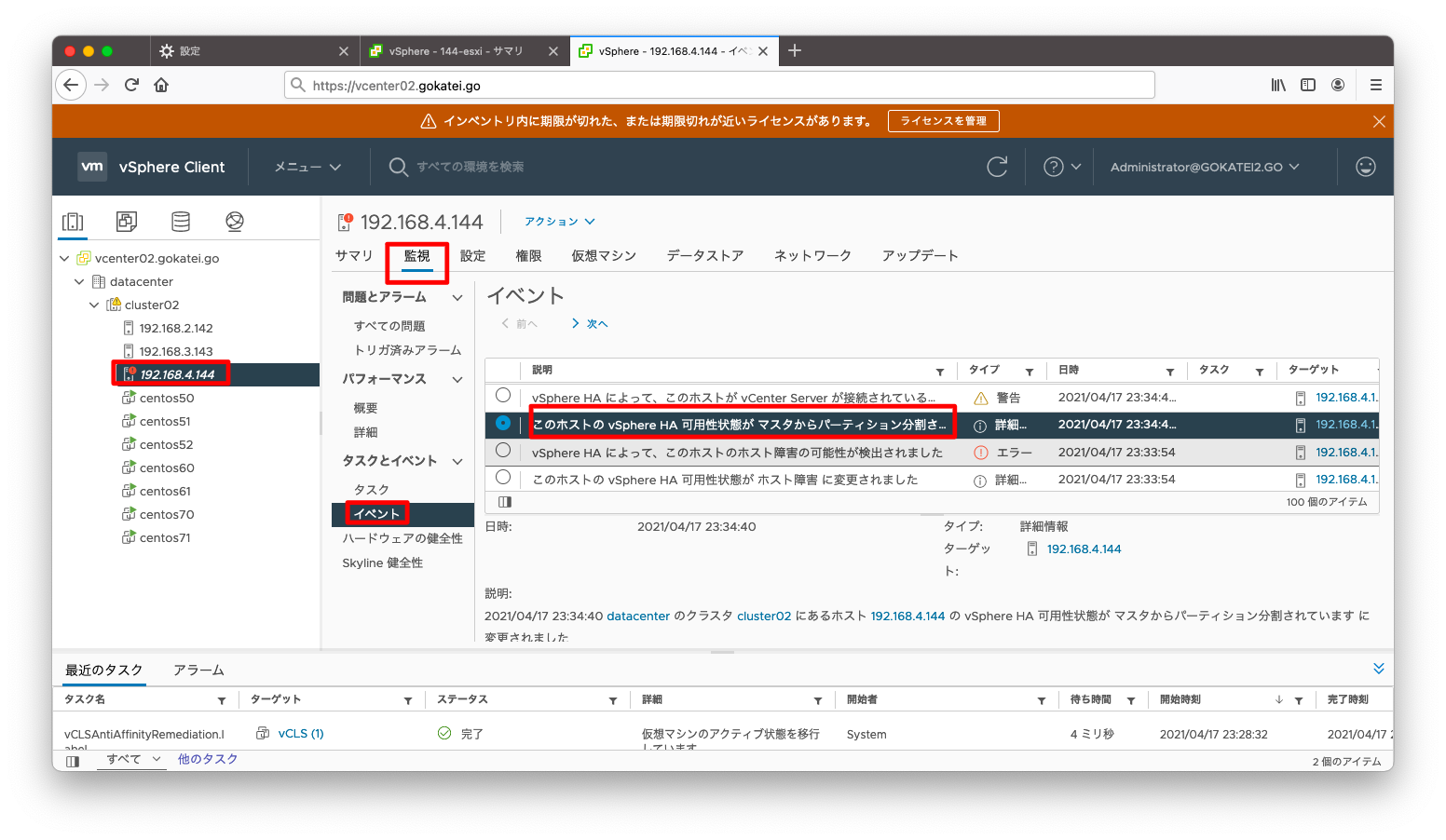
もしかしたら、障害の状態が時事刻々と変わる可能性もあるかもしれないので、「イベント」も併せて参照しましょう。
この辺りは検証不足で自信が持てず申し訳ございません。私の環境では「ホスト障害の可能性が検出されました」または「異なるネットワークパーティション内にあることが検出されました」の状態が繰り返し変更される状況になっています。この挙動が仕様か設定誤りかは確証が持てていません。
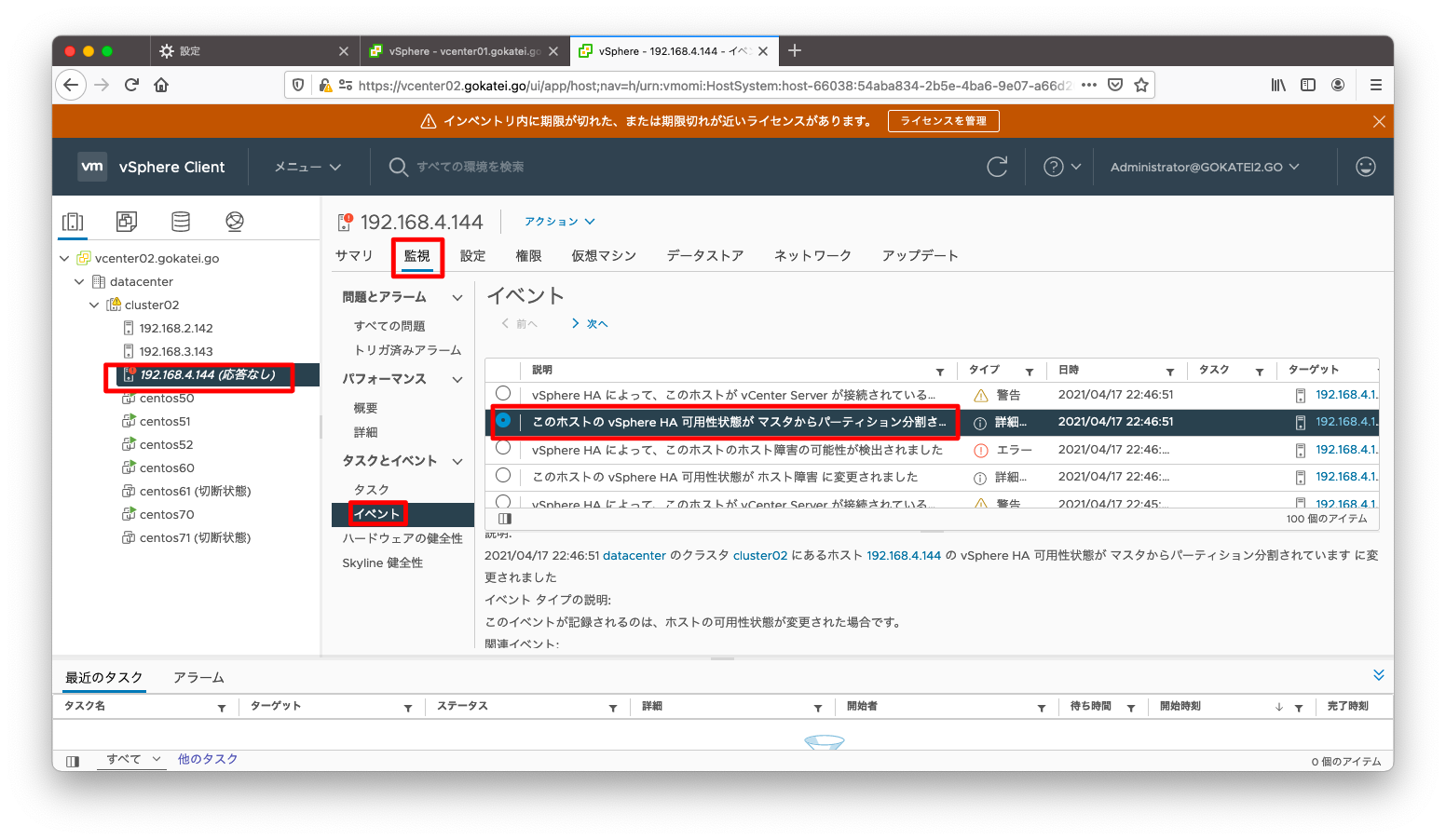
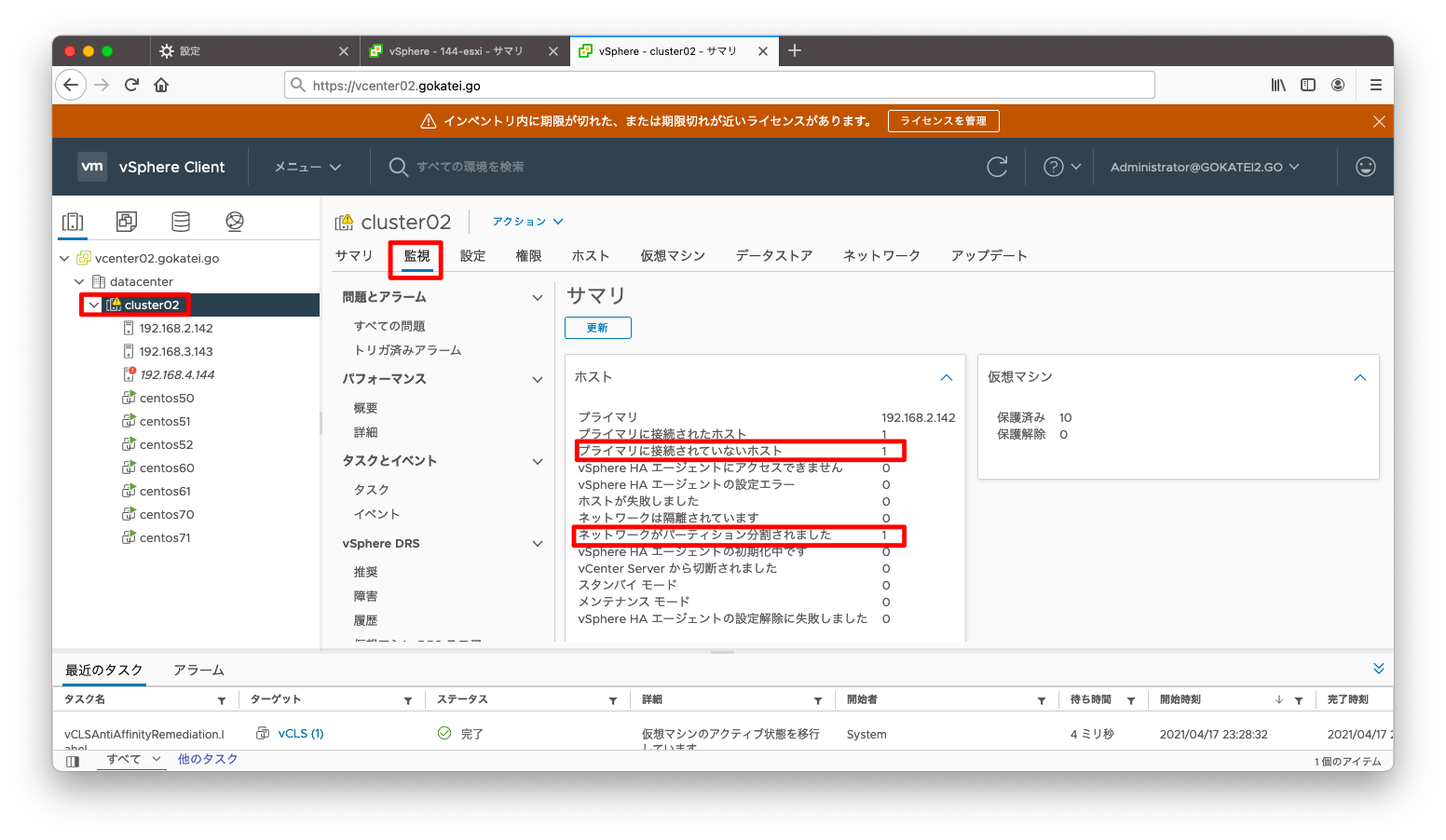
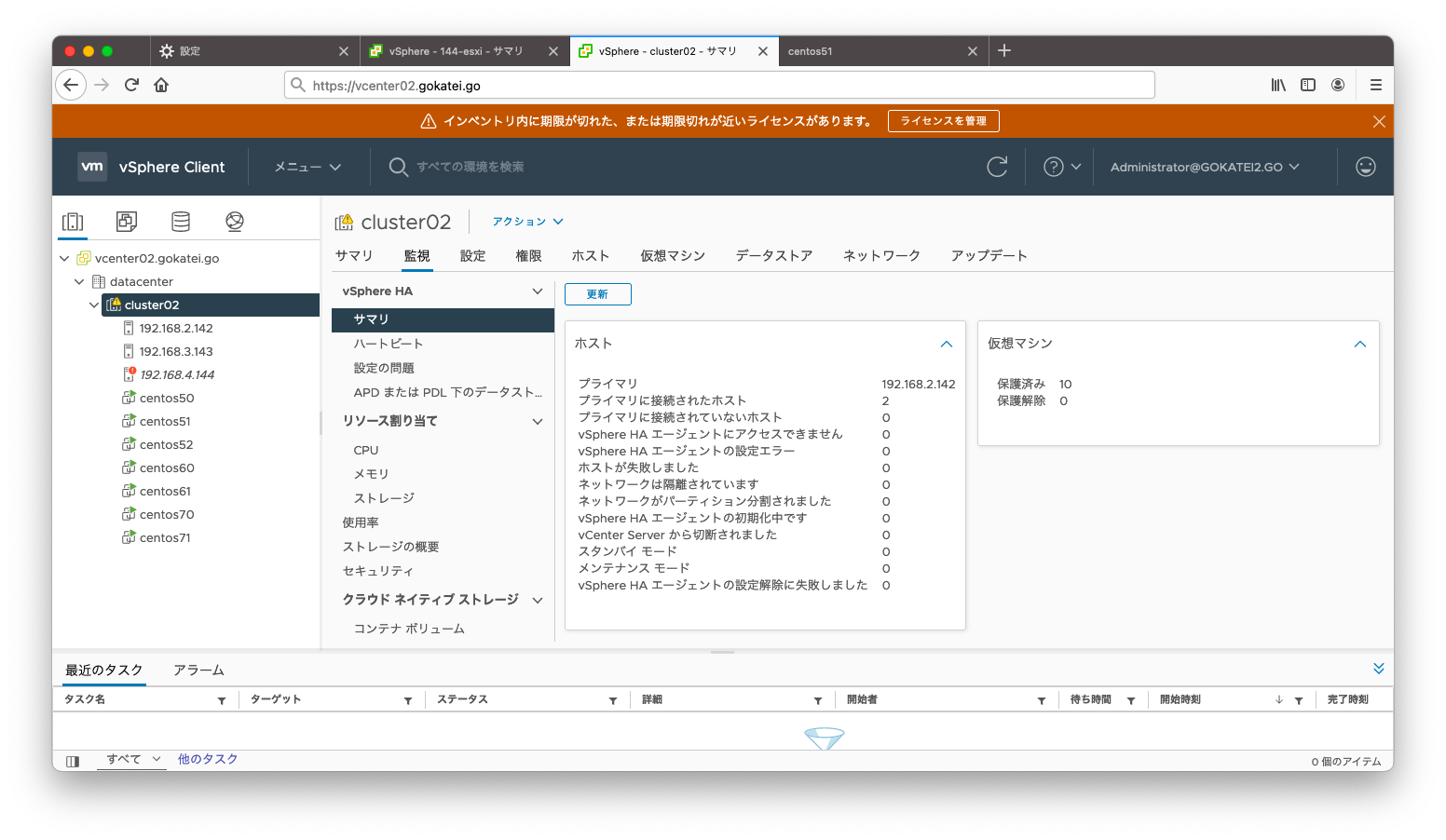
「クラスタ」「監視」「vSphere HA / サマリ」を見ると、どのような障害が何件発生しているかを確認できます。下記スクリーンショットならば「パーティション」の状態が1件あるのが分かります。

ESXiとESXi間の通信障害
vSphere HAはプリマリサーバからセカンダリサーバへの監視をしています。vCenterから全てのESXiへの疎通は可能であるものの、プライマリサーバのESXiからセカンダリサーバのESXiへの疎通が出来ない状況を考えます。構成図で示すと以下の通りです。

「vCenterからESXiへ」と「プライマリからセカンダリへ」は物理的に同一の通信経路になる事が多いでしょう。ですので、物理的な障害では滅多に起きない現象です。もし発生しうるとすれば、ファイアウォールの設定誤り等で発生しえます。もし、このような現象を擬似的に起こしたいならば、ファイアウォールルールなどで通信を遮断してみましょう。
例えば、ルータ「NEC IX」を用いて擬似的に障害を起こすならば以下のような設定になります。
以下は検証環境に応じて適宜変更ください。おそらく、勤務先で実験するような方は、CiscoやJuniperの高価な機器を使う方が多いでしょう
ip access-list acl_vlan0002 deny ip src 192.168.2.142/32 dest 192.168.4.144/32 ip access-list acl_vlan0002 permit ip src any dest any ! interface GigaEthernet1.2 ip filter acl_vlan0002 10 in
「すべての問題」を確認すると、「ホスト障害の可能性が検出されました」または「異なるネットワークパーティション内にあることが検出されました」とのメッセージが出力されています。
もしかしたら、障害の状態が時事刻々と変わる可能性もあるかもしれないので、「イベント」も併せて参照しましょう。
この辺りは検証不足で自信が持てず申し訳ございません。私の環境では「ホスト障害の可能性が検出されました」または「異なるネットワークパーティション内にあることが検出されました」の状態が繰り返し変更される状況になっています。この挙動が仕様か設定誤りかは確証が持てていません。
「クラスタ」「監視」「vSphere HA / サマリ」を見ると、どのような障害が何件発生しているかを確認できます。下記スクリーンショットならば「パーティション」の状態が1件あるのが分かります。
vCenterとESXi間、ESXiとESXi間の通信障害 かつ 隔離アドレスへの疎通不能
vCenterとESXi間、ESXiとESXi間の通信障害が起き、さらに隔離アドレスへの疎通不能となる状況を確認します。構成図で示すと以下の通りです。
「隔離アドレス」はデフォルト設定ではデフォルトゲートウェイになります。「隔離アドレス」にすらpingが届かないという事は、そのESXiホストは全くの孤立状態という事を意味します。「隔離アドレス」は日本語では分かりづらいですが、英語表記では「isolation address」です。正式用語は「隔離アドレス」ですが「孤立アドレス」と訳した方がイメージしやすいでしょう。
障害発生方法は色々ありますが、Nested ESXi環境ならば、ホストOS側のネットワークを切断する事で障害を再現させる事ができます。
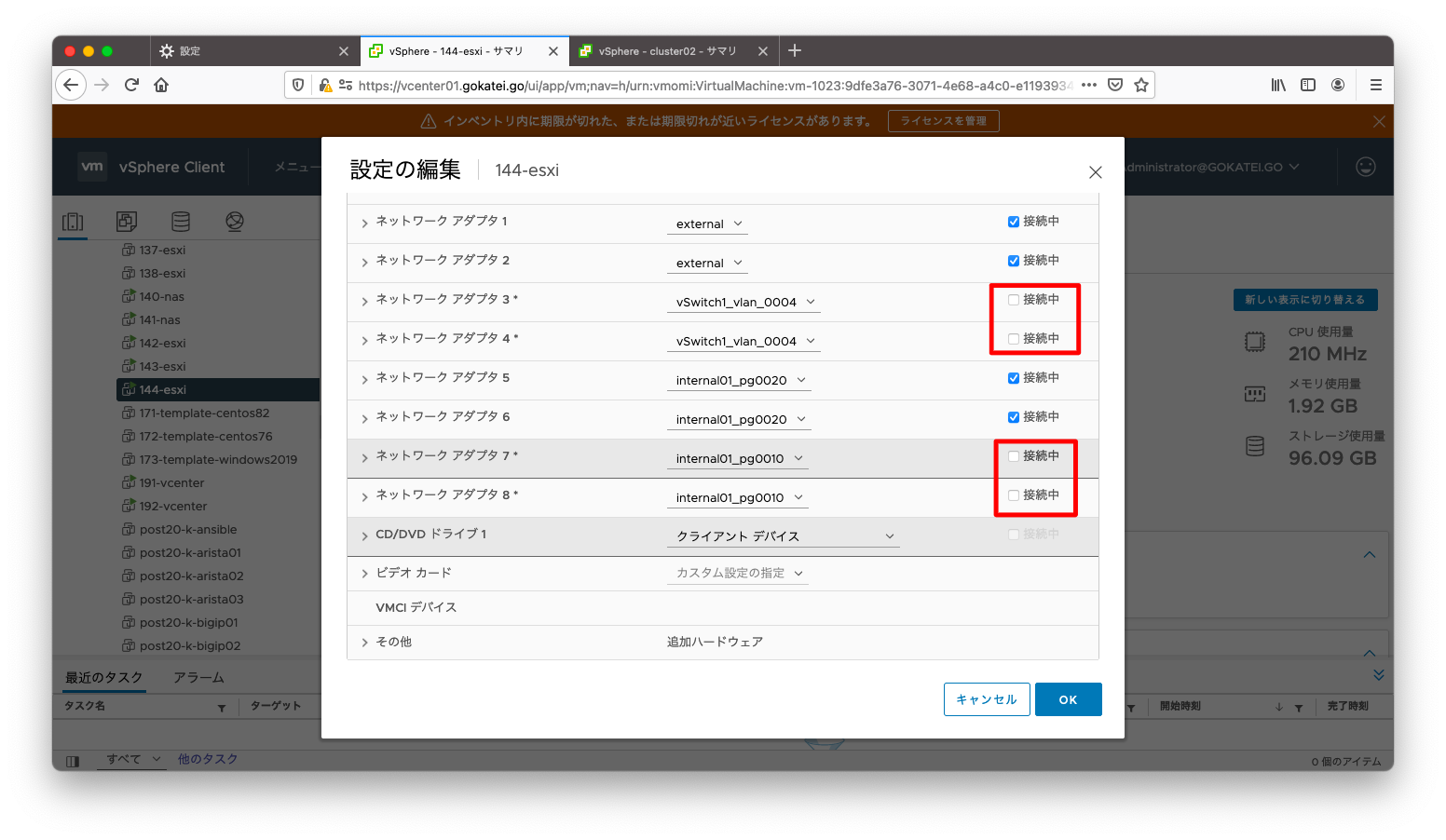
「すべての問題」を確認すると、「ホスト障害の可能性が検出されました」または「ネットワーク隔離されていることが検出されました」とのメッセージが出力されています。
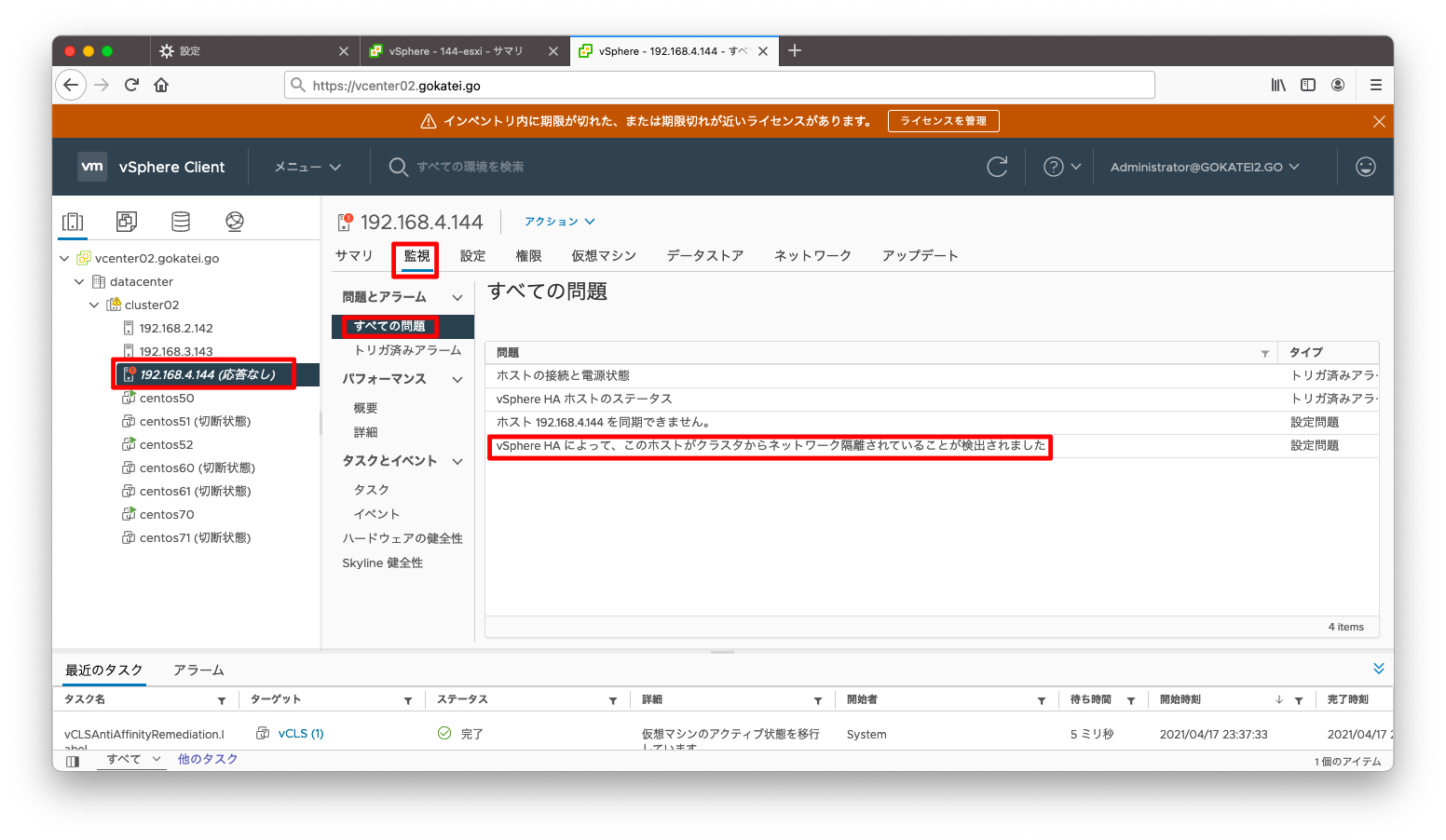
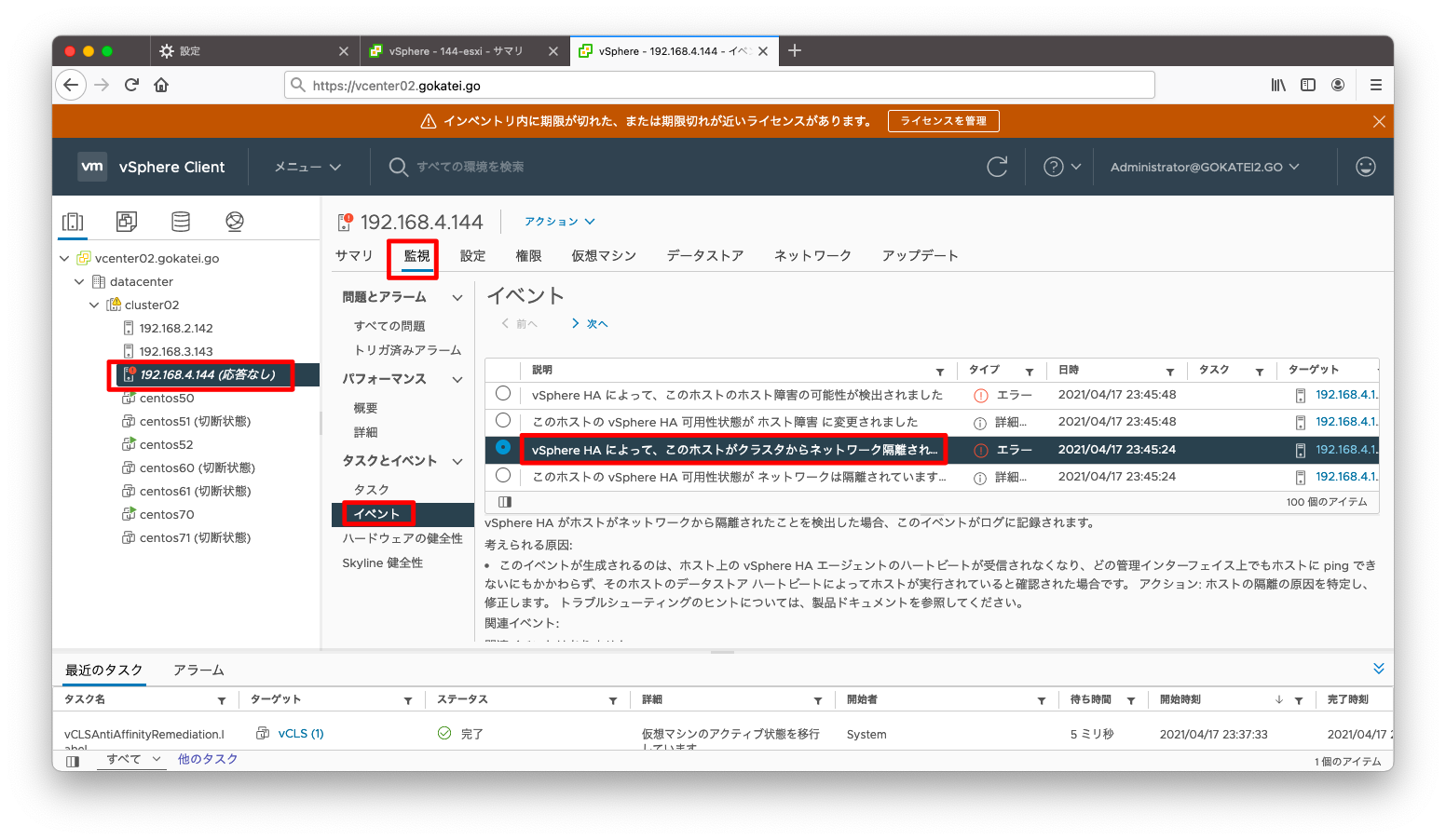
もしかしたら、障害の状態が時事刻々と変わる可能性もあるかもしれないので、「イベント」も併せて参照しましょう。
この辺りは検証不足で自信が持てず申し訳ございません。私の環境では「ホスト障害の可能性が検出されました」または「ネットワーク隔離されていることが検出されました」の状態が繰り返し変更される状況になっています。この挙動が仕様か設定誤りかは確証が持てていません。
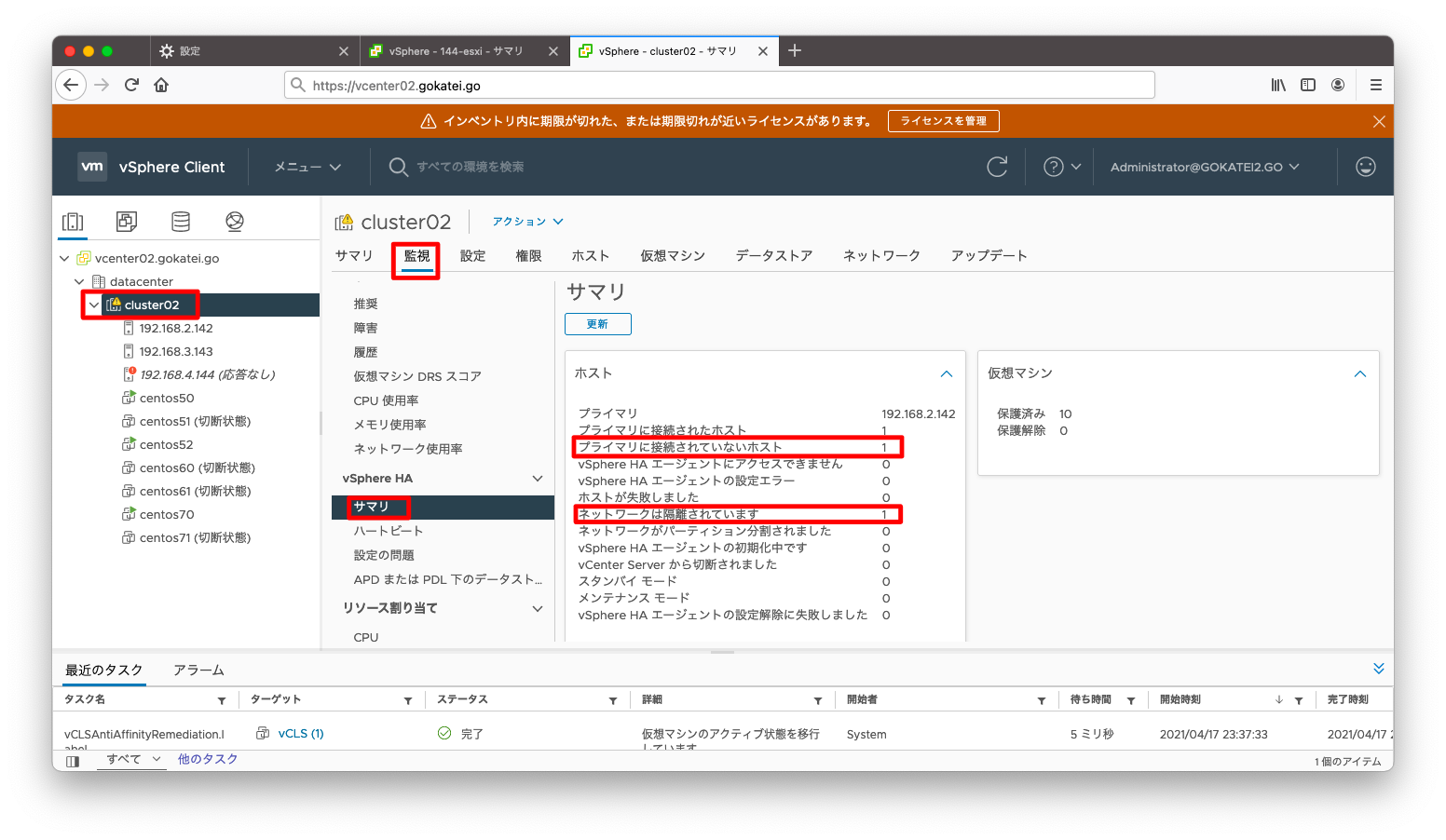
「クラスタ」「監視」「vSphere HA / サマリ」を見ると、どのような障害が何件発生しているかを確認できます。下記スクリーンショットならば「隔離されています」の状態が1件あるのが分かります。
ハートビートデータストアの障害
vCenterとESXi間だけでなく、隔離アドレスもハートビートデータストアも疎通不能になる状態を再現させます。構成図で表すと以下の通りです。
障害発生方法は色々ありますが、Nested ESXi環境ならば、ホストOS側のネットワークを切断する事で障害を再現させる事ができます。
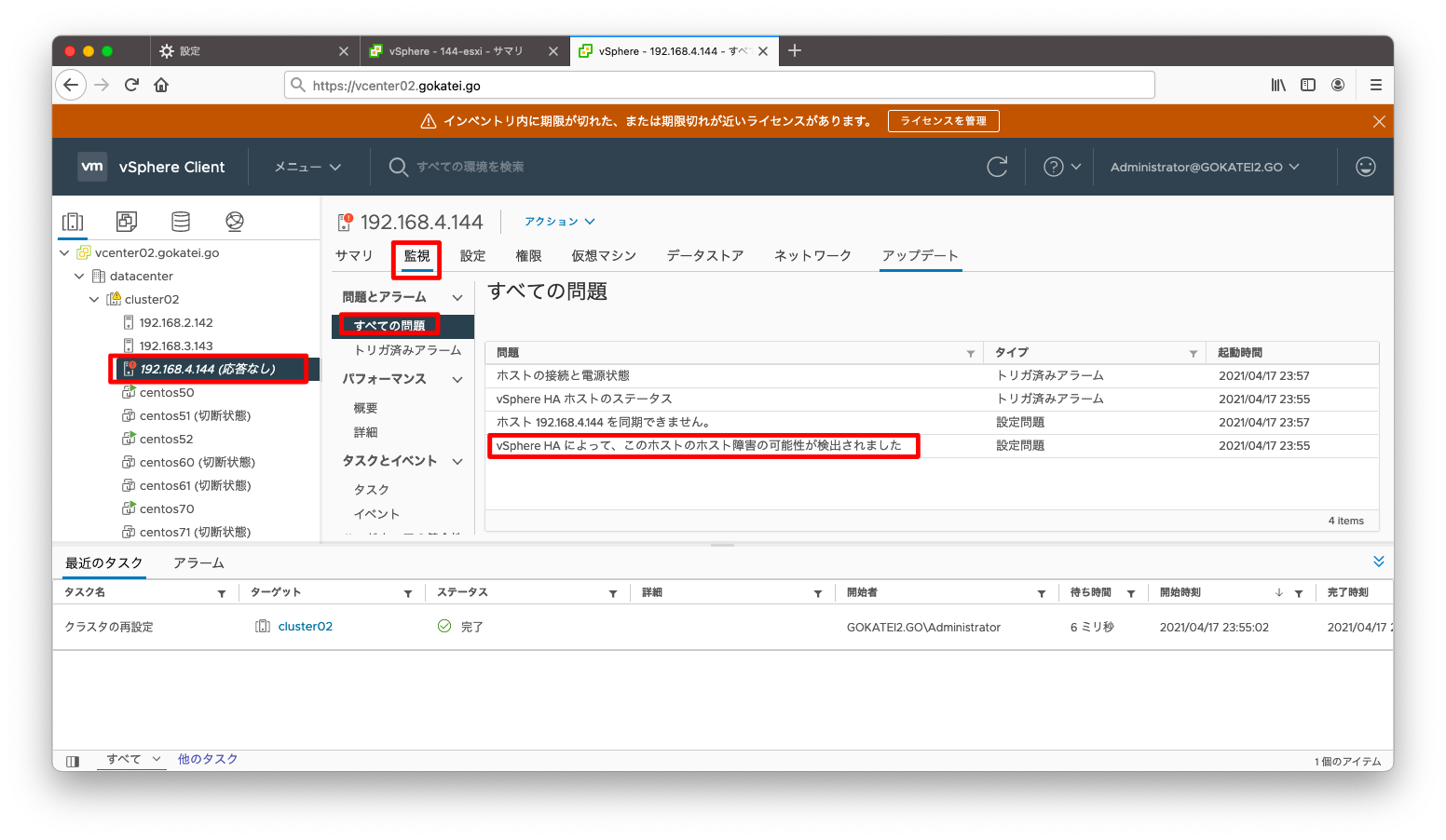
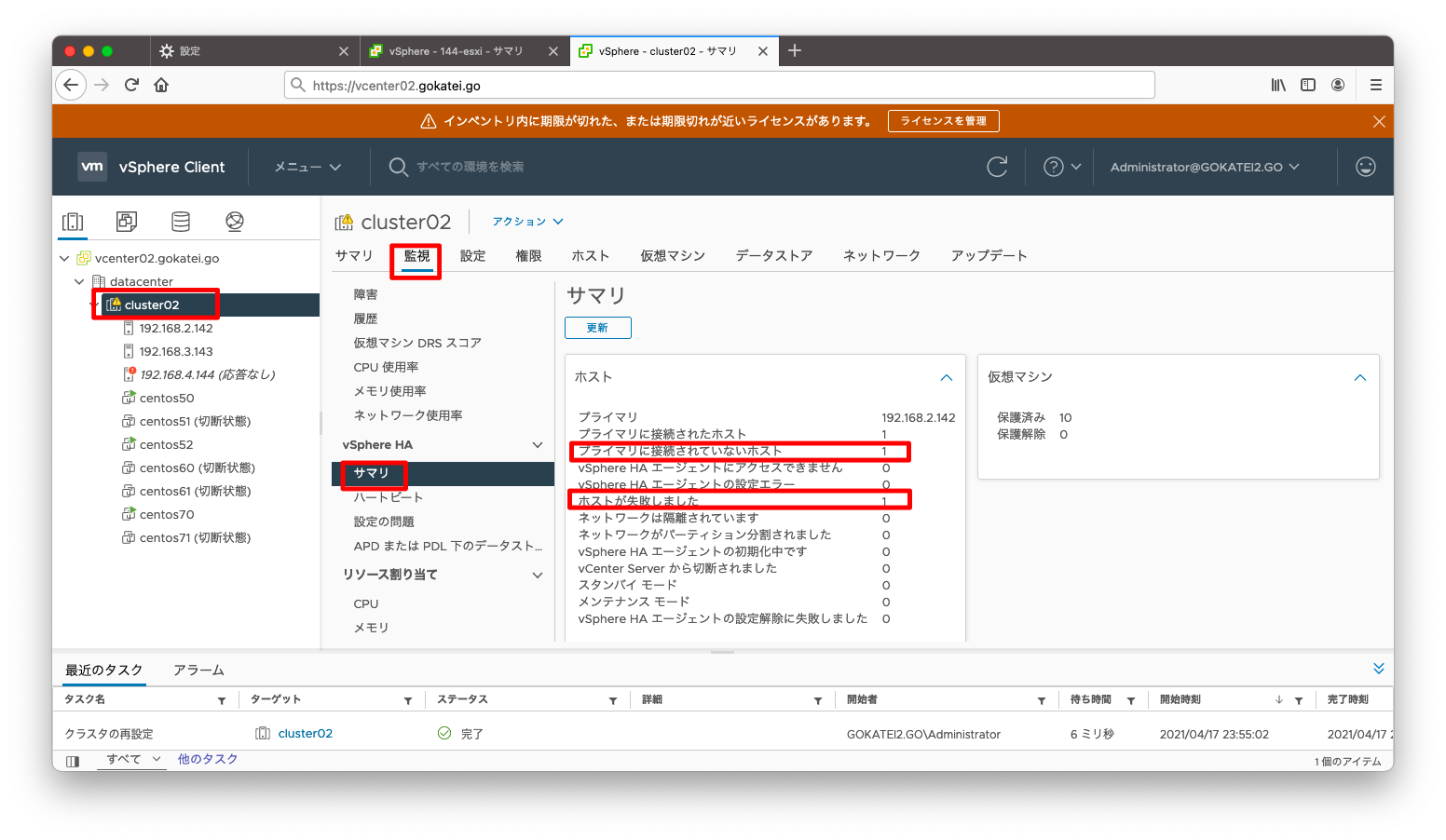
「すべての問題」を確認すると、「ホスト障害の可能性が検出されました」とのメッセージが出力されています。この場合は、「パーティション」でも「隔離」でもありません。
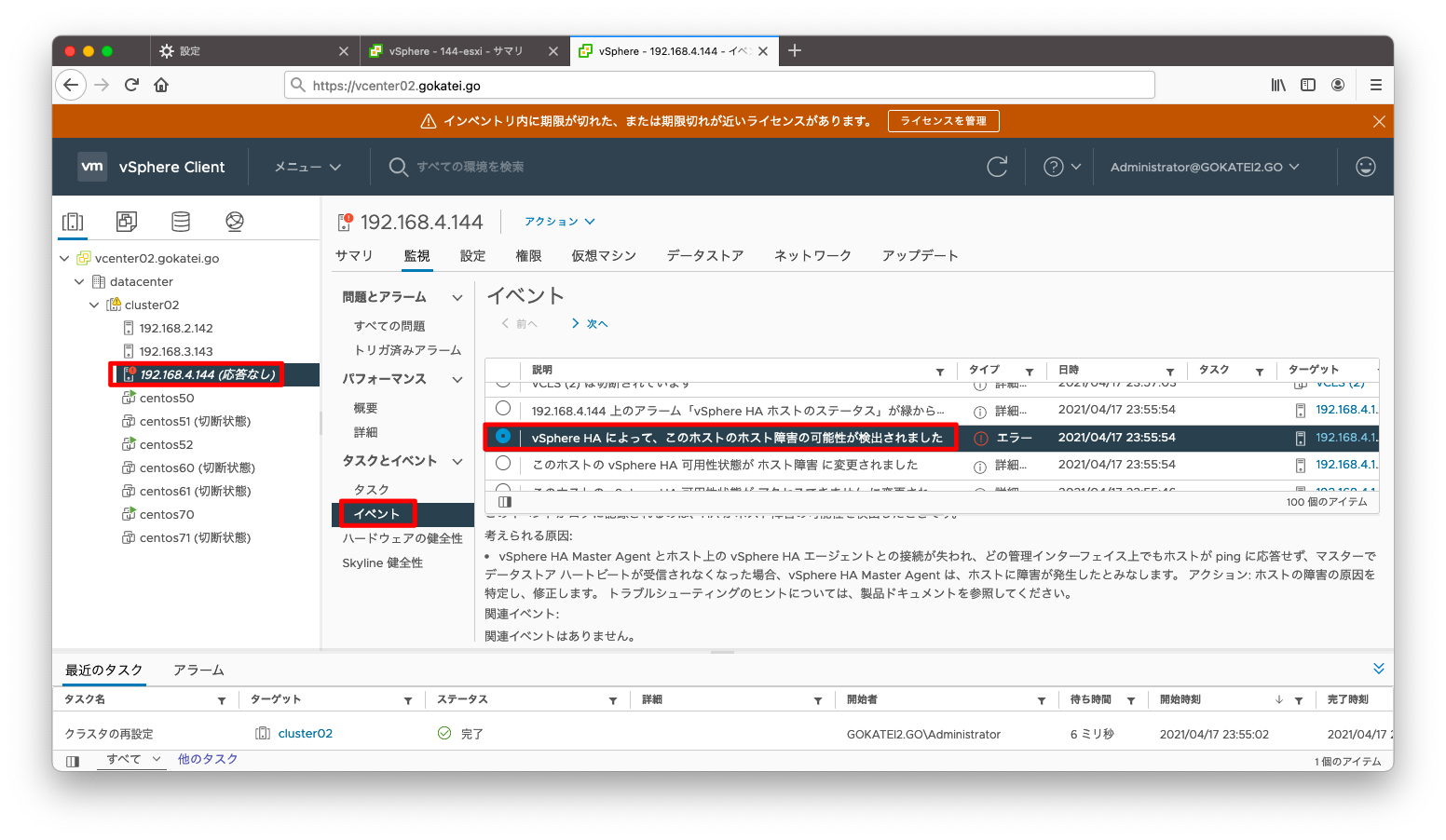
「イベント」を見ると、「ホスト障害の可能性が検出されました」とのメッセージのみです。
「クラスタ」「監視」「vSphere HA / サマリ」を見ると、どのような障害が何件発生しているかを確認できます。下記スクリーンショットならば「ホストが失敗しました」の状態が1件あるのが分かります。
APD(All Path Down)
vSphere HAにはAPD(All Path Down)と呼ばれる障害のパターンがあります。仮想マシンのデータを格納するストレージへの全ての通信経路が切断される場合の障害をAPDと呼びます。商用環境では、複数のFCケーブルに障害が起きるようなパターンです。
今回は家庭でもテストできるような廉価構成ですので、NFS上に仮想マシンのデータを格納しています。このデータへの通信経路について障害を発生させます。構成図で表すと以下の通りです。

障害発生方法は色々ありますが、Nested ESXi環境ならば、ホストOS側のネットワークを切断する事で障害を再現させる事ができます。
障害発生直後は、「すべての問題」を確認しても、「ホスト障害の可能性が検出されました」などのメッセージは見当たりません。
「クラスタ」「監視」「vSphere HA / サマリ」を見ても障害は見当たりません。
障害発生から300秒程度経過すると、イベントに「APD(All Path Down)のタイムアウト」とのメッセージが出力され、vSphere HAがAPDを検出して事が分かります。
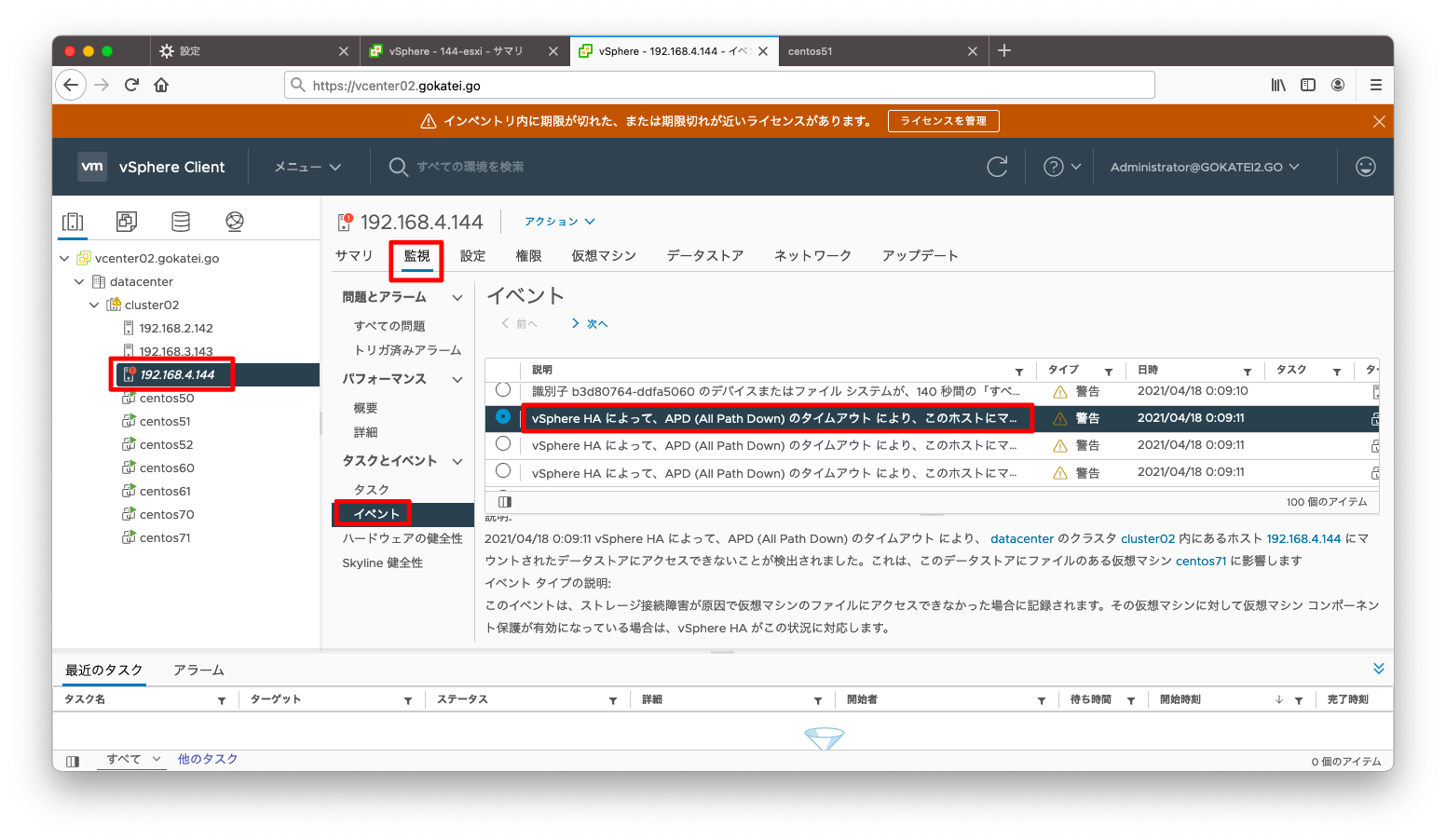
されに15分程度経過すると、APDの検出により障害が発生したESXiホストから別ホストへのvMotionが実施され、障害の復旧がなされた事が分かります。
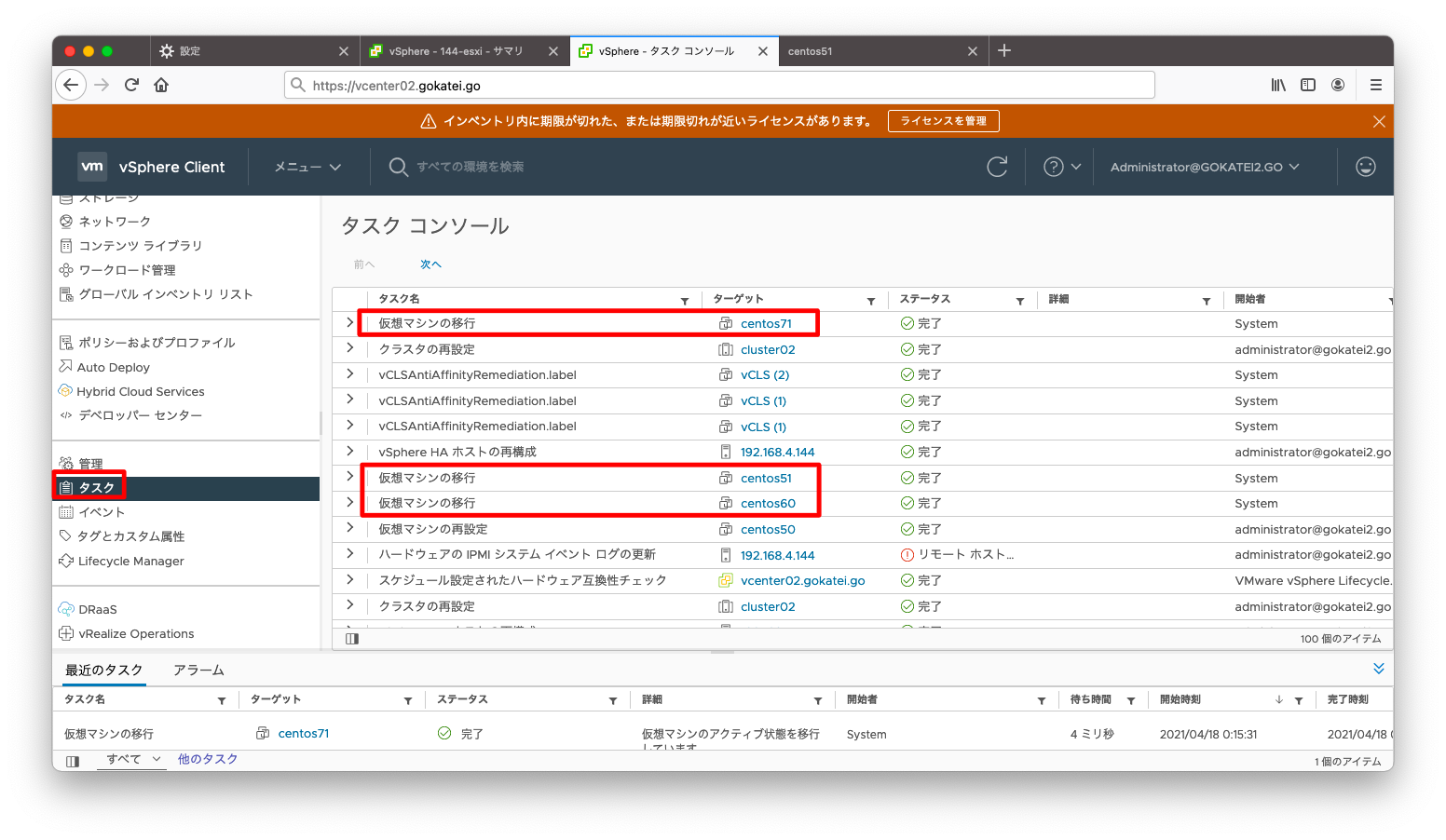
障害が発生したホストには仮想マシンが1台も乗ってない事を確認します。
vSphere HAの設定
障害および対応
vSphere HAは障害が起きた時の挙動を定義する事ができます。例えば、ストーレジへの疎通不能は再起動で、隔離アドレスへのそ普通不能は対応なしのような定義が可能です。以下に、vSphere HAで対応可能な障害発生パターンを書きます。
以下は実験に基づいた当サイトの独自解釈です。公式の見解は「障害への応答の構成」を参照ください。公式(公開されている範囲の情報では)はここまで踏み込んで書いてない。
| 監視方法 | 意味(当サイトの解釈) |
|---|---|
| ホストの障害対応 | ESXiへの完全な疎通不能 |
| ホスト隔離への対応 | 隔離アドレスへ疎通不能となる状態(ESXiの障害の状態が「ホストの失敗」か「隔離されています」かではなく、隔離アドレスがicmp応答するかどうかで判定する) |
| PDL(永続的なデバイス損失)状態のデータストア | データストアに疎通が可能であるものの、vmdkなどのファイルが損失している状態 |
| APL状態のデータストア | vmdkなどの仮想マシンを構成するデータストアへの疎通不能(ハートビートデータストアとは関係ない) |
| 仮想マシンの監視 | VMware Toolsによる監視 |
デフォルト設定では隔離アドレスへの疎通不能はvMotionされず仮想マシンはそのまま動き続けます。もし、このような設定が不都合ならば、デフォルト設定を変更する事もできます。
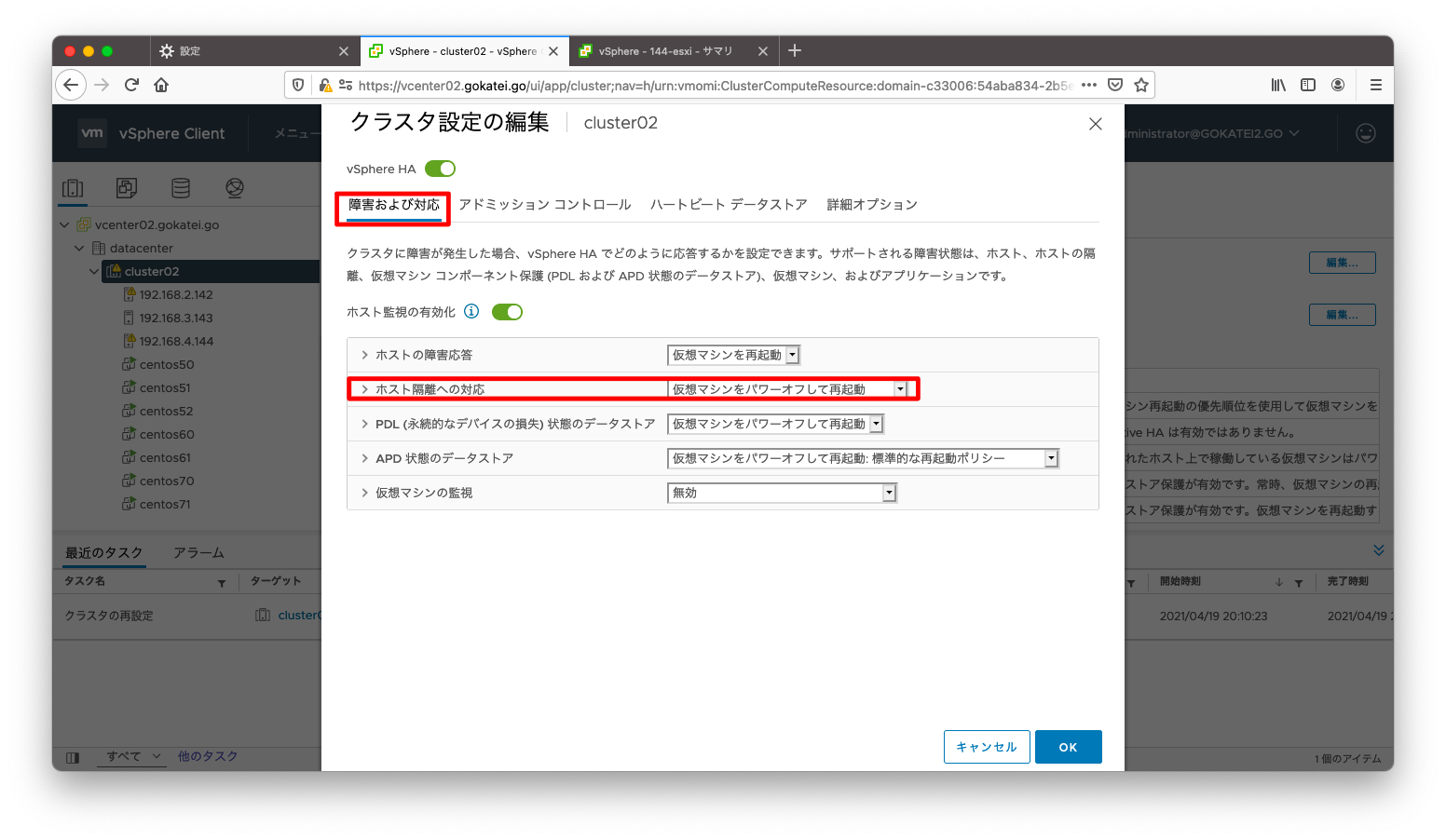
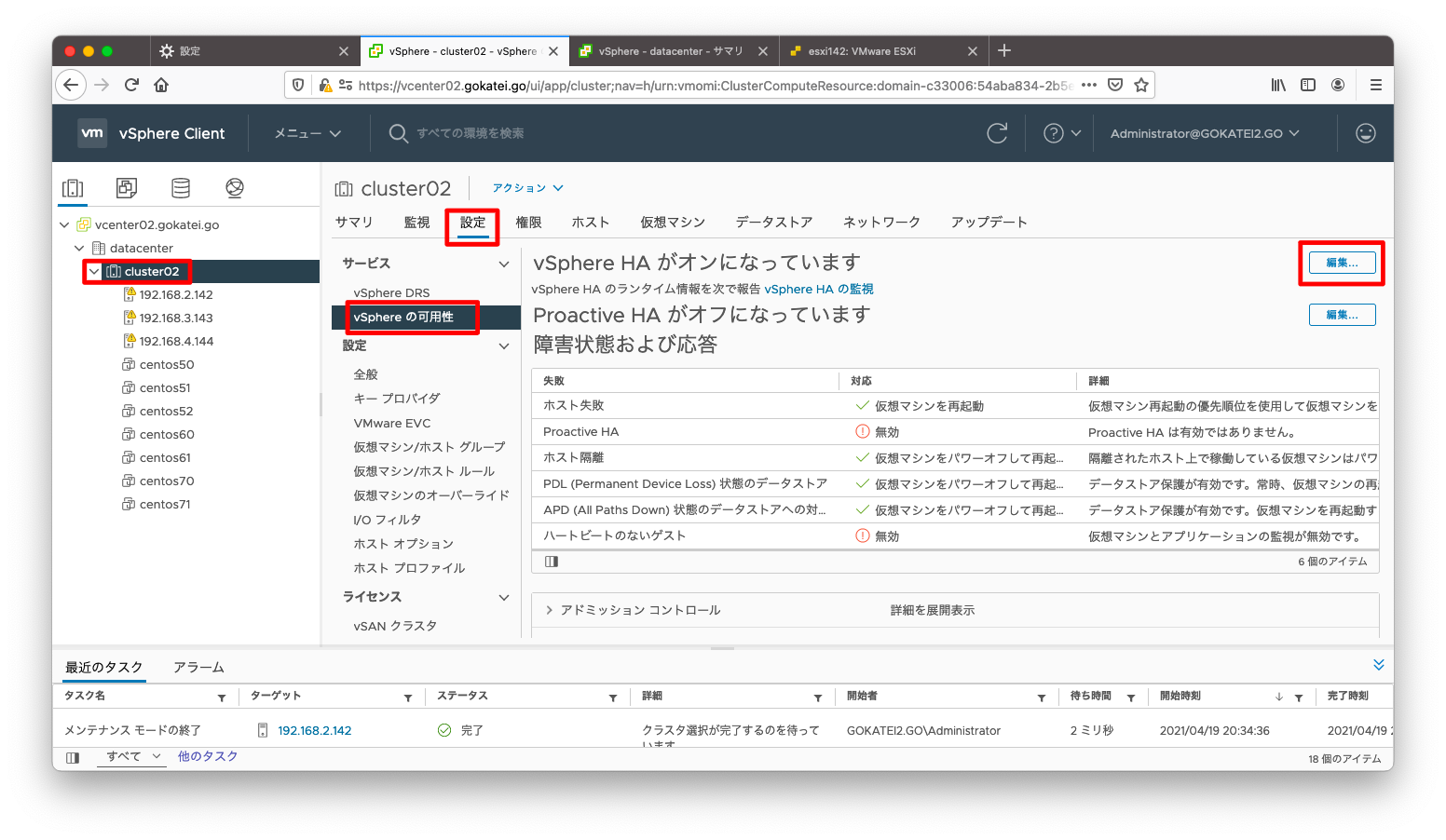
「クラスタ名」「設定」「vSphereの可用性」「編集」の順に押下します。
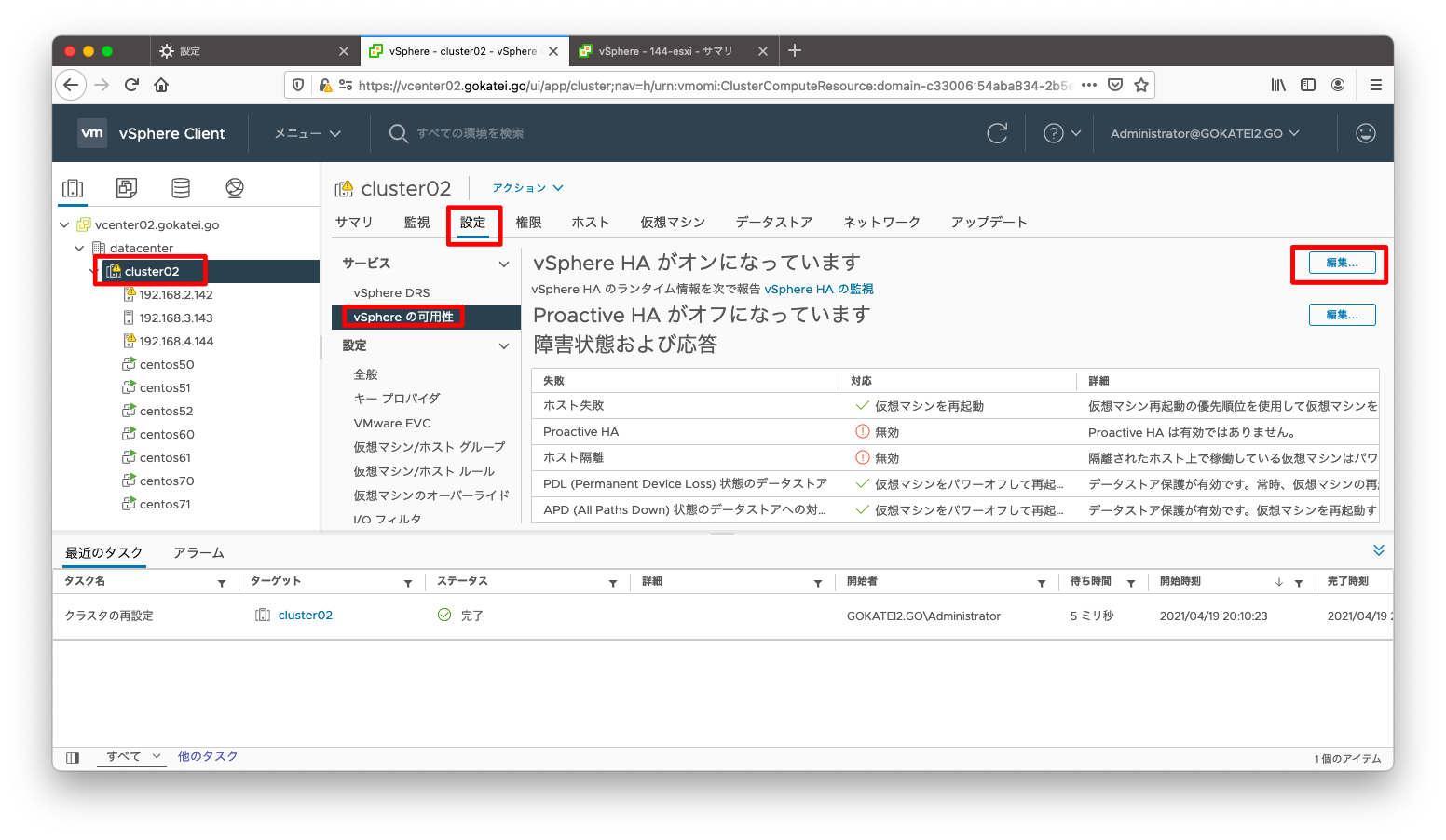
「障害および対応」タブで「ホスト隔離への対応」を「仮想マシンをパワーオフして再起動」を選びます。
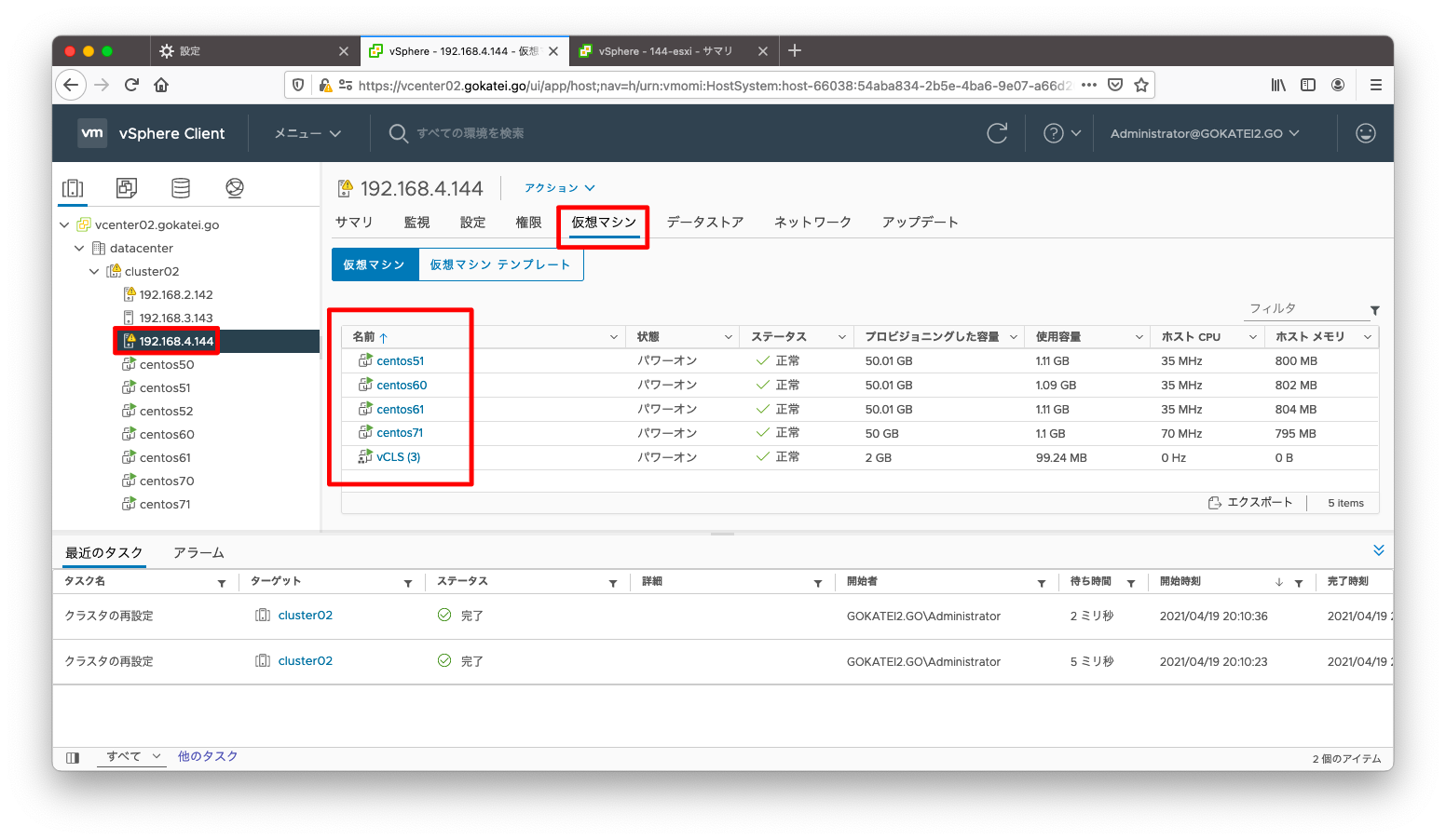
それでは障害発生時の挙動を確認します。まず、障害発生前にESXiホスト上に仮想マシンが格納されている事を確認します。
隔離アドレスへ疎通不能となる障害を再現させます。
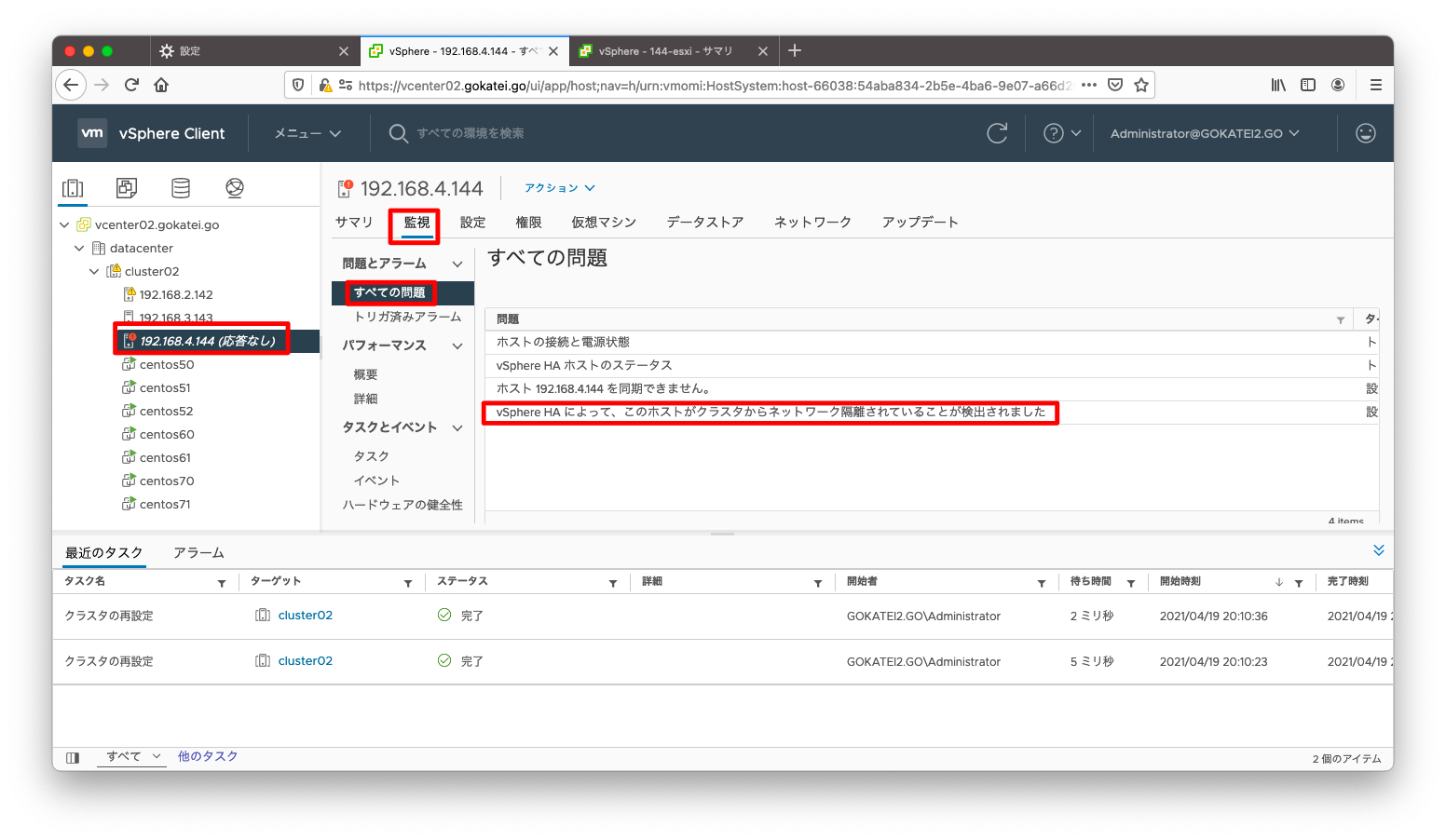
隔離アドレスへ到達不能になった事を確認します。
仮想マシンがvMotionされた事を確認します。
ハートビートデータストア 警告メッセージの抑制
ハートビートデータストアは有効活用すれば対障害制を高める設計のひとつになりますが、予算制約など場合によっては不要なアラートを発生させるだけになってしまうこともあります。ヴイエムウェア社はハートビートデータストアは2つ以上と主張しており、最低ハートビートデータストアの設定は2から5までの設定しか許容されません。
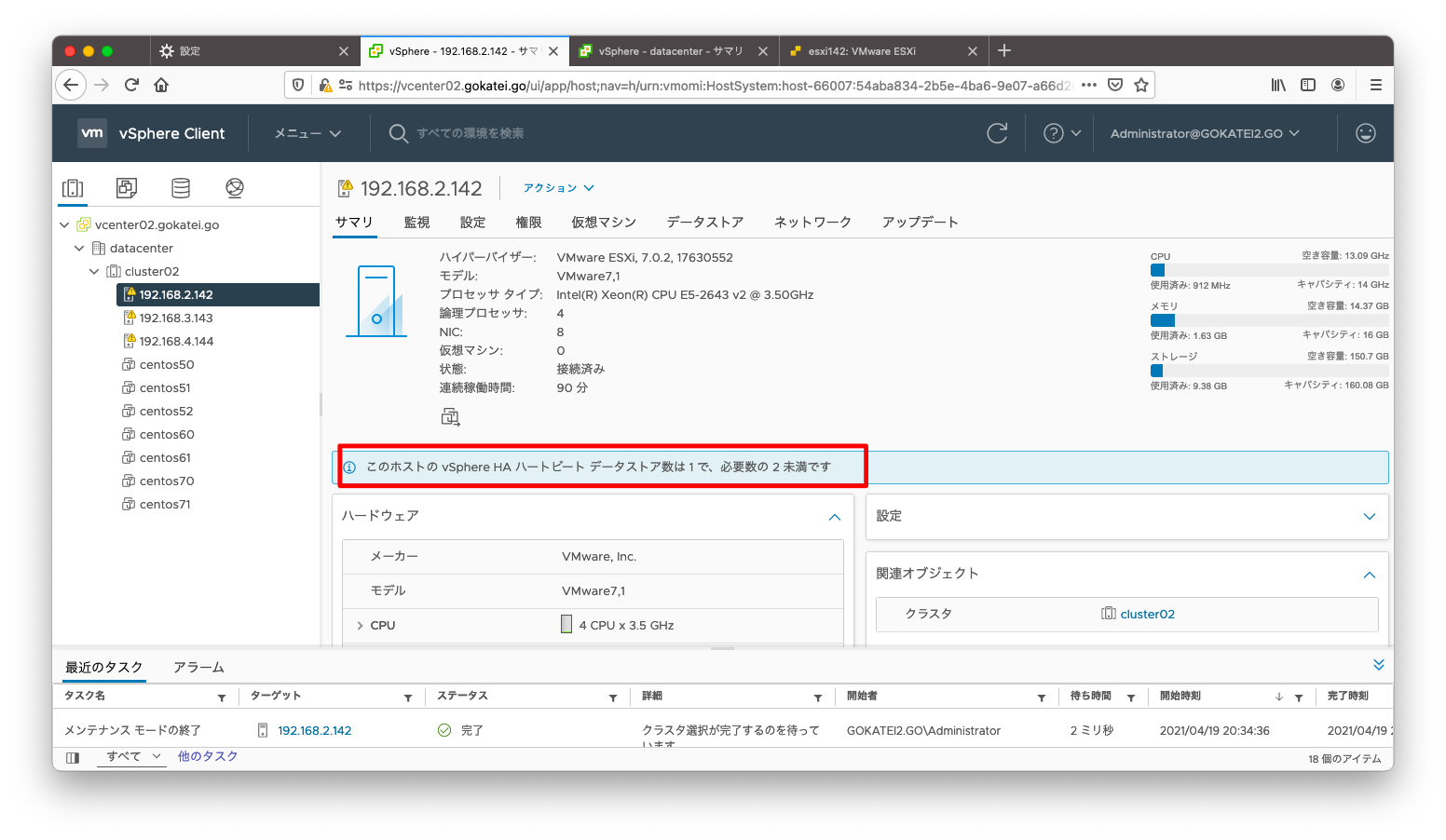
データストアが1つしかない環境では以下のような警告メッセージが出力されます。
このホストのvSphere HAハートビートデータストア数は1で、必要数の2未満です
この警告を抑制する手順を記します。「クラスタ名」「設定」「vSphereの可用性」「編集」の順に押下します。
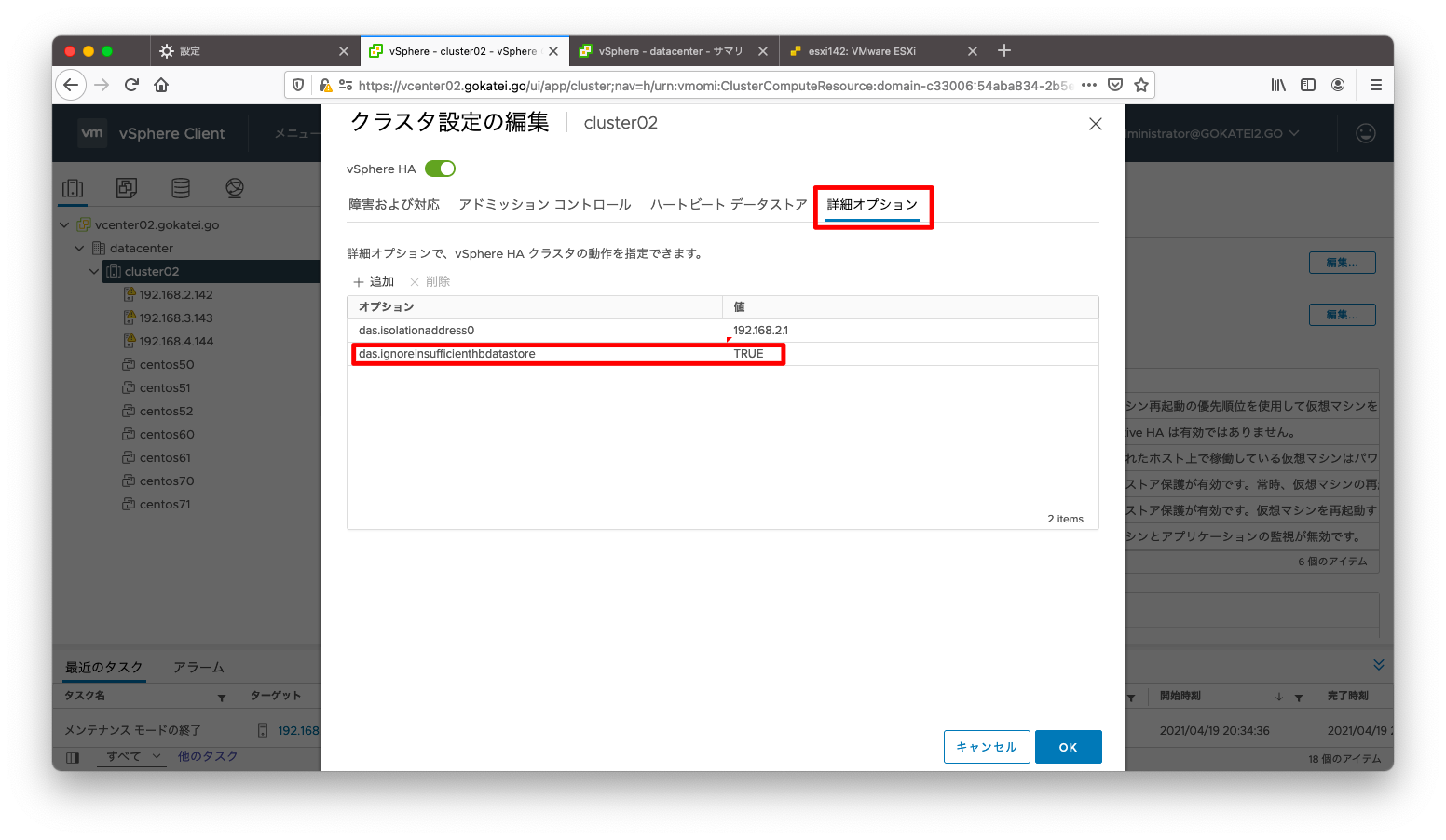
「詳細オプション」タブで、das.ignoreinsufficienthbdatastoreにTRUEを指定します。
もし、設定変更に時間がかかるようならば、「vSphere HA用に再設定」を試みましょう。
公式見解「vSphere HA の詳細オプション
」では再設定が必要との記述はありません
警告メッセージが抑制された事を確認します。
ハートビートデータストアの設定
もし、ハートビートデータストアの有効活用できるような潤沢な予算があるならば、ハートビートデータストアを設定しましょう。
ハートビートデータストアを明示指定するには、「クラスタ名」「設定」「vSphereの可用性」「編集」の順に押下します。

「ハートビートデータストア」タブでハートビートデータストアの指定が可能です。全部を明示指定することもできれば、自動設定にすることもできます。
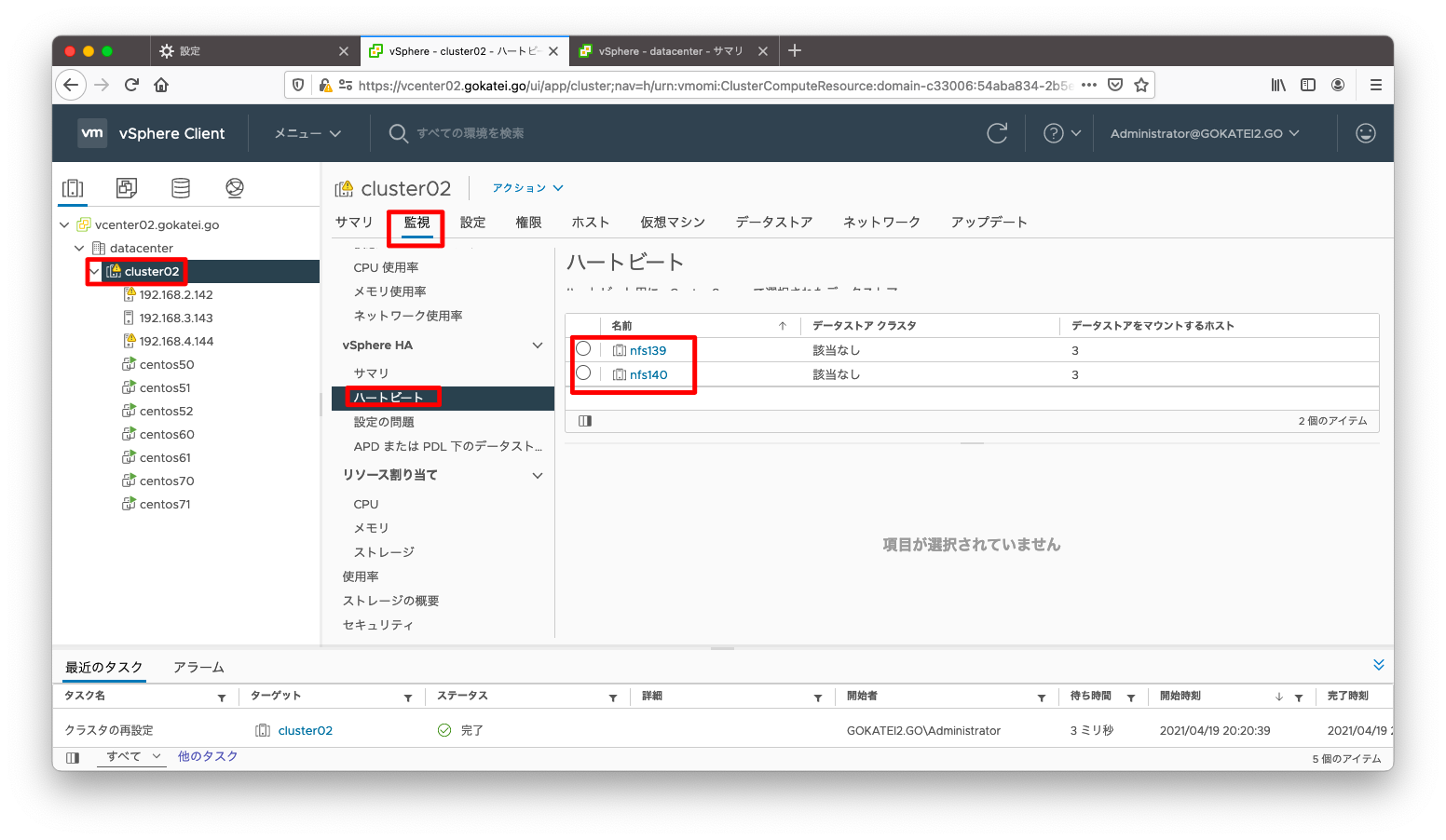
自動設定にした場合は、「クラスタ名」「監視」「ハートビート」から何がハートビートデータストアに設定されたかを確認する事ができます。
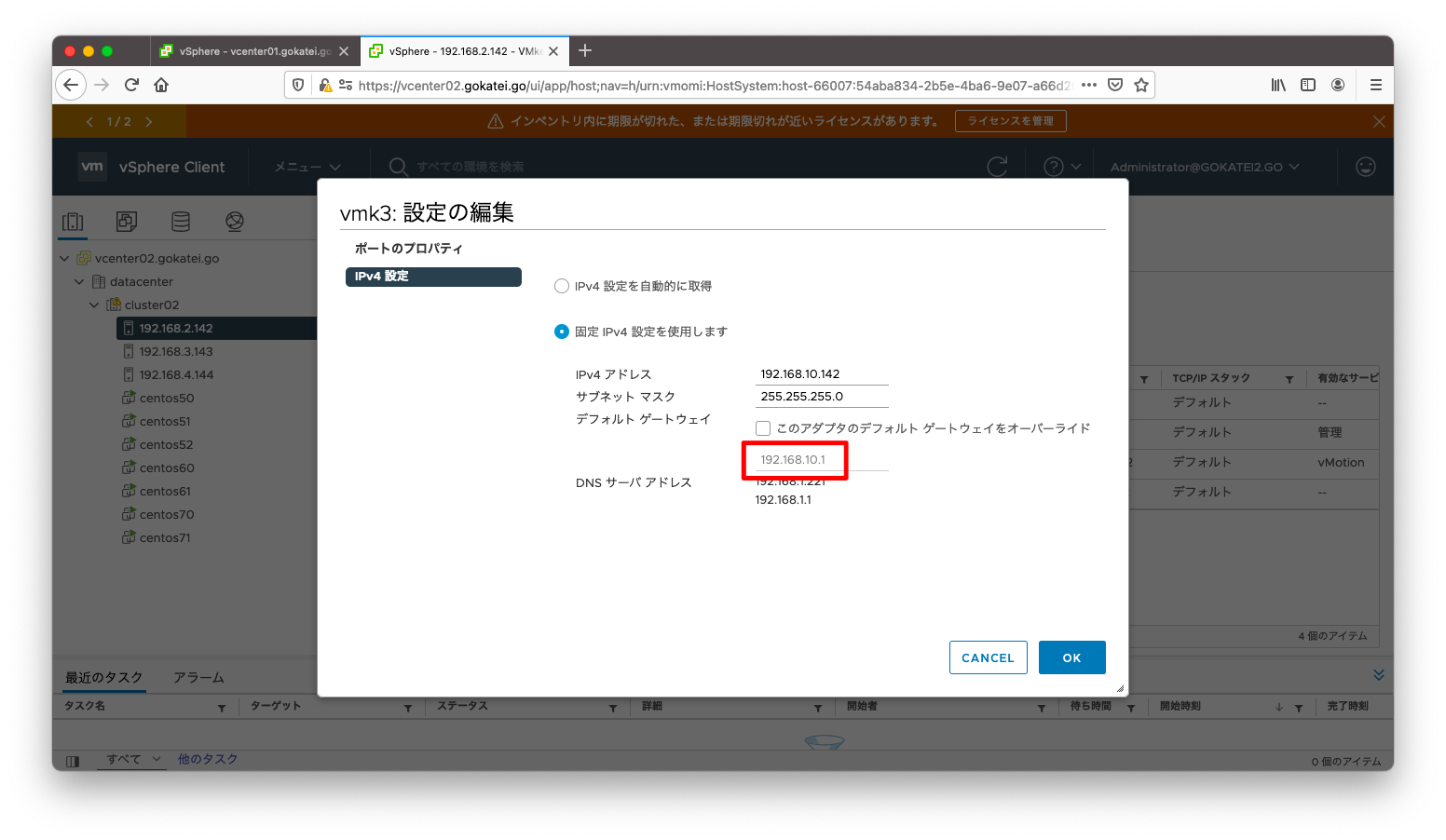
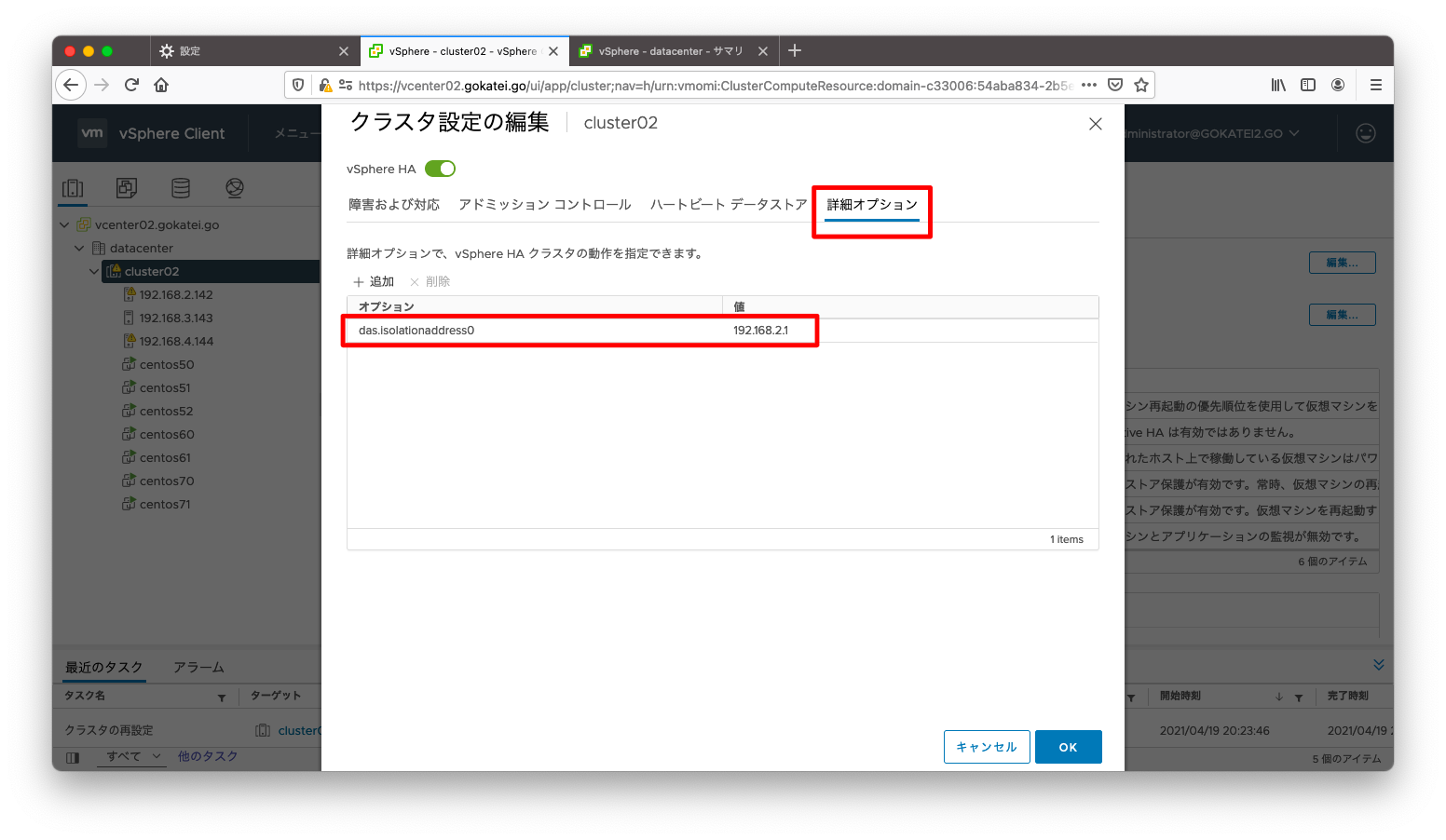
隔離アドレスの変更
デフォルト設定では隔離アドレスはデフォルトゲートウェイが設定されますが、これを設定変更する事もできます。
隔離アドレスを設定変更するには、「クラスタ名」「設定」「vSphereの可用性」「編集」の順に押下します。
「詳細オプション」タブに移動し、das.isolationaddress0に隔離アドレスを入力します。
das.isolationaddress0, das.isolationaddress1, … das.isolationaddress9までの計10個の隔離アドレスが指定可能です。
設定を反映するには「vSphere HA用に再設定」が必要です